Looks like it is a problematic zone with reference to the CS231n slide presented by @anandsaha 
2 Likes
This is looking great. Since ‘differential learning rates’ is not something that other people have really discussed before, it would be a good idea to spend more time talking about what this phrase actually means.
Let me know when you feel you’re ready to share it more widely - when you do so, also let me know your twitter handle, so I can credit you properly.
1 Like
Most of you will already be very very familiar with everything discussed in this, but anyway here is one more to the list https://medium.com/@ArjunRajkumar/getting-computers-to-see-better-than-humans-346d96634f73
If you have the time, do read and let me know any feedback.
I actually wanted to write this in a totally non-geeky way to explain what Deep Learning is to my folks and friends who are in other fields, but got a little technical as I was writing it. Also, shared @surmenok learning rate blog, as I felt that explained calculating learning rates really well.
Also mentioned that the new course should be live towards the end of December. Hope that is right @jeremy?
Thanks!
2 Likes
I really like all the background and context you provided here.
One correction : with satellite images we still flip horizontally. The difference is that we also flip vertically and rotate 90 degrees.
Do you have a Twitter handle for when I share this?
Got it… Made the change.
THanks… Twitter handle is arjunrajkumar
Thanks a lot, @jeremy. I have updated the post with more content on Differential Learning Rates. Twitter Handle: @manikantasangu3
I have just published the post Transfer Learning with differential learning rates
Let me know if anything else has to be modified.
1 Like
@All
Here’s a new blog from my side: hope you all enjoy it, and please let me know if I’m fundamentally wrong about something…
4 Likes
Another great post @apil.tamang! Might be useful to link to the Excel example spreadsheet too, and show an image from that? (Only if you think it helps - feel free to ignore!)
1 Like
I’ve been thinking about the “progressive resizing” technique used in lesson2 for Planet Competition, and have just finished a small post on the topic of scale and convnets and its relationship to this fast.ai new technique.
So, here it is: https://miguel-data-sc.github.io/2017-11-23-second/
@jeremy even if it’s just some thoughts on the subject I am entering “not-that-charted-waters”, hope I haven’t completely screwed up the concept, will be glad to correct any misunderstanding if its the case. 
1 Like
Here’s my first Fastai related blogpost.
It is related to experiments using small image datasets to get reasonable accuracy on some fun examples (Cricket vs Baseball, US dollar vs Canadian Dollar). This post is relatively beginner-level, I wanted to describe unfreezing/augmentation etc but that made it a bit long-winded. Maybe I’ll do so in version 2.0…
Do let me know if you guys have any suggestions/corrections
2 Likes
I’m thrilled you gave it a go! And no, you haven’t completely screwed up the concept, although I’m not sure you’ve quite got it right either. But frankly, I’m not even sure when this technique helps, and how much it helps. It helped me a tiny bit on the new seedlings competition. But I think perhaps the main thing it helps with is to allow using small images to quickly prototype, and then switch to big images later to fine-tune.
Perhaps this would particularly help for datasets with really big images where you can only do really small batch sizes. E.g. I wonder if you could get a better result on Imagenet this way?
I think more experiments need to be done before any of us can write a somewhat definitive article on this topic. See for instance @slavivanov’s recent post on differential learning rates (which he found didn’t help much with his particular experiments - although I think will look a lot better with SGDR).
2 Likes
I think it’s perfect What’s your twitter handle?
The explanation using cat whiskers/ears etc was good, it does take a while to ponder over. The fact that not all features are scale-invariant is easier to understand with images. I guess the sequential resizing is kind of adding scale invariance into the CNN system…
1 Like
@jeremy Thanks! My handle is @nikhilbalaji, I did @ to your handle, assuming that I would make any corrections later
Yes, agreed it will take some time to benchmark + objetivize when and how all this cool new stuff works.
I will have my mind in “atention” mode with all this and will report in the future if I manage to benchmark in some objective way some of this new tools. (Also find diferential learning rates another big “mistery trick” still to fully understand). Well, time is on our side to solve this misteries, one by one …!
I think we need to answer the question “why not just use data augmentation” better however…
3 Likes
Hello Everyone,
I’ve written my very first blog post. But before making it public I would like to share it with you guys so that I can get feedback from you I appreciate your help, thanks in advance !
