Yes it will - and it should still work eventually, as long as the learning rate is low enough. But it won’t be able to use the pre-trained weights much, if at all, so I doubt you’ll get better results than just initializing randomly. Perhaps try both and report back on the results? It’s a great exercise to work on this before this week’s class, since you’ll be very familiar with the issues that we’ll be discussing.
2 Likes
Hi, I am trying to follow the last lesson for statefarm but still seeing the same ~11% accuracy results. 
Epoch 1/2
1496/1496 [==============================] - 42s - loss: 14.3149 - acc: 0.1076 - val_loss: 14.2906 - val_acc: 0.1134
Epoch 2/2
1496/1496 [==============================] - 41s - loss: 14.2973 - acc: 0.1130 - val_loss: 14.2906 - val_acc: 0.1134
WIth following breakdown of files:
sample/train:Found 1496 images belonging to 10 classes.
sample/valid:Found 979 images belonging to 10 classes.
I mean I have it exactly like Jeremy showed us in the class.
I reduced the LR to even as low as 1e-7 but it didnt even change an ounce.
I changed activation to relu - no change.
Should I add a CNN before the dense layer?
Any suggestions?
Ok it got better when I add another dense later with “relu” and ran 7 epochs one with very low LR and one with higher LR just like in the class.
Yay!! Feeling encouraged 
Epoch 1/2
1496/1496 [==============================] - 41s - loss: 2.6742 - acc: 0.0836 - val_loss: 6.9782 - val_acc: 0.1716
Epoch 2/2
1496/1496 [==============================] - 20s - loss: 2.1978 - acc: 0.2413 - val_loss: 6.0879 - val_acc: 0.1716
Epoch 1/5
1496/1496 [==============================] - 34s - loss: 2.0497 - acc: 0.3329 - val_loss: 5.0679 - val_acc: 0.1440
Epoch 2/5
1496/1496 [==============================] - 21s - loss: 1.9034 - acc: 0.4358 - val_loss: 3.1969 - val_acc: 0.2022
Epoch 3/5
1496/1496 [==============================] - 20s - loss: 1.7915 - acc: 0.4967 - val_loss: 2.2603 - val_acc: 0.3136
Epoch 4/5
1496/1496 [==============================] - 22s - loss: 1.6926 - acc: 0.5374 - val_loss: 1.7427 - val_acc: 0.4157
Epoch 5/5
1496/1496 [==============================] - 21s - loss: 1.6004 - acc: 0.5809 - val_loss: 1.5945 - val_acc: 0.4811
3 Likes
Looks like you’re on the right track - but feel free to post your notebook as a gist if you get stuck again.
I have a suspicion I am not doing batch normalization the right way because on the same validation set, my accuracy dropped from 64% (data augmentation) to 20% (data augmentation + batch norm). Also tested models with randomized weights and weights copied from vgg model (dense layers only) … they are pretty similar except that randomized weights have a slight lower accuracy by only 2% points.
Which layers are you adding batchnorm to? On the conv layers, are you using axis=1?
So this is my batch_norm fn:
def bn_get_layers(p=0.):
layers = [MaxPooling2D(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
Dense(4096,activation='relu'),
Dropout(p),
BatchNormalization(mode=2),
Dense(4096,activation='relu'),
Dropout(p),
BatchNormalization(mode=2),
Dense(10,activation='softmax')]
return layers
Reading your state farm sample notebook, I noticed axis=1 is only present in the convolution part and not the dense layer. BatchNormalization(axis = 1) when used on convolutional layers
Yup that’s right. Why mode=2 ? I haven’t tried that before myself.
Batchnorm won’t be as good as your previous models, since your previous models used pre-trained imagenet networks, which aren’t going to work with batchnorm (until I show you the trick tonight! )
1 Like
I used mode=2 because it gave out an error when I used the default mode=0. The error message recommended that I use mode=2. I need to take a look at your script of inserting batch norm layers on a pretrained model.
Hello,
I read through the ‘Basic Models’ part of Jeremy’s Statefarm Sample notebook, and have some questions. The questions are marked by a “#ETHAN:”. Here’s the link: https://drive.google.com/file/d/0BxpmApEkblZHTGRmX01iekJneU0/view?usp=sharing
Thanks!
Do you have a github account? It will be easy for us to have a look without having to download the notebook.Take a look at this: Memory Error issue
From statefarm notebook:
(However this means that we can’t use full data augmentation, since we can’t pre-compute something that changes every image.)
Is this because ImageDataGenerator creates new images in real time and there is no real way to keep track of the labels as a result?
Let me know if this doesn’t work.
No, it’s just that it’s logically impossible. You can’t usefully precompute a random number. By definition, it’s random, therefore you have to calculate it each time you need it!
+#ETHAN: Is this a necessary step?: Probably not. I think Jeremy uses it to select his gpu in his local machine for a particular job.
+#ETHAN: Where does ‘get_batches’ come from? Why not use vgg.get_batches? vgg.get__batches looks redundant and has probably not been used much.(@jeremy any plans on retiring this?) get__batches is present in utils.py and has been used extensively
+#ETHAN: What exactly is get_classes doing? Easiest way is to look up the code under get__classes function. But in summary it is returning the validation and training classes (0,1 …9), their one hot encoded form and respective image file names
+#ETHAN: What does each of the parameters of Sequential do, and where does the Sequential() function come from? building layers- each param (eg. BatchNormalization) separated by a comma is building a layer sequentially in the order presented. Sequential comes from from keras.models import Sequential (see utils.py - it imports a number of libraries and methods used through out this class)
+#ETHAN: What is Adam()? Where/how would I define it? What does metrics=[‘accuracy’] do? again from utils.py. Look out for from keras.optimizers import .. To see how to define it on a python interpreter do Adam? or look up the documentation. Metrics as accuracy is simply computing how accurate your model is against training set and validation set. This is for us to decide what next steps should I take to improve the model or stop
+#Where is compile and fit_generator from? I believe these are methods available after building a model using the Sequential class
+#What does 1e-5 mean? Is that the same as ‘e-5’ 1e-5 = 0.00001
Any mistakes please call out…
Nice answers @vshets . To clarify a few:
- I’ve not been using the vgg class much since the first lesson, since I’m showing how to actually implement the stuff in that class yourself. The vgg class is designed for complete beginners, which you guys aren’t any more!
