Ok, finished setting up fastai V1 in paperspace, I have some questions:
-When you install in dev mode (pip -e) how do you ensure that the fastai library is in the path everywhere in the enviroment, to be able to import from subfolders of different projects?
Now I have fastai installed directly in /home/
-The P4000 is pretty fast compared to the K80 available for free in colab and kaggle, but with less ram though, hope to abuse of half prec.
-Can I save an image of my install in paperspace to deploy to other macines ?
Please all note that ImageMask has been renamed ImageSegment (if you were using the class directly). Docs have been updated to reflect that change.
1 Like
FYI I traced my error down to the mask size not being resized along with the images.
eg a source (file) size 768x768 with sz=256 data.train_ds[1] returns (Image (3, 256, 256), ImageSegment (1, 768, 768)) then fit/lr_find fails. But it works with sz=file_sz ie (Image (3, 768, 768), ImageSegment (1, 768, 768)). Shouldn’t the y mask be resized alongside x with transform_datasets ? In the meantime manual resizing is fine.
Are you sure you put tfm_y=True?
Is this issue fixed? I am facing the same error while implementing multi-label. Without the augmentations, the code works, however, when i apply transformations, i get the same error
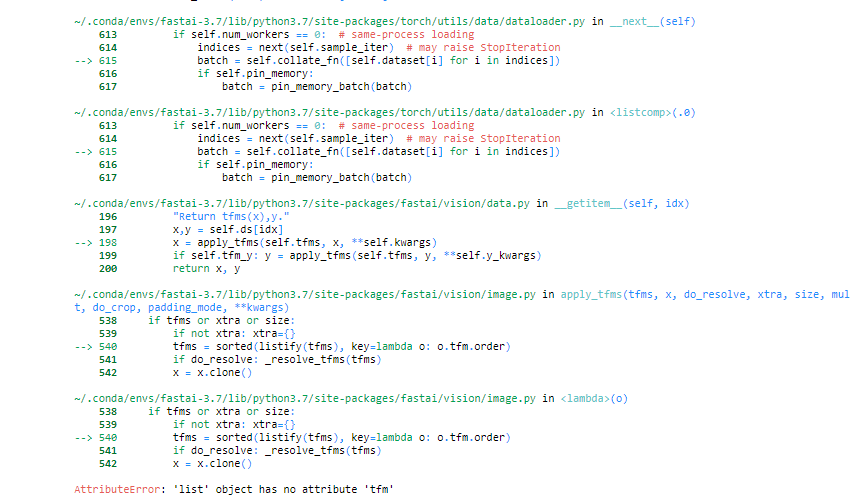
Here is the code:
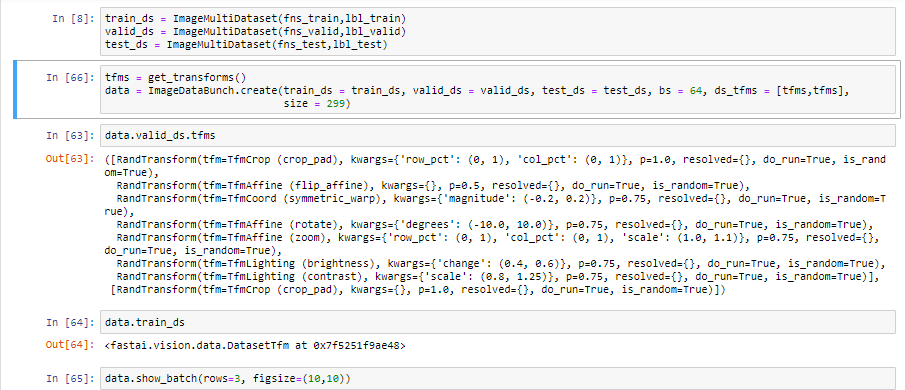
Just pass tfms and not [tfms,tfms]: tfms is already a list of two lists for training and validation 
Using just tfms gives the following list mismatch error:
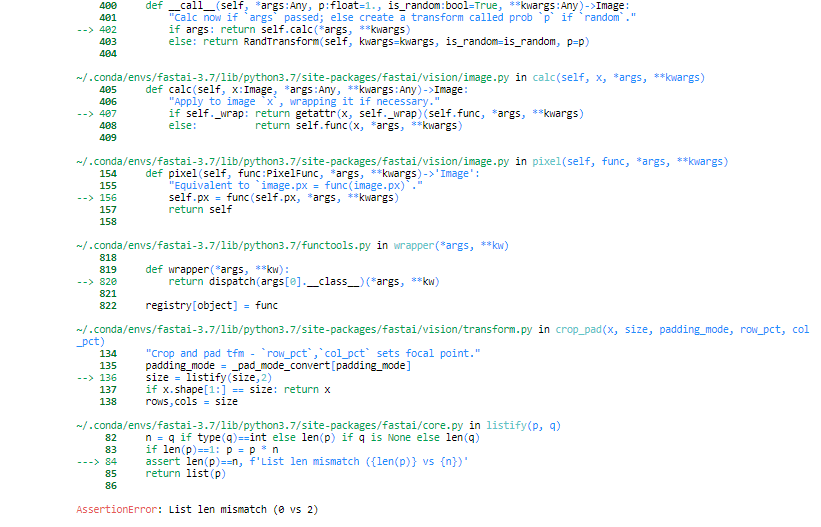
Maybe i am doing something wrong here, not sure where though
I think you didn’t pass a size (there is a crop in the random transforms). You had it in your previous call but you didn’t show the code for this one so I can’t be sure (and this is the exact error message I get when I forget to put it).