Best
2 Likes
I think this is great! I’ll jot down them thoughts here as I read:
- The definition of structured data isn’t really standardized, so you should be clear what you mean here (you do describe it a bit and show an example, but I think you could be more explicit)
- An embedding is mathematically identical to a 1-hot encoding plus a weight matrix. Since you mention 1-hot encodings, it might be worth mentioning this; also, your description of assumptions made in 1-hot encoding isn’t really correct (since it can be the same as an embedding)
- It might be a good idea to more directly show the relationship between word embedding and entity embeddings
- ‘fast.ai’ should be capitalized
- It’s nice to show the outputs of the code snippets you show - otherwise it’s hard to know what’s going on
- You may also want to cite the Bengio team’s work in this area: https://arxiv.org/abs/1508.00021
Great job! Let me know when you want us to share it
Thanks for the feedback, I am going to work on it and make it prettier, then let you
1 Like
I am having trouble understanding this, since I though embedding was equal to dot product of one hot encoding and learned weight matrix (dot(n x m, m x D)) . And about one hot encoding assumption, I mentioned memory issue and more importantly having equal pair distances among levels. Which assumption is the one that I should change ?
My understanding is like this:
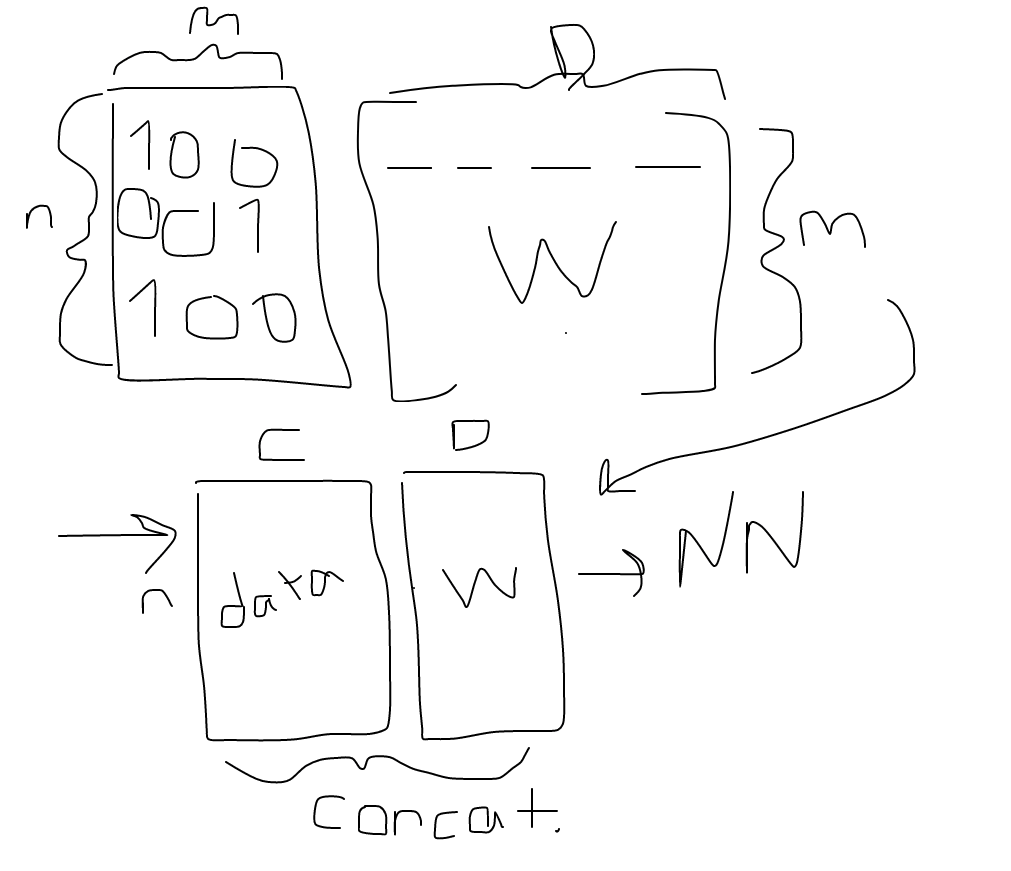
Edit: Apart from one-hot encoding other parts are fixed.
Thanks