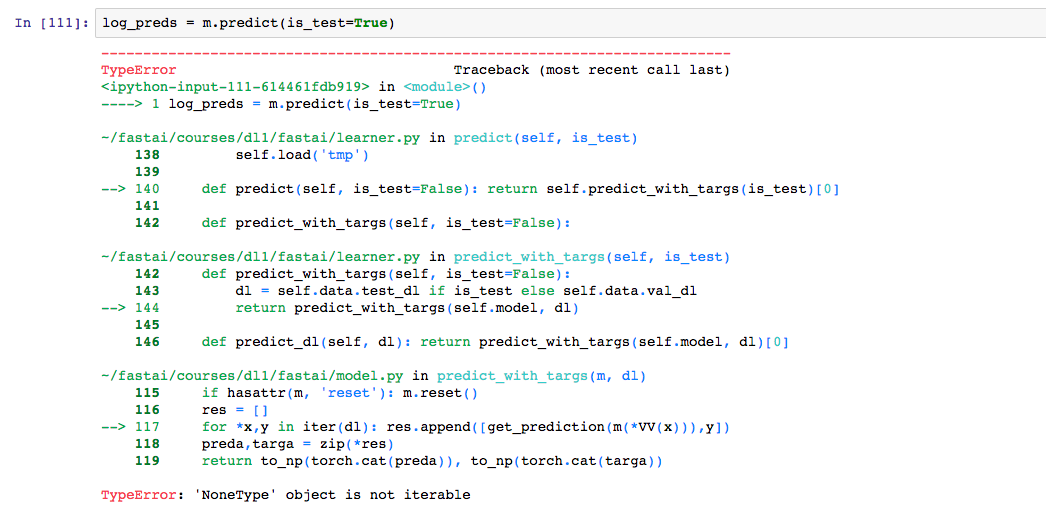
Hi @poppingtonic , I trained the model, and am able to get predictions on the validation set.
On the test test, I tried running this
log_preds = m.predict(is_test=True)
If you have any suggestions, please do let me know and will try it out…
Thank you!
1 Like
memetzgz
November 25, 2017, 3:23pm
5
I’ve gotten this error when I have forgotten to specify where the test images are.
you’re supposed to specify it during the initial data specification, e.g.:
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz), test_name=‘test’)
You don’t have to redo everything to add the test name in after the fact.
I saved this from another thread, can’t find where so cannot properly give attribution, unfortunately:
To run predictions on test when you forgot to specify test
rerun data=… with test_name=‘test’ :
run : learn.set_data(data)
then, you can run : log_preds,y = learn.TTA(is_test=True)
6 Likes
ecdrid
November 25, 2017, 9:13pm
6
In order to correct this error…
Head over to the learn where you created the learner…
It’s missing the test_folder_name…
ecdrid
November 25, 2017, 9:14pm
7
Didn’t know about set_data()?
THanks @memetzgz
Going to try this out now.
Had a question:
log_preds,y = learn.TTA(is_test=True)
TTA is applying test time augmentation.
Edit: Jeremy has added the test set process to the notebook Structured Learner
pnvijay
November 30, 2017, 8:28am
9
I have been trying to understand the join_df function.
def join_df(left, right, left_on, right_on=None, suffix=’_y’):
joined = join_df(joined, googletrend, [“State”,“Year”, “Week”])
what does [“State”,“Year”, “Week”] signify here? Is it left_on?
pnvijay:
“State”,“Year”, “Week”
[“State”,“Year”, “Week”] are the columns which are present on both joined & googletrend, based on which the merge happens.
Maybe this will help.