1 Like
Yeah forgot the size parameter. It worked just fine! Thank you for the fast response 
1 Like
Hi guys,
I am trying to implement this unet notebook https://github.com/fastai/fastai_docs/blob/master/dev_nb/006a_unet.ipynb on my own data, and keep receiving errors when trying find the learning rate:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 exception = e
---> 93 raise e
94 finally: cb_handler.on_train_end(exception)
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
82 xb, yb = cb_handler.on_batch_begin(xb, yb)
---> 83 loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)
84 if cb_handler.on_batch_end(loss): break
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
24 if opt is not None:
---> 25 loss = cb_handler.on_backward_begin(loss)
26 loss.backward()
~/anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_backward_begin(self, loss)
223 for cb in self.callbacks:
--> 224 a = cb.on_backward_begin(**self.state_dict)
225 if a is not None: self.state_dict['last_loss'] = a
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in on_backward_begin(self, smooth_loss, **kwargs)
255 if self.pbar is not None and hasattr(self.pbar,'child'):
--> 256 self.pbar.child.comment = f'{smooth_loss:.4f}'
257
~/anaconda3/lib/python3.7/site-packages/torch/tensor.py in __format__(self, format_spec)
370 if self.dim() == 0:
--> 371 return self.item().__format__(format_spec)
372 return object.__format__(self, format_spec)
RuntimeError: CUDA error: device-side assert triggered
During handling of the above exception, another exception occurred:
RuntimeError Traceback (most recent call last)
<ipython-input-26-d81c6bd29d71> in <module>()
----> 1 learn.lr_find()
~/anaconda3/lib/python3.7/site-packages/fastai/train.py in lr_find(learn, start_lr, end_lr, num_it, stop_div, **kwargs)
25 cb = LRFinder(learn, start_lr, end_lr, num_it, stop_div)
26 a = int(np.ceil(num_it/len(learn.data.train_dl)))
---> 27 learn.fit(a, start_lr, callbacks=[cb], **kwargs)
28
29 def to_fp16(learn:Learner, loss_scale:float=512., flat_master:bool=False)->Learner:
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
159 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
160 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 161 callbacks=self.callbacks+callbacks)
162
163 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 exception = e
93 raise e
---> 94 finally: cb_handler.on_train_end(exception)
95
96 loss_func_name2activ = {'cross_entropy_loss': partial(F.softmax, dim=1), 'nll_loss': torch.exp, 'poisson_nll_loss': torch.exp,
~/anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_train_end(self, exception)
254 def on_train_end(self, exception:Union[bool,Exception])->None:
255 "Handle end of training, `exception` is an `Exception` or False if no exceptions during training."
--> 256 self('train_end', exception=exception)
257
258 class AverageMetric(Callback):
~/anaconda3/lib/python3.7/site-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
185 "Call through to all of the `CallbakHandler` functions."
186 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 187 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
188
189 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:
~/anaconda3/lib/python3.7/site-packages/fastai/callback.py in <listcomp>(.0)
185 "Call through to all of the `CallbakHandler` functions."
186 if call_mets: [getattr(met, f'on_{cb_name}')(**self.state_dict, **kwargs) for met in self.metrics]
--> 187 return [getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs) for cb in self.callbacks]
188
189 def on_train_begin(self, epochs:int, pbar:PBar, metrics:MetricFuncList)->None:
~/anaconda3/lib/python3.7/site-packages/fastai/callbacks/lr_finder.py in on_train_end(self, **kwargs)
45 # restore the valid_dl we turned of on `__init__`
46 self.data.valid_dl = self.valid_dl
---> 47 self.learn.load('tmp')
48 if hasattr(self.learn.model, 'reset'): self.learn.model.reset()
49 print('LR Finder complete, type {learner_name}.recorder.plot() to see the graph.')
~/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in load(self, name, device)
195 "Load model `name` from `self.model_dir` using `device`, defaulting to `self.data.device`."
