Great stuff @rudy! It was a really nice collaboration project and a fun way to integrate different disciplines.
Appreciate the feedback from everyone!
Great stuff @rudy! It was a really nice collaboration project and a fun way to integrate different disciplines.
Appreciate the feedback from everyone!
Kaggle Planet Competition: How to land in top 4%
I was able to land in top 4% in Kaggle Planet competition. I have written a blog post about it. You can read it here.
Let me know your thoughts about it.
Not exactly DL related, but it’s really cool to be a volunteer in the community. We’re following Fast AI, CS231n, 224n, UCL-RL courses.
Fast AI had already introduced me to all the amazing advanced DL people on the community. AI Saturdays, is extending that by Meetups. It’s amazing to be in active community with people from everywhere 
This thread will never die 
I just published a take on what it means to do machine learning efficiently.
Go on thread! Have a little bit of a boost
This is literally Lesson #6 notebook with a slight twist and a few additional words. Whenever I write something, I honestly can’t tell if it is any good or not. I even have a hard time figuring out if I didn’t insult anyone.
With this notebook, it might not be interesting to anyone. But frankly I will take the silence with open arms if that is the case I am more concerned that maybe basing this that closely off @jeremy’s work (lesson #6 notebook and the visualizations) might not be kind to him. Not that Jeremy has ever given me any reasons to think that this might be the case. But if that is the case I would really, really like to know so that I could fix the mistake.
Anyhow, I think taking a look at this might be quite useful to people doing the course. It has certainly been very helpful for me to work on this.
Today is Monday?
Next blog?
Yes, that is correct  Slightly different format but hopefully that is okay and keeps things interesting
Slightly different format but hopefully that is okay and keeps things interesting
6 more Mondays to go
Quite the opposite! Helping explain and spread my work is terrific ![]()
One thing to note - effective language generation is not a goal of the NLP stuff shown in the course; it’s just an intermediate output. I’d suggest adding beam search to your notebook, since that will give you far better language generation, and I think you’ll find it an interesting exercise.
Thank you very much Jeremy ![]() I will definitely do so
I will definitely do so ![]()
Hi, I’ve recently started taking this course online, and have found it to be the most insightful online course I have ever taken. I’ve also been inspired to try writing a blog.
Based on what I learned from lessons 1 - 3 and some individual research, I’ve written a blog post on the effect of learning rates on optimization.
I’m still new to blogging and deep learning, so it would be great if I could receive some feedback !
Go on thread! Have a little bit of a boost
totally! i’m here, in the GAN corner - the supporting crew with some pretty (hopefully) pics and one liners: may GeForce be with you
I think it’s great!
Thanks!
For a little while I struggled how to share all the little tidbits of knowledge I accumulate via learning from Jeremy. I tried posts on Medium - they looked nice but I am not sure this is the best format for such information.
So I decided to go with the old time tested github repo!
I am hoping to add more as I continue to study. Have already one or two more in mind.
The repo contains the debugging notebook which potentially is worth taking a look at. It contains debugging tips that I find extremely useful.
Hey everyone, it’s been a little while. I’m looking forward to learning more from the 2018 Part 2 of the course, but in some of the downtime I’ve written another blog.
Any feedback is appreciated!
I implemented the beam search and indeed this turned out to be a fun and educational activity ![]() I also read the now famous post on the unreasonable effectiveness of RNNs by Andrej Karpathy.
I also read the now famous post on the unreasonable effectiveness of RNNs by Andrej Karpathy.
Assuming there are no bugs in my implementation, the beam gets very quickly saturated with only slightly varying outputs of the RNN getting into a loop:
[("for those things that we're going to be done. That's why we're going to be able to come together. And that's why we're going to be able to come together. And that's why we're going to be able to come together ",
-86.380003929138184),
("for those things that we're going to be done. That's why we're going to be able to come together. And that's why we're going to be able to come together. And that's why we're going to be able to be able to be ",
-86.624475955963135),
("for those things that we're going to be done. That's why we're going to be able to come together. And that's why we're going to be able to come together. And that's why we're going to be able to come together.",
-87.184532165527344),
I tried a couple of implementations of the beam search with some added randomness but the results were similar.
I suspect the magic is in the softmax that you sample from - probably one solution of preventing saturating the beam with similar output would be increasing the temperature of the softmax. Another thing that is on my mind is not prunning after going to n+1 chars from n chars, but prunning after say going to n+5. Maybe that could also help with producing more varying sequences.
I’ll see how much more time I will be able to give to this. Monday is right around the corner and there are so many other things I would like to work on ![]()
What I really wanted to post about is how wonderful the Cosine Annealing is. I think this is a very underestimated feature. Basically, you no longer have to devote your time / mental cycles to messing with the lr - you just throw the cosine annealing at it and you will more then likely get something good, or very good (with more epochs ![]() )
)
The fact that just these couple of lines give so much functionality is crazy:
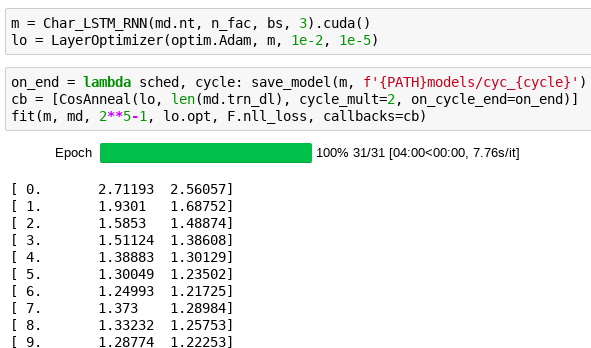
(the output is truncated but the model ends up training really well, with no effort on my part)
EDIT: Some great info on beam search for RNNs here.
EDIT2: I think the reason the RNN was going in this loop was that I was picking the most likely char / couple of most likely chars while doing the beam search, which would be equivalent to sampling from a softmax with a temperature close to 0. Probably doing sampling from a softmax with temp == 1 (the softmax default softmax that we use) should work much better.
Can you share your notebook?
Thanks in Advance…
(Have just started studying RNN's few days back…)
Here is the first notebook in the series.
It has a bug in text generation from RNNs because I didn’t register that the dimensionality of input that a PyTorch RNN expects is: [<seq_len>, <batch_size>, <embedding_size>]. But other than that the notebook should be okay.
I am really happy with the Calculator example I think it is quite fun and simple and plenty of ways to mess around with it. Someone could say it is naive and yada yada yada but I find those toy problems to be really, really worth the while for me.
Part 2 coming this Monday!
We have to thank @radek for keeping the DL spirit alive on Mondays (Like it was during the Part1v2) 
It’s all a team effort!!! ![]()