Just wanted to know that why does the training loss increase abruptly when i increase
the epochs even
though it was performing much better just before the new learn.fit() line? Given that I don’t overfit at all
The way I think about it: smaller images allows the model to first learn the overall structure, the big picture. As we increase the size, it starts filling the details within the structure.
This might be easier to do then trying to infer the big picture from a detailed view. And getting the big picture right is what I suppose helps with generalization.
But this is just my intuition. Makes sense to me that we might want our model first to learn shapes and only then the texture. But would take this reasoning with a grain of salt
The main consideration here is whether this layered approach produces better results than training with full image size from start.
Yeah that sounds around right. But we don’t have rigorous experiments yet to know whether this gives better accuracy in the end, or speeds up time to get to some accuracy level, or whether it doesn’t really help at all - it’s something that some of the part 2 students are planning experiments for at the moment.
Thanks for the explanation. I assume this would only make sense if the image is being resize/rescale when setting to different “sz” values. If it’s just doing random cropping by “sz*sz”, it would only be learning part of the image instead of learning the big picture. I’m going to start digging in the fastai transforms source code later.
P.S. Is there a specific reason setting the padding to “sz//8” ?
Yes! This is the augmentation (plus random horizontal flipping) that was used in many papers that train on CIFAR10. For instance, the Resnet paper uses this data augmentation.
I played around with this some time ago and this is what the augmented images look like:
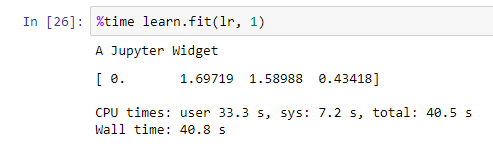
Any insights about the massive differences in learning rates here, on the first learn.fit of the cifar10 notebook?
Whatever Jeremy is running is taking 40.8 seconds to run, with a batch size of 128. My old GTX 650 Ti with only 2GB RAM, and with batch size reduced to 32 to cope, takes almost 15 minutes!
Of course I intend to upgrade when I can, but what would I expect to get if I chose a 1080 Ti - would it be anywhere near what Jeremy shows I wonder?
Thanks Jeremy - that’s encouraging to know! My current system can take a 1070 Ti without any further hardware upgrades - how much slower do you think that would be?
I tried to implement the entire process from scratch with pytorch. Using SNet, the best accuracy I could get is only around 93.2%. Is there any tricks in the fastai library that could push the result even more?
My training process has:
Data augmentation (Random flip, Random Crop and padding)
Weight decay, Momentum
SGDR - implemented using lambdaLR class from pytorch, bad idea but it worked
Snapshot Ensemble - helped a little bit with the results that I submitted to kaggle
Learner class - poor man’s version just to make it easier to change the data size
What else should I be doing? Here’s my notebook. I would really appreciate some input.
Another note, it seems that whether I use differential data size training(is there a term for this technique?) or not, the end results are similar to ones that I trained with 32x32 right from the start(around 93.2%). However, it seems to better at maintaining a better balance between train loss and val loss at early stages. Is there anyway to take advantage of this?
I found the senet154 has been added to fastai library, but i don’t konw how to use it.
the original method is not available:
arch = senet154
learn = ConvLearner.pretrained(arch, data)
what should i do?
thanks!
Hi ! Really nice work, I am a bit late and I don’t know if the comment will be accurate since the Library evolved a lot since then but now the default loss function for training given by ImageDataBunch is FlattenedLoss of CrossEntropyLoss() which is a function of Pytorch CrossEntropyLoss that, according to the doc
This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class.
so I don’t think the LogSoftmax() activation at the end of your model is necessary because will have 2 activations function, again I don’t know if this is relevant to the previous versions of FastAi but it could maybe help other people with this issue today

 This is the augmentation (plus random horizontal flipping) that was used in many papers that train on CIFAR10. For instance, the
This is the augmentation (plus random horizontal flipping) that was used in many papers that train on CIFAR10. For instance, the