I also have a data engineering question  :
:
Are there packages that might help or sample code in python to chop a log file into multiple parts by some pattern and apply a single procedure to extract data from all these parts in parallel?
I also have a data engineering question :
Are there packages that might help or sample code in python to chop a log file into multiple parts by some pattern and apply a single procedure to extract data from all these parts in parallel?
You don’t need a package for that - just use ProcessPoolExecutor.map
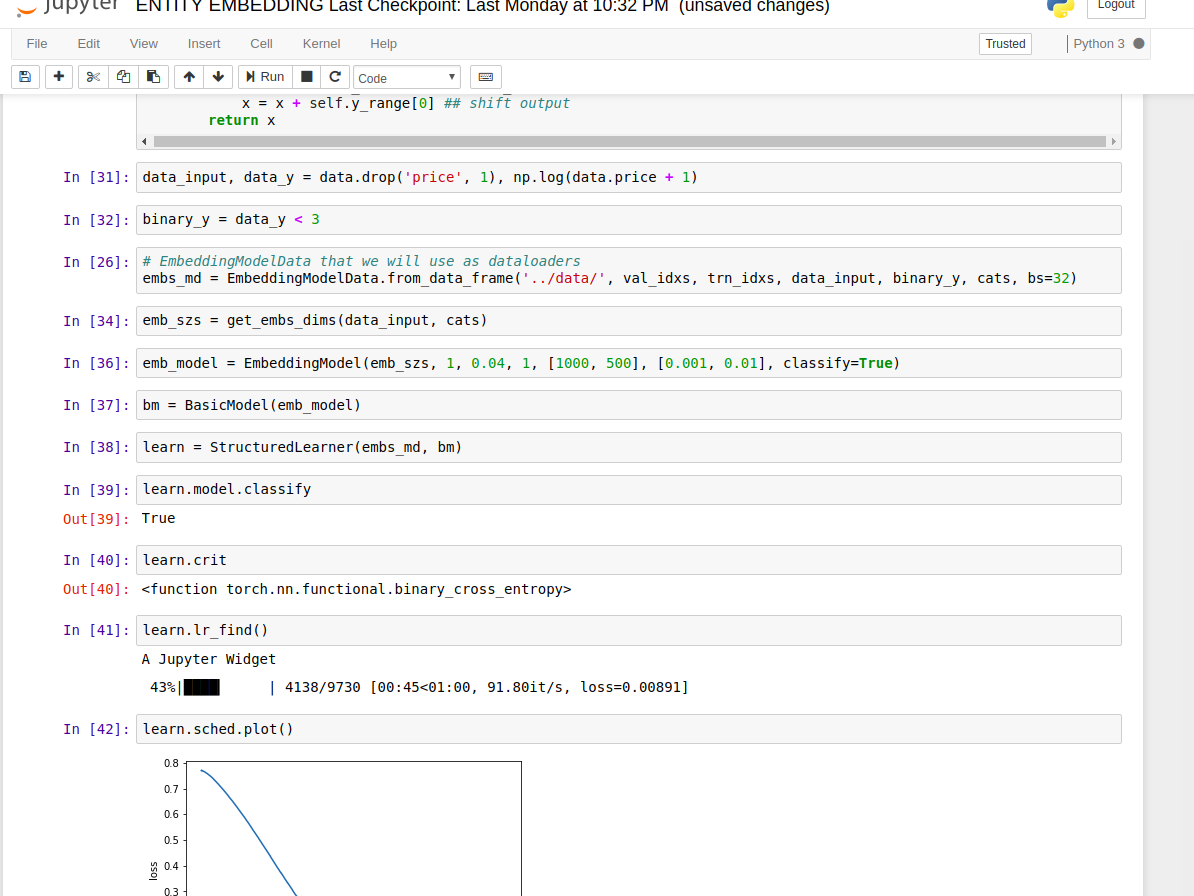
@jeremy I tried the following for getting classification task but the code gave error
m = md.get_learner(emb_szs, n_cont = len(df.columns)-len(cat_vars),
emb_drop = 0.04, out_sz = 2, szs = [250,100], drops = [0.001,0.01], use_bn = True)
lr = 1e-3
m.fit(lr, 1, crit = F.cross_entropy)
It threw following error. Not sure what should be the settings to get model working for classification
TypeError: fit() got multiple values for argument 'crit'
Try changing the loss function to F.cross_entropy in ‘StructuredLearner’ class in column_data.py.
Or I think you can just move the crit= bit into the get_learner call.
Thanks. I tried changing the following functions.
1 . Changed F.mse_loss to F.cross_entropy and it threw some error
2. I tried to change the API of get_learner to pass crit = F.cross_entropy and it also threw error that crit was invalid argument. I had made change in relevant functions.
Not sure what all the mistakes I am doing
@jeremy : Is there a sample python notebook for classification task for structured data. I tried to go through the functions but I didn’t get too far in terms of getting the code working for classification at my end for structured data.
No, I’ve not tried it. You’re in unchartered waters!
