And this is my last blog post in the 8 week series
Of course, many doubts about both the content and the presentation. I think I should have asked people to take a look at the post before I published it. But all these coulda shoulda woulda are probably also a direct result of the insecurity about posting things that despite having done this for 8 weeks hasn’t completely gone away.
But oh well. If you cannot conquer it, maybe at least you can ignore it
Thank you I am not a writer. And for most of my professional life my writing sucked. To the point where I had it in my year end objectives for a couple years running to figure out how to be more concise I never did before leaving that job
I do put a lot of work into writing these articles though. Really glad you enjoy them
I have to confess- I never took blogging seriously. My first article was a really bad attempt. But @radek has been a constant source of learning for I think all of us, and I think I can say I’ve improved a lot-thanks to him
I think this is the best part about fast ai too. We get to meet great DL folks.
I’ve learnt so much in the past 6 months just by scrolling through the forum threads daily, more than what my school has taught me during my 3 years of undergrad studies.
ooo…Does anyone remember the moment from Part1v2 where Jeremy had posted a screenshot of the LB?
And the LB got turned upside down every 2 hours?
I’ve posted a few blogs here on setting up AWS, jupyter notebook. Feedback welcome. Tutoring a local group in Brisbane, found it easier to blog on medium than demo the same thing multiple times.
suggestions on best option to assign a static ip (elastic IP on aws), route a domain to the ip and create a ssl from a recognised ssl provider welcome.
Hi all, I have begun blogging and have written a couple of blogs. I would like some suggestions on the things I can improve (especially since the first one is based off the first deep learning class).
Augmentation for Image Classification:
I’m planning to put together a series of best practices from all the resources that I come across, so this is the first one:
@jeremy your feedback will be most valuable.
Thanks a lot!
Thanks for sharing @neerjadoshi In the augmentation article, note that training time augmentation only helps when you train multiple epochs. In your case you’re just training one epoch, so I’d guess the improvement is just random noise. Also you need to unfreeze the network, otherwise over-fitting is very unlikely (and therefore augmentation doesn’t help).
I’d suggest trying a dataset that’s not quite as similar to imagenet, so needs more epochs to get good accuracy, and you should be able to show a more compelling difference then.
The initializations post is looking good. I think it would be helpful to show code examples of each concept you’re talking about; and where you do show code, put it in a code block, not a picture, so people can copy and paste it and try it out. Also, maybe show some experiments to show how it impacts training in practice?
A link to the papers that introduced each init method might be nice too.
I realise what can be corrected in the augmentation article. I’ll find a suitable dataset and train multiple epochs to capture the difference in performance.
Also, I’ll update the code snippets and references in the second article. In the material I’ve been reading, I’ve also been finding a lot of small nuances to add to that blog, so I’ll update accordingly.
Thank you for your feedback!
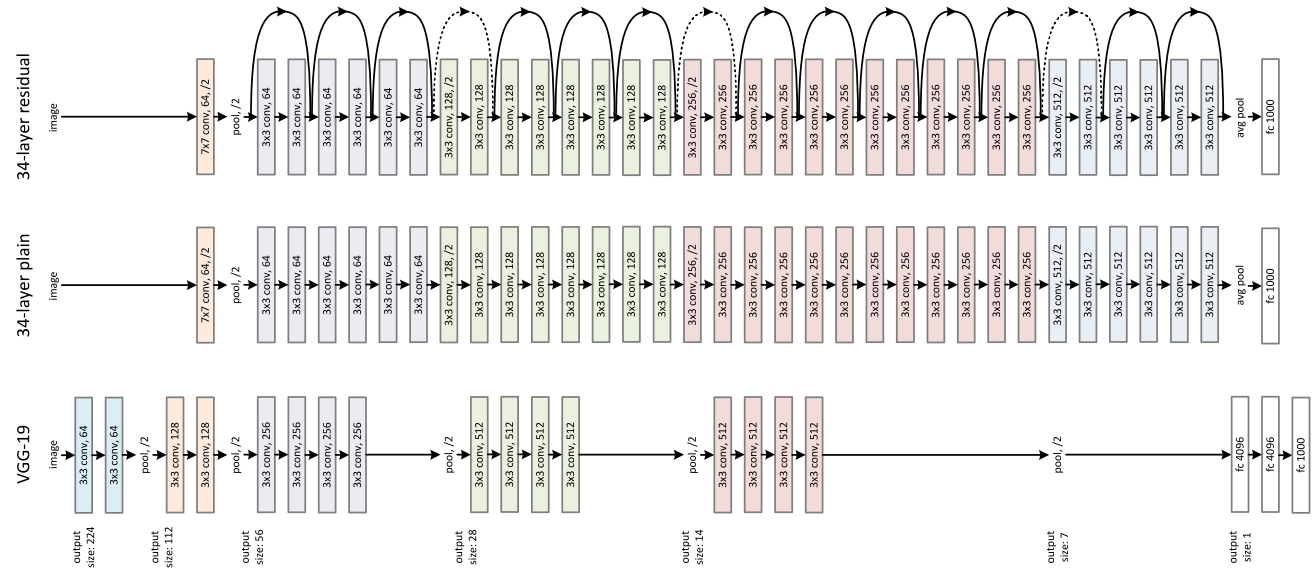
In the Resnet paragraphe, the autor (Mohit Deshpande) explains the beauty of Resnet in 3 points :
More layers is better but because of the vanishing gradient problem, model weights of the first layers can not be updated correctly through the backpropagation of the error gradient (the chain rule multiplies error gradient values lower than one and then, when the gradient error comes to the first layers, its value goes to zero).
That is the objective of Resnet : preserve the gradient.
How ? Thanks to the idendity matrix because “what if we were to backpropagate through the identity function? Then the gradient would simply be multiplied by 1 and nothing would happen to it!”.
You can even forget the vanishing gradient problem and just look at an image of a Resnet network : the identity matrix transmits forward the input data that avoids the loose of information (the data vanishing problem).
Good article, maybe i am missing something, but perhaps you could add to your post the process in detail for getting a twitter follower assuming you have zero?
create a post and just post it to the twitter ether, and keep doing repeatedly?
message people with questions in hope thet 1/10 to 1/100 will respond, and maybe follow you,
Hey guys, I just wrote my first blog post which is an introductory post to Pytorch, In this post I talked about torch packages, tensors and how does automatic differentiation work, along with a hands-on Pytorch example.
I would love to hear your feedback. Thanks

 I am not a writer. And for most of my professional life my writing sucked. To the point where I had it in my year end objectives for a couple years running to figure out how to be more concise
I am not a writer. And for most of my professional life my writing sucked. To the point where I had it in my year end objectives for a couple years running to figure out how to be more concise