Good job! You should credit the source for those images you included, BTW.
2 Likes
Another blog’s up!:
Case Study: A world class image classifier for dogs and cats (err…, anything)
@all would love your feedback.
@jeremy Do you think we should create a new topic, so that we can post our blogs as new topics? Feel like this thread will otherwise never end, or at least be very very long …
@all Also, I created a “Fastai” tag in medium, so i think that could help us organize our blogs into one category.
4 Likes
Hey I really like that @apil.tamang ! One minor issue: we are at USF, not UCSF.
I’m not sure about one thread or many - personally I don’t mind long threads, but others I’m sure have their own opinions.
BTW what’s your twitter handle? I’d like to share this 
Just published a how-to on contributing to fast.ai framework:
btw, I couldn’t find the “fastai” tag, but if anyone is interested in retweeting this my twitter handle is: @0hm30w
4 Likes
I haven’t really used twitter aside from having created an account many years back. Reactivated my account, and followed you on twitter (how does that even work… ! lol ). Handle is @apiltamang
Feel free to tweet the link, and that would be my honor! I’ll make the change on USF, and add in a line or two.
It’s the best DL and ML community around - well worth spending time on…
1 Like
I have created a ‘DL’ list on my handle for finding all the news/activity in one place.
My Handle is bhutanisanyam1
Another entry from me
I had a tough time with some of the issues I encountered and some of the info I share could have saved me quite a bit of frustration and time. Also, I kept reading about the dynamic computation graph but the idea is way cooler and simpler in practice than the name would imply
BTW I fully realize we are not getting into the nitty gritty details of PyTorch just yet, but who knows what the next lecture will bring @jeremy mentioned that we will learn PyTorch and I wanted to understand the code a little bit better so started with the official tutorials which led to frustration which led to this…
The official tutorials are really good BTW and I would fully recommend them - which I actually do in the post - but probably some of the info could have been made a bit more explicit or had I had more recent experience with numerical computations, I would have probably not run into some of the stability issues. Anyhow, probably more people are in my shoes so maybe the post can be of help
9 Likes
I’ve just published a post about estimating a good learning rate.
I added links to few other Medium posts from this thread into the end of my post. Cross-linking will help to get more traffic to our blogs in general.
7 Likes
I really like this! And I love the idea of cross-referencing other materials that can help explain things.
One thing that this post and everyone’s post should mention is that you’re taking the new course in person, and that it’s not available to the general public yet - but will be at the end of the year at course.fast.ai (which currently has last year’s version).
2 Likes
Thank you, Jeremy. I added this note to my post.
And here is my attempt to make practitioners aware of Cyclic Learning Rate
Blogged about it here:
The Cycling Learning Rate technique
–
4 Likes
Nice job @anandsaha . Although I think you’re confusing some issues:
- The learning rate finder happens to be mentioned in the CLR paper, but has nothing to do with CLR otherwise
- SGDR is not an optimizer, it’s a different annealing schedule
- CLR is an annealing schedule that’s not used at all in the fastai library.
So I’d suggest covering SGDR, not CLR, since SGDR solves the same problem but better
4 Likes
Thanks @jeremy for that feedback!
The learning rate finder happens to be mentioned in the CLR paper, but has nothing to do with CLR otherwise
I mentioned the upper and lower rate finder as mentioned in the paper, was it not it’s original contribution?
SGDR is not an optimizer, it’s a different annealing schedule
Aah… correcting now.
CLR is an annealing schedule that’s not used at all in the fastai library.
Yes I mentioned that ‘The fastai library uses CLR to find an optimal LR and SGDR as the optimizer.’ Now that I see your post, you mentioned fastai used the idea from CLR. I will correct it. Will that be appropriate statement?
So I’d suggest covering SGDR, not CLR, since SGDR solves the same problem but better
Absolutely! I am going through that paper
Btw I also discovered that fastai student Brad Kenstler implemented the CLR scheduler in keras which got ported to PyTorch awating review to merge to master. Amazing!
