@jeremy Can you elaborate on why you think Google Cloud ML would be a short cut as opposed to our own DL server? I looked into it and found Google Cloud SDK kinda hard to work with. Although, It seems to be delivering a more economical service than AWS.
A related question, won’t super resolution be super easy for Google/Facebook/Photoshop to integrate into their existing products? Given their existing user base + training data, how could we possibly compete?
Great idea! Do you have any particular theme that you are passionate about?
My immediate thought is a revamp on the old silent film. It’s convenient because it’s visual only, you don’t have to worry about creating dialogue/narrative.
If you’ve seen the movie Hugo, they made reference to Georges Méliès’s films, which has roots in magic tricks. Personally I feel it could blend well with deep learning.
It just so I came across this thing called deepwarp, which allow you to create image of anyone rolling their eyes. It’s quite fun, and I can image spinning that on this following film.
We can add style transfer, playing around with time and space, really bring this old film to life… of course there is super resolution, and all kinds of other fun stuff.
Just some quick thoughts and hope that stimulates the conversation. I’m absolutely open to all kinds of ideas.
3 Likes
I think it’s a brilliant idea and definitely feasible. I’m keen to explore it and the idea of enhancing/augmenting existing content just like we did with the cat.
I’m also exploring using video game animations as input and generating photorealistic or painting stylized output via CycleGAN. So take Grand Theft Auto (which OpenAI Universe has an API for) and apply the “monet2image” technique outlined in the CycleGAN paper. See their horse to zebra example. Pretty smooth video-based transfer.
Our “Paintbrush” can be pre-designed 3D Unity objects and animation sequences (there are tons in the Unity assets store which our algorithm can be trained to generate. Instead of generating raw pixels, we train the model to map text descriptions to 3d characters and to generate commands like “left”, “right”, “up”, “jump” etc.
We can pass these semi-realistic 3D generations into a conditional GAN like CycleGAN, to bring them to life.
Definitely far out, but I think with shortcuts + backdoors we can get something cool working that’s mostly AI generated. I’m going to play around with Cycle GAN painting --> image tonight and see how it works.
2 Likes
Sure - it’s a great question.
Putting a model in production is not at all straightforward. You have to think about:
- Not running out of GPU memory
- Batching up multiple requests, if they’re coming in fast, to take advantage of the GPU
- Ensuring that no one user or request saturates your resources
- Queueing up requests when all GPUs are free
- Sharing batches across GPUs so that they’re all being used effectively
- …and so forth
Take a look at the Tensorflow Dev Summit video on Tensorflow Serving to get a sense of the kinds of problems it solves. Both Cloud ML and Tensorflow Serving are likely to help with this stuff, although the latter is still rather incomplete and buggy, I believe.
5 Likes
In my experience that’s never something you want to be asking yourself! Yes, it’s true, absolutely anything you ever think of or do could be done be someone else. But, will they do it with as much care, attention to detail, tenacity, user empathy, pragmatism, and efficiency as you? No, of course they won’t!!! If you believe otherwise, you will never be able to release anything, or if you do, and someone else comes along to compete with you (which always will happen if you’re successful), you’ll give up.
If anything, the opposite is true - building something extremely complex and beyond the current research cutting edge is something that big companies are more likely to be good at. Or if you do it, and they see it can be done, they’ll be more likely to be better at catching up and passing you.
Smaller companies are great when they pick something they care about, and is within their capabilities to do a great job of. Dropbox is a great example - pretty much every big company had already tried to do file sync (Microsoft had tried at least 3 times!) but Dropbox did it with more care and pragmatism.
When I started FastMail, pretty much everyone told me that it was pointless to compete with Yahoo and Hotmail. But I went ahead anyway because I felt like what I wanted to create was something that no-one else at that time had yet created, and I wanted it to exist (that is, synchronized email across all your computers).
So, once you become the first person to build a great (for example) super-res product, you are now the leader, and can move on to adding lots of other great features for cleaning up old photos and scans. Everyone else is now playing catchup. And of course they’ve all got their own priorities, which are keeping them busy! 
Anyways, as I’m sure you can see, this is something I feel very very strongly about. We have to believe in ourselves, and we have to build things that we want to see exist, and can’t be assuming that someone else is going to do it better than us!
55 Likes
Some more ideas. In the world of video games/animations/3d renderings, where are the datasets that map animation --> photo? Two things that immediately come to mind:
- Call of Duty game --> Band of Brothers Movie. There is a sequence in the video game that copies the movie sequences almost exactly.
-
Minecraft --> Flickr. We look for worlds built on real places like these and then train a model to generate minecraft worlds. Minecraft already does non-deep learning level generation so this should be straightforward.
 . There are python APIs for creating the worlds. Might be an RNN problem.
. There are python APIs for creating the worlds. Might be an RNN problem.
Unrelated, but on the topic of Generative models… anyone interested in generating 3D printed objects? We train a GAN on open-source 3D printer designs, say a specific category like “cups” and see what it comes up with. We can explore the reverse too, images of 3d printed objects --> designs.
3 Likes
I wish there was a way to triple-like this post.
It’s really good to hear this and I know others will feel the same way. Sounds like a chapter for your next book 
1 Like
5 Likes
Yes, @brendan, super-great. I think there is tons of potential in DL augmented design. Definitely, on my impossibly long, ever-growing list of things I want to try and do. If only I could code faster
Perhaps related to this: If you took a model which extracts 3D information from a photo and combine it with one trained to create 3D shapes you almost have a replicator (even without 3D scanner). Perhaps even better than a 3D scanner. The latter only scans the surface, but with a trained model you can impute a 3D interior (given some boundary conditions determined by a classifier which knows what class of object you are looking at).