Hi what is the intuition behind this embedding weight initialization:
def emb_init(x):
x = x.weight.data
sc = 2/(x.size(1)+1)
x.uniform_(-sc,sc)
Thanks
I did the following, this is for binary classification only for multiclass F.cross entropy expects multi dimensional input and int target, so much more need to be changed for that:
class StructuredLearner(Learner):
def __init__(self, data, models, **kwargs):
super().__init__(data, models, **kwargs)
if self.models.model.classify:
self.crit = F.binary_cross_entropy
else: self.crit = F.mse_loss
class MixedInputModel(nn.Module):
def __init__(self, emb_szs, n_cont, emb_drop, out_sz, szs, drops, y_range=None, use_bn=False, classify=None):
super().__init__() ## inherit from nn.Module parent class
self.embs = nn.ModuleList([nn.Embedding(m, d) for m, d in emb_szs]) ## construct embeddings
for emb in self.embs: emb_init(emb) ## initialize embedding weights
n_emb = sum(e.embedding_dim for e in self.embs) ## get embedding dimension needed for 1st layer
szs = [n_emb+n_cont] + szs ## add input layer to szs
self.lins = nn.ModuleList([
nn.Linear(szs[i], szs[i+1]) for i in range(len(szs)-1)]) ## create linear layers input, l1 -> l1, l2 ...
self.bns = nn.ModuleList([
nn.BatchNorm1d(sz) for sz in szs[1:]]) ## batchnormalization for hidden layers activations
for o in self.lins: kaiming_normal(o.weight.data) ## init weights with kaiming normalization
self.outp = nn.Linear(szs[-1], out_sz) ## create linear from last hidden layer to output
kaiming_normal(self.outp.weight.data) ## do kaiming initialization
self.emb_drop = nn.Dropout(emb_drop) ## embedding dropout, will zero out weights of embeddings
self.drops = nn.ModuleList([nn.Dropout(drop) for drop in drops]) ## fc layer dropout
self.bn = nn.BatchNorm1d(n_cont) # bacthnorm for continous data
self.use_bn,self.y_range = use_bn,y_range
self.classify = classify
def forward(self, x_cat, x_cont):
x = [emb(x_cat[:, i]) for i, emb in enumerate(self.embs)] # takes necessary emb vectors
x = torch.cat(x, 1) ## concatenate along axis = 1 (columns - side by side) # this is our input from cats
x = self.emb_drop(x) ## apply dropout to elements of embedding tensor
x2 = self.bn(x_cont) ## apply batchnorm to continous variables
x = torch.cat([x, x2], 1) ## concatenate cats and conts for final input
for l, d, b in zip(self.lins, self.drops, self.bns):
x = F.relu(l(x)) ## dotprod + non-linearity
if self.use_bn: x = b(x) ## apply batchnorm activations
x = d(x) ## apply dropout to activations
x = self.outp(x) # we defined this externally just not to apply dropout to output
if self.classify:
x = F.sigmoid(x) # for classification
else:
x = F.sigmoid(x) ## scales the output between 0,1
x = x*(self.y_range[1] - self.y_range[0]) ## scale output
x = x + self.y_range[0] ## shift output
return x
Thanks. I will make changes at my end and try them.
IIRC that’s Kaiming He Initialization, although now I look at it I think I’m missing a sqrt there…
Thanks for this code - trying to use this for a classification problem. How did you modify y, the dependent variable, for classification? I see binary_y, not sure what it does.
So, in this code binary_y is 0s and 1s
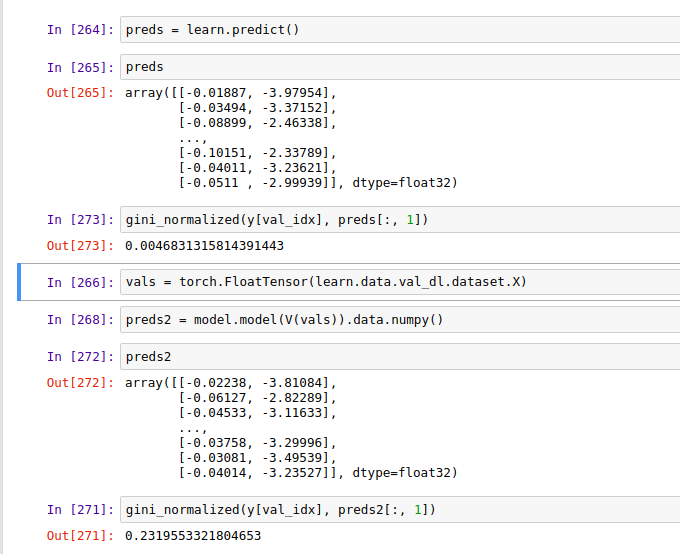
Hi,
When I am making validation predictions with learn.predict() every time I am getting different and odd results. While when I explicitly do the predictions still using learn.model I am getting the expected results. What is going on here 
Thanks
Sounds like you might be applying data augmentation to your validation set. You should only apply it to the training set.
You’re passing shuffle=True to your DataLoader 
ooops you are right thanks !
Hello! Thank you for this snippet.
I would like to implement it, and so I modified the column_data.py file.
But where can I find the EmbeddingModel* classes that you call in the Jupyter screenshot? I don’t find them in the fast.ai library…
Thank you
check sturctured.py and column_data.py. What better is that if you use PyCharm you can easily do this and search:
Class: Ctrl+N
File (directory): Ctrl+Shift+N
Symbol: Ctrl+Shift+Alt+N