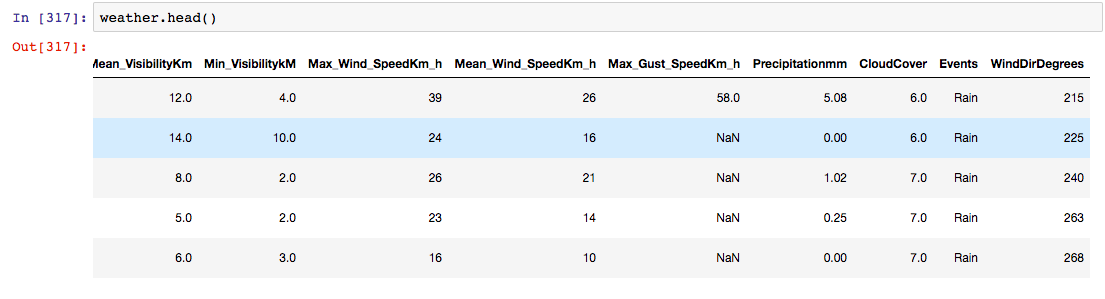
This is how weather looked before join_df.
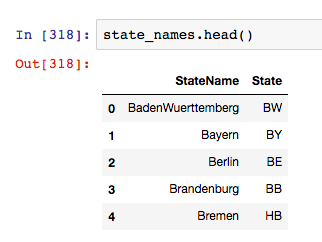
This is how state_names looked before join_df
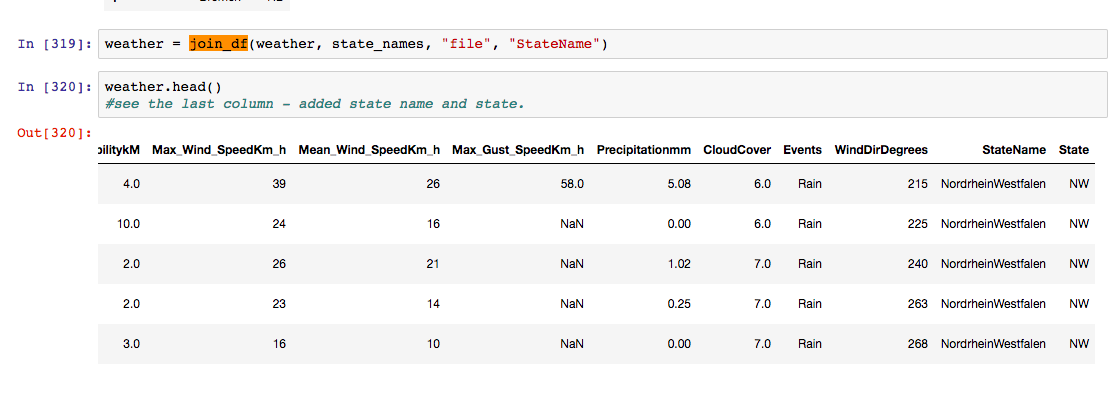
This is the output file -
You can see the new columns added on the right after merge.
1 Like
pnvijay
November 30, 2017, 9:05am
11
Thanks Arjun! I was doing the same that you have highlighted in the reply in my Jupyter notebook. I understand this now. But what are the reasons based on which these joins are happening? is it to create one big data frame that has all of the data in the various Csv sheets logically correlated together?
pnvijay
November 30, 2017, 9:18am
12
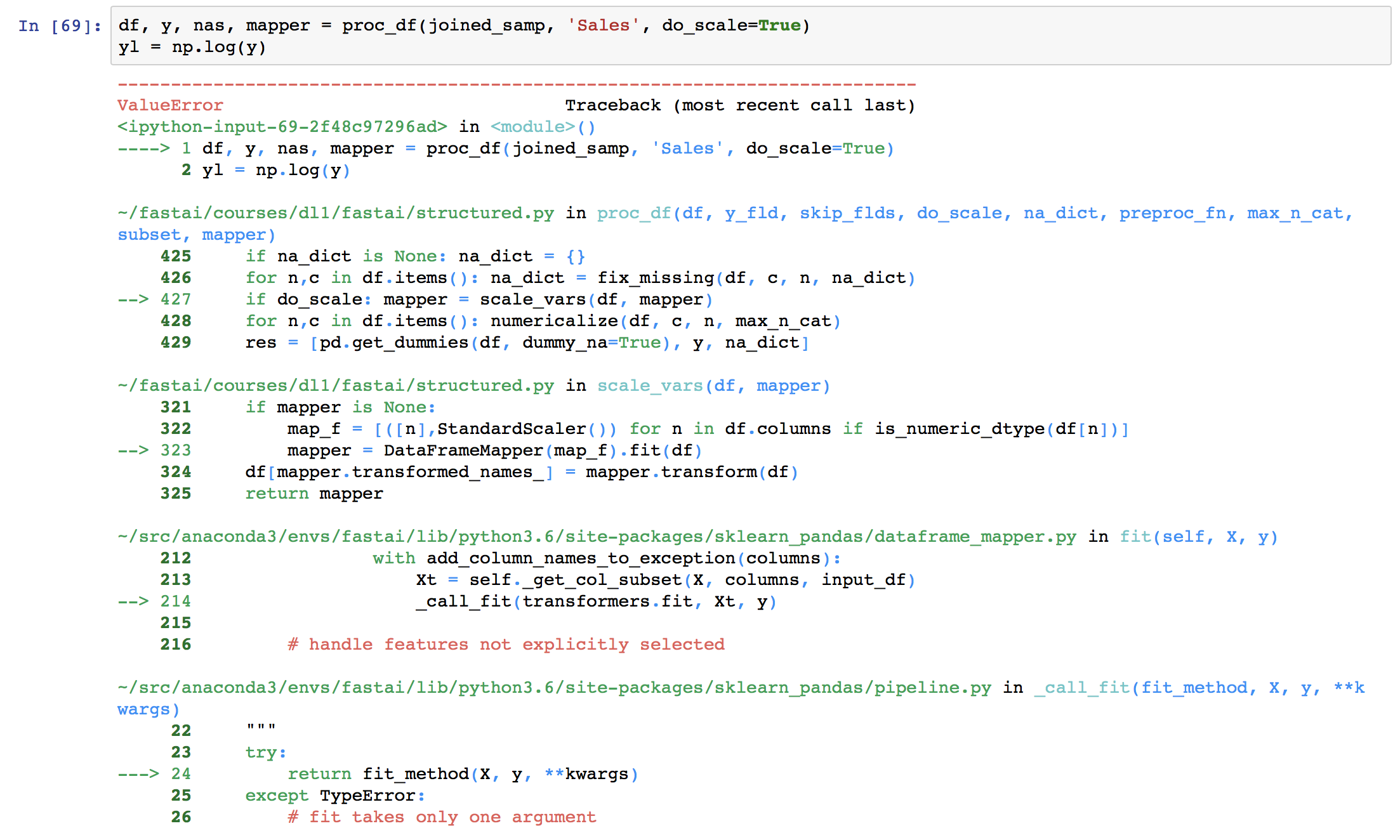