- The Sequential(), Adam(), compile(), and fit_generator() all come from keras. To learn what they do (including the meaning of metrics=[‘accuracy’]) use the search box at https://keras.io/ . To quickly learn about the parameters to any function, including these, use the tip I showed on Monday - type a ‘?’ followed by the name of the function you wish to learn about
- I showed how the Adam optimizer worked when I went through the graddesc.xlsm spreadsheet in lesson 3. Have another look at that part of the lesson and work through the spreadsheet yourself to ensure you understand how adam works
1 Like
@jeremy I am a bit stumped… i was getting really good accuracy with my model
Train on 20624 samples, validate on 2000 samples
Epoch 1/1
20624/20624 [==============================] - 8s - loss: 1.5445 - acc: 0.5796 - val_loss: 0.0764 - val_acc: 0.9835
Train on 20624 samples, validate on 2000 samples
Epoch 1/2
20624/20624 [==============================] - 8s - loss: 0.3063 - acc: 0.9080 - val_loss: 0.0293 - val_acc: 0.9930
Epoch 2/2
20624/20624 [==============================] - 8s - loss: 0.1598 - acc: 0.9552 - val_loss: 0.0156 - val_acc: 0.9965
but when i ran on the test set I landed up at 358 position in kaggle.
This is the code i ran to create the submission
def do_clip(arr, mx): return np.clip(arr, (1-mx)/9, mx)
preds = bn_model.predict(conv_test_feat, batch_size=batch_size*2)
subm = do_clip(preds,0.93)
subm_name = path+'results/subm.gz’
classes = sorted(batches.class_indices, key=batches.class_indices.get)
submission = pd.DataFrame(subm, columns=classes)
submission.insert(0, ‘img’, [a[4:] for a in test_filenames])
submission.head()
submission.to_csv(subm_name, index=False, compression=‘gzip’)
FileLink(subm_name)
1 Like
Actually looks like i am getting high accuracy on validation but not on training set… hmmmm 
I reduced the droprate (p=0.4) training set accuracy went up
Train on 20624 samples, validate on 2000 samples
Epoch 1/1
20624/20624 [==============================] - 8s - loss: 0.3842 - acc: 0.8865 - val_loss: 0.0341 - val_acc: 0.9900
Train on 20624 samples, validate on 2000 samples
Epoch 1/2
20624/20624 [==============================] - 8s - loss: 0.0406 - acc: 0.9912 - val_loss: 0.0162 - val_acc: 0.9950
Epoch 2/2
20624/20624 [==============================] - 8s - loss: 0.0230 - acc: 0.9937 - val_loss: 0.0156 - val_acc: 0.9960
Thank you! I have another question/error: From what I understand, it’s able to load the validation data, but for some reason not able to load the train data… Is bcolz not working properly?
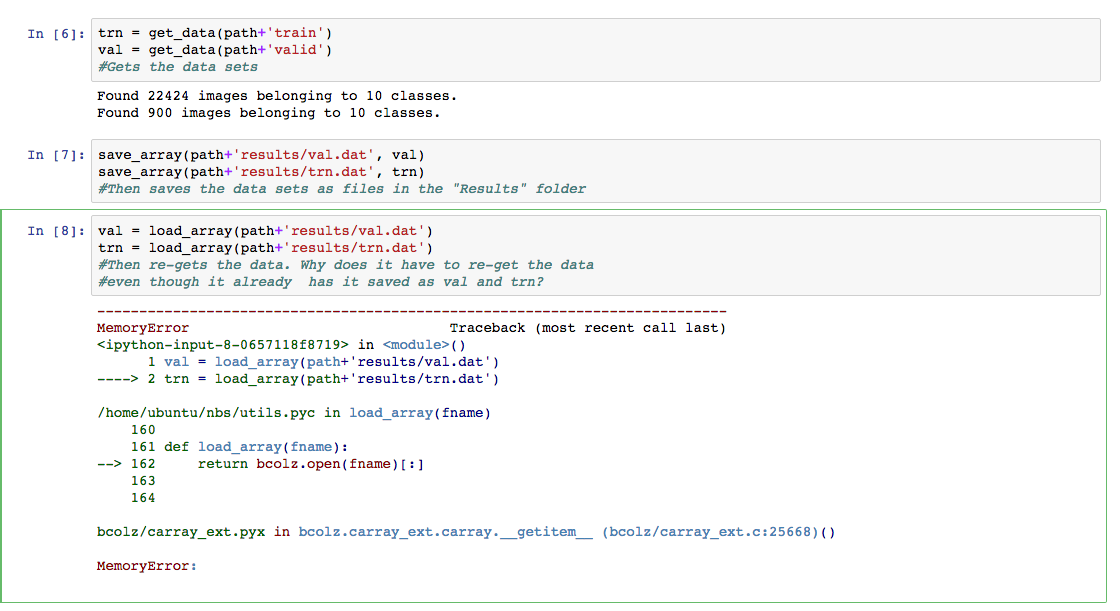
@ethan you are getting a memory errror. Are you running on a micro instance?
Can you share the result of the cell where you said cuda.use(‘gpu0’)?