Interesting case of super-resolution. This company was bought by Twitter. They downsampling video game streaming quality to make it faster and then apply super-resolution on the client side to upsample. Neat!
2 Likes
Not exactly DL augmented design, but I tried running BEGAN on zappos shoe dataset and I got it to interpolate between a few shoes to generate new “designs”. The output is not perfect, but you largely get an idea of what you get when you mix two shoes.
The code for this came from https://github.com/carpedm20/BEGAN-tensorflow . I just edited a few things to adopt to Python 3 and tensorflow version on my system. It took 50 hours to run on a single 1080.
What do you think of the output?
The interpolation below shows one kind of shoe morphing into another with (reasonably?) believable intermediate shoe designs.






These shoes are the ones that are generated by the trained network.



5 Likes
Very interesting idea! The images are a bit smallish, but some are quite convincing. I think a future improvement might be to alight the shows. As they are photographed from different angles, the intermediates sometimes have a not quite believable perspective (e.g. third row from the top).
This “alignment” needs to be some sort of image registration. Ideally, you’d even do this in 3D (involving to extract a 3D model of the shoe from the photo, rotating it to match the other shoe, rendering both in the same perspective and then doing the morphing).
Still, pretty exciting.
As for the 50 hours training - could you share a history of the loss function and/or accuracy? That might be helpful to understand how it trains. I am asking, because, sometimes I don’t know if I am just giving up an architecture too early or if it is actually buggy.
I wrote about the image quality in the issues in the github repo and got a response from one of the paper authors about trying to tweak my learning rate, h & Z. I think that is very nice that the community at large is very very helpful.
Also, my images did not drastically improve beyond 200k iterations. the lack of diversity in the output (second half of the set of images was due to mode collapse). I don’t think I understand what that means, but I hope one if you can explain it to me :-).
The original paper had interpolation between faces in different angles and it should be able to learn provided there is diversity in the input sample. However, zappos dataset has no diversity when it comes to shoe angle. I am downloading some car pictures to see if I can train this on car images. (and get more images of subaru baja or chevy el camino by interpolating between car and truck  )
)
I’d like to do this in 3D space, but I can’t wrap my head around how to represent the data … baby steps, I guess.
could you please elaborate on this? I don’t understand.
My loss function over time is below.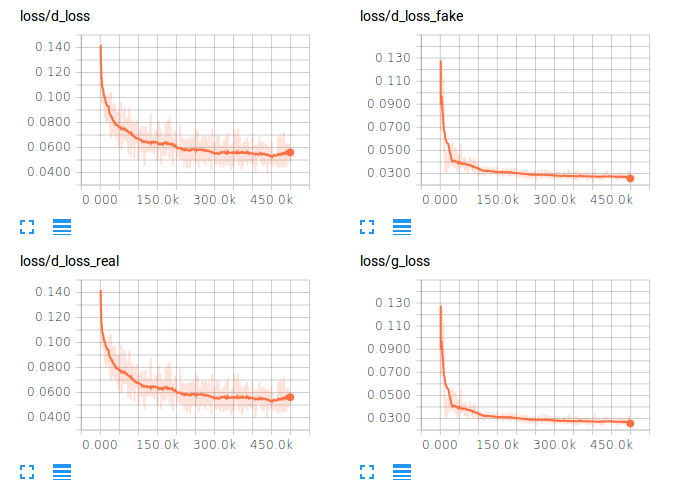
I can also share my trained network parameters if you care.
1 Like
@brendan, @xinxin.li.seattle
After playing with Began paper on zappos and seeing their results on face interpolation, It would be cool if we can take a movie, replace the primary character with your face and also transfer the actors emotions to your face. Now imagine doing that on charlie chaplin’s movies.
This blog post talks about how to get the facial landmarks and how to morph the faces from one angle to another.
I have no clue if we can make the may timeline, but we can play with the various bits and pieces and see what comes out of it.
2 Likes
re: Registration
By that I mean a way of aligning images to one another, often used in time series.
See the two animated GIFs at the top of TurboReg. It is outdated now, but shows the idea visually.
However, registration may not be enough, therefore I thought of doing something in 3D, such as in face2face - warning: scariest thing ever(!) and thanks to @Dario for the link.
Besides - I can tell from the screenshot you are using tensorboard. I got that to run the other day, but still felt at a loss to navigate through a reasonable deep DenseNet architecture. The guy in the Summit video mentions putting telling names when creating the layers. What is your experience with graph viz and TensorBoard?
@iNLyze I don’t think we need to align images together at all. in fact one of the recommendations was to augment the input data with some rotation and translation so that the model gets more robust. The orientation should be a property of the latent Z vector.
Thanks for the face2face demo link. I just typed about doing that, albeit in reverse… in the previous post. @brendan @xinxin.li.seattle… check face2face out. [quote=“Surya501, post:40, topic:2365”]
This blog post talks about how to get the facial landmarks and how to morph the faces from one angle to another.
[/quote]
Reg Tensorboard: this particular project uses tensorflow, so I didn’t have to do anything. However, I was able to use tensorboard to visualize embedding. It was very very useful for me on that front. You need to deal with some vodoo magic to name the layers and create a mapping via metadata file. I think I posted it on the forum before, IIRC. I can help you with that if you are having issues with that part. Trying to visualize the graph is a mess via tensorboard for me.
cool.
nice work on BEGAN by the way, did you try it out on the human face data (besides shoes)? There are some debate about replicating the face image, because the author didn’t use the celebrity database and people are having a hard time replicating their results. I’m curious about your experience.