1 Like
No, the main contribution was the idea of continuously moving the LR both down and up. Previously people had generally only decreased LR.
The idea of the “LR finder” was an additional contribution, but is largely orthogonal.
So I used an idea from the CLR paper (the idea of the LR finder), not the idea.
The SGDR paper shows very impressive SoTA results, especially along with snapshot ensembling.
Hope that clarifies a bit…
2 Likes
Got it, thanks for the insight!
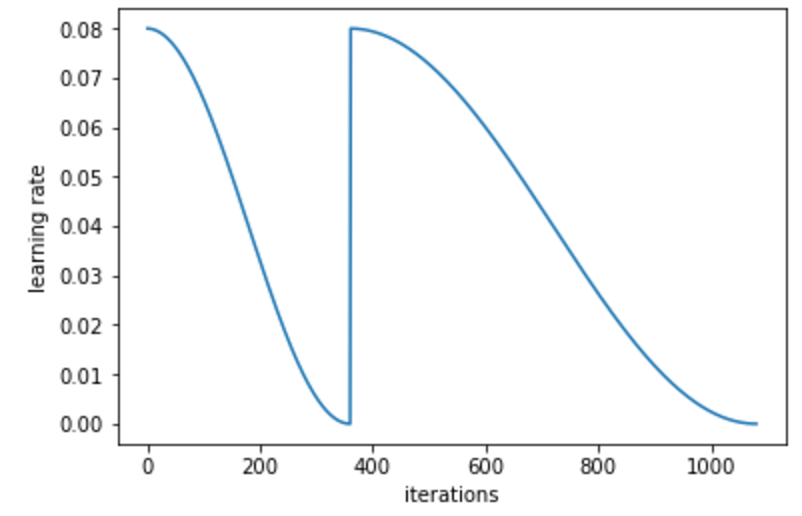
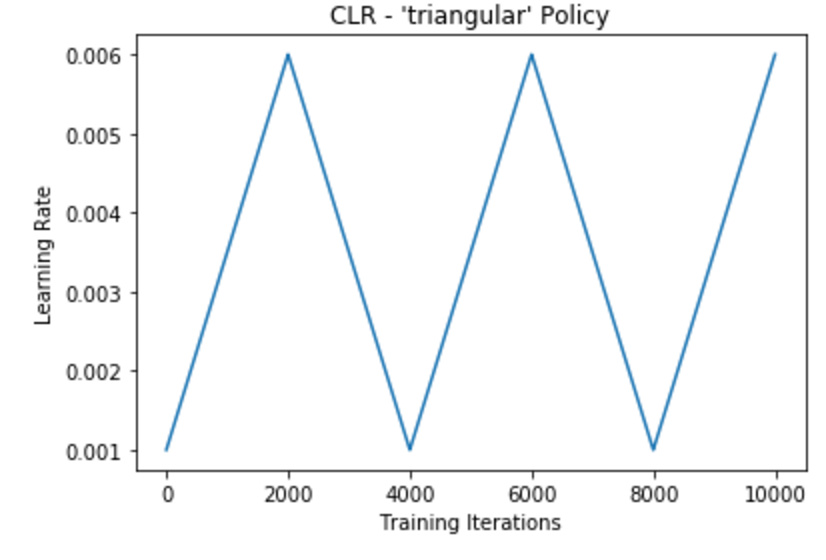
I found that his implementation of cycling is different than fast ai’s pytorch. He updates rates in a linear fashion (increase and decrease). Whereas fastai’s pytorch decreases with cosine annealing and immediately restarts back to the upper learning rate. See the difference in the LR plots:
Fast AI Pytorch
bckenstler’s Method
1 Like
Yes, the one he implemented (and I wrote about) is for from this paper.
The one in fastai are from these papers:
https://arxiv.org/abs/1608.03983
https://arxiv.org/abs/1704.00109
(also @jeremy’s reply has some more info)
–
3 Likes