196 if device is None: device = self.data.device
--> 197 self.model.load_state_dict(torch.load(self.path/self.model_dir/f'{name}.pth', map_location=device))
198
199 def pred_batch(self, is_test:bool=False) -> Tuple[Tensors, Tensors, Tensors]:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in load(f, map_location, pickle_module)
356 f = open(f, 'rb')
357 try:
--> 358 return _load(f, map_location, pickle_module)
359 finally:
360 if new_fd:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _load(f, map_location, pickle_module)
527 unpickler = pickle_module.Unpickler(f)
528 unpickler.persistent_load = persistent_load
--> 529 result = unpickler.load()
530
531 deserialized_storage_keys = pickle_module.load(f)
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in persistent_load(saved_id)
493 if root_key not in deserialized_objects:
494 deserialized_objects[root_key] = restore_location(
--> 495 data_type(size), location)
496 storage = deserialized_objects[root_key]
497 if view_metadata is not None:
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in restore_location(storage, location)
376 elif isinstance(map_location, torch.device):
377 def restore_location(storage, location):
--> 378 return default_restore_location(storage, str(map_location))
379 else:
380 def restore_location(storage, location):
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in default_restore_location(storage, location)
102 def default_restore_location(storage, location):
103 for _, _, fn in _package_registry:
--> 104 result = fn(storage, location)
105 if result is not None:
106 return result
~/anaconda3/lib/python3.7/site-packages/torch/serialization.py in _cuda_deserialize(obj, location)
84 'to an existing device.'.format(
85 device, torch.cuda.device_count()))
---> 86 return obj.cuda(device)
87
88
~/anaconda3/lib/python3.7/site-packages/torch/_utils.py in _cuda(self, device, non_blocking, **kwargs)
74 else:
75 new_type = getattr(torch.cuda, self.__class__.__name__)
---> 76 return new_type(self.size()).copy_(self, non_blocking)
77
78
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch-nightly_1540726045570/work/aten/src/THC/generic/THCTensorCopy.cpp:20
My code is as follows:
from fastai import *
from fastai.vision import *
torch.backends.cudnn.benchmark=True
torch.cuda.set_device(0)
PATH = Path('../data')
TRAIN = PATH/'train'
MASKS = PATH/'masks'
arch = models.resnet34
sz = 256
bs = 16
cut, split = learner.model_meta[arch]['cut'], learner.model_meta[arch]['split']
df = pd.read_csv(PATH/'train_segmentations.csv')
DATA_LEN = len(df)
FILE_NAMES = df['Image'].tolist()
def get_datasets():
x_fns = [TRAIN/x for x in FILE_NAMES]
y_fns = [MASKS/x for x in FILE_NAMES]
mask = [o >= np.round(DATA_LEN / 3) for o in range(len(x_fns))]
arrs = arrays_split(mask, x_fns, y_fns)
return [SegmentationDataset(*o, classes=2) for o in arrs]
def get_tfm_datasets(size):
datasets = get_datasets()
tfms = get_transforms(flip_vert=True)
return transform_datasets(*datasets, tfms=tfms, tfm_y=True, size=size, padding_mode='border')
default_norm, default_denorm = normalize_funcs(*imagenet_stats)
def get_data(size, bs):
return DataBunch.create(*get_tfm_datasets(size), bs=bs, tfms=default_norm)
data = get_data(sz, bs)
body = create_body(models.resnet34(True), -2)
model = models.DynamicUnet(body, n_classes=2)
inp = torch.ones(1, 3, sz, sz)
out = model(inp.cpu())
model = model.cuda()
metrics = [accuracy, dice, Fbeta]
loss_func = CrossEntropyFlat()
learn = Learner(data, model, metrics=metrics, loss_func=loss_func)
learn.lr_find()
Thanks for any hints!
2 Likes
I am getting the same error. Check out the Jupyter log. It will show the actual error. In my case I am getting Assertion t >= 0 && t < n_classes failed. error. I think it’s happening because I just have 1 class in the dataset. I tried passing single class to SegmentationDataset and also tried with sending classes=['background', 'cat'] but still getting the same error. My masks are RLE Encoded and I am savng them to disk using this code: PIL.Image.fromarray(np.uint8(arr * 255) , 'L').save() @sgugger please provide some insights on how to debug/fix this issue?
2 Likes
I am getting the same error with the similar Unet code (pretty much the same) on my own dataset. Were you able to resolve the issue?
I haven’t been able to resolve it. I am hoping we get some lead soon.
1 Like
To clarify, I am getting specifically @pypl’s error. @dsr, do you have empty masks? Addressing how I handled empty masks resolved that specific error for myself.
I may have some empty or corrupted masks. Will remove and check. But I suspect it’s the way I have saved the mask that’s causing the issue, as the error is thrown as soon as training starts. The mask information is RLE encoded and I decoded them and saved to disk. I suspect there’s some bug. I will save mask using fastai’s RLE functions and will let you know if it fixes the issue.
@Jamie @dsr Not sure, but making masks with labels less than 255 might help. e.g. 0 and 1 for two classes
1 Like
I fixed the issue by passing div=True and 2 classes in the SegmentationDataset. For details please refer to this thread: https://forums.fast.ai/t/unet-binary-segmentation/29833
I was sending this param earlier also but missed passing 2 classes to the SegmentationDataset. We need to pass 2 classes when we have just one object in the mask. My fixed code looks like this:
data = (src.datasets(SegmentationDataset, classes=['background', 'cat'], div=True)
.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=batch_size)
.normalize(imagenet_stats))
1 Like
Thank you! That was the solution. Load the masks so that the points were 1 instead of 255.
The classes is indexing from 0 in the mask images, until the (num_classes - 1)
For example, if you have one class to be recognized. Put these pixels are 1 but the rest is 0 values. That the reason you need to put two classes labels: 0 for background, 1 for your class.