I am also getting this error when I run the rossmann notebook. Should I drop the index_col?
pnvijay
November 30, 2017, 9:30am
13
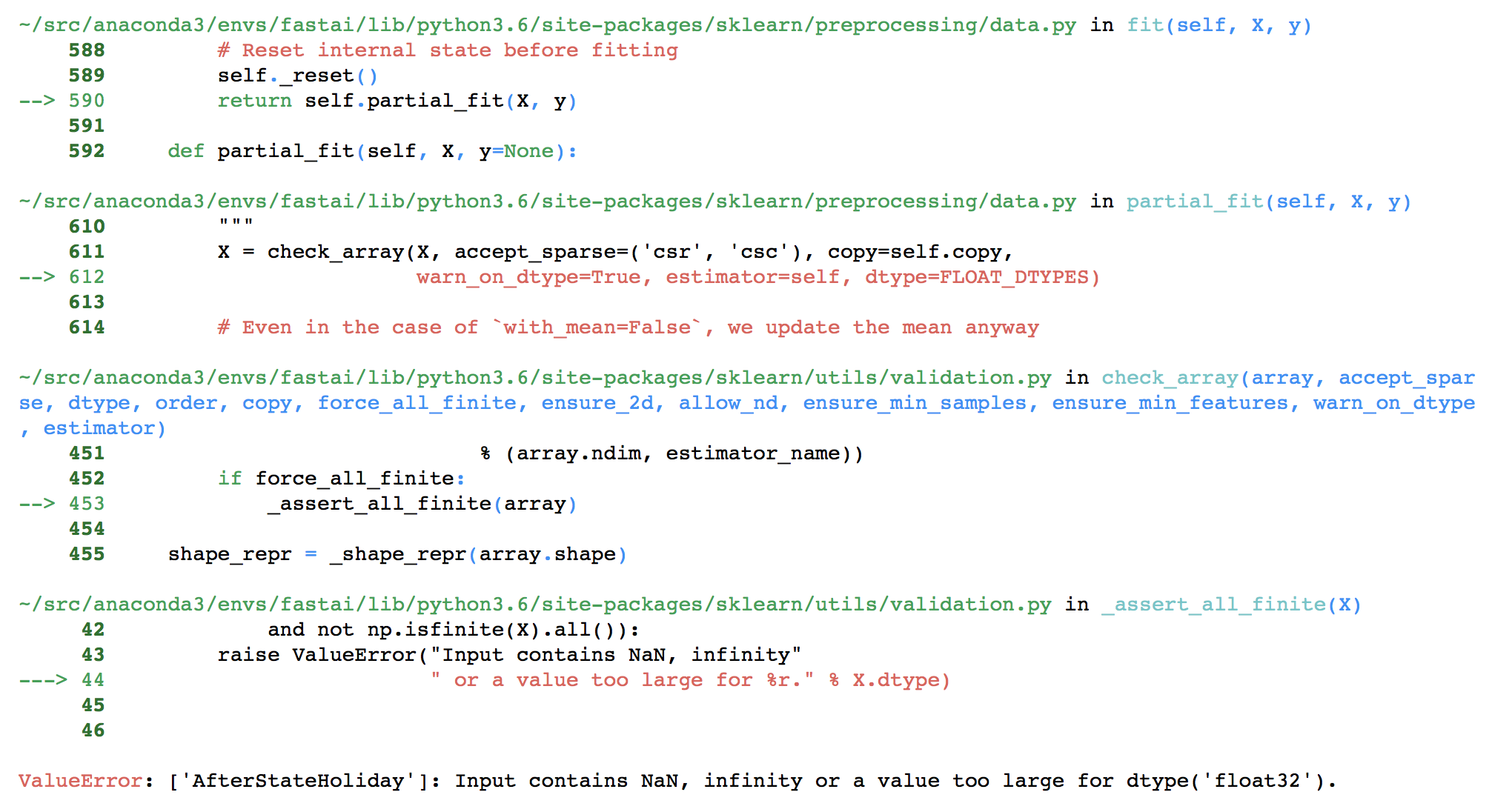
I removed index_col = 0 and went ahead. But now I am getting this error
Can I proceed even with this error?
You should check this thread - similar error :
pnvijay
November 30, 2017, 9:47am
16
Thanks Arjun! ‘AfterStateHoliday’ is a continuous variable. The error states that [‘AfterStateHoliday’]: Input contains NaN, infinity or a value too large for dtype(‘float32’). Not Sure how to handle this.
pnvijay
November 30, 2017, 9:54am
17
Looks like there is a ‘NaN’ in every row of the data frame AfterStateHoliday. Should we remove it from all the rows?
pnvijay
November 30, 2017, 12:27pm
18
I now understand where I have gone wrong. It is in using df the same for test and train for columns. will rectify that and check.
2 Likes
pnvijay
December 1, 2017, 6:40am
19
Thanks all. I completed my submission to the rossmann challenge and got a score of 0.10964 on public leaderboard and 0.12644 on private leaderboard.
1 Like
pnvijay
December 7, 2017, 10:18am
21
Hi Jeremy, During the lecture that your were able to achieve scores around 0.10 in both private and public leaderboard in this competition. It would be great to understand from you as to what things are needed to be done to improve on my current scores.
jeremy
December 7, 2017, 5:03pm
22
If you follow what I did in the notebook you’ll get the same score as me
2 Likes
pandeyaah
February 8, 2018, 5:12am
23
Got a score of 0.10342 in leaderboard. Thank you.