Oh right, this paper is a year old…guess I forgot we are in a cutting edge DL class 
Some comparison on these lines with current architectures might be a good idea.
A fresh (26 March 2018) paper from Leslie Smith (author of cyclical learning rates).
Even though I’ve just 5-minute-skimmed it, it seems to be a very practical and quite easy to read piece.
10 Likes
Fantastic. This attempt to see how pieces of the training puzzle interact is really insightful, and scarce.
His proxy for superconvergence, learning rate policy “1cycle”, is easy to replicate with fast.ai cycle_len and cycle_mult, (it implies always using only two cycles, though) quoting:
Here we suggest a slight modification of cyclical learning rate policy for super-convergence; always
use one cycle that is smaller than the total number of iterations/epochs and allow the learning rate to
decrease several orders of magnitude less than the initial learning rate for the remaining iterations.
We named this learning rate policy “1cycle” and in our experiments this policy allows the accuracy
to plateau before the training ends.
Also regularizing effect of lr size and bach size, sample + parameter dependency of regularization…
it is all there!
Even if you implement a Bayesian optimizer, that I have used in the past, you still need to
understand as much as possible this interactions to tune that optimizer, imo this is priceless.
Thank you for sharing! 
One cycle, not two cycles 
Oh, reason why I thought 2 cycles was mention of choosing “one cycle smaller than total number of epochs”, and then referal to learning rate for “remaining iteratios”. If there are “remaining iterations” we must need another cycle to complete that "total number of epochs?
So my assumption was cycle1 , cycle2 + cycle_mult so that cycle2 = remaining interations…
But being the name of the trick “rate policy 1 cycle” it would make more sense to be 1 cycle… Though then don’t get how that can fit with a “smaller than total number of epochs” cycle length.
I guess I better re-read that paragraph some more times… 
I found the paragraph confusing too. I asked Leslie to include an image, but didn’t have time. So I’m still not 100% sure what he means. But I think the single cycle use_clr we have is at least pretty close to his intention - but perhaps not identical.
2 Likes
My initial contribution to part 2 , ahem …
I am currently hooked into reinforcement learning , sorry for that.This is the classic Alpha Go paper, it uses convolutional neural network to train known Go games. And then uses that knowledge as prior to train two different network, policy and value network. The job of these two networks is then to self play and improve and ultimately beat human players.
David Silver primary author of this paper and the guy who does lot of important things at Deepmind , gave a nice tutorial of this paper here.
The next iteration of their work introduced AlphaGo Zero - which didn’t require human knowledge as prior to train.It will be another classic paper if you are into reinforcement learning.
1 Like
Going through some random Reddit thread, I’ve stumbled upon the marvellous paper titled
Stopping GAN Violence: Generative Unadversarial Networks. When the first author’s institution is called “Institute of Deep Statistical Harmony”, you know it’ll be a good read
5 Likes
@mmr have you seen this article: https://www.alexirpan.com/2018/02/14/rl-hard.html , it might help break a bit with RL, besides it is a good read.
1 Like
Well, I am fond of the research solutions that deepmind and openai often comes up with. And about the efficiency of RL algorithms in solving problems, I know its hard, that’s why I am interested in it. There are still room for improvement in RL.Also personally its my early days with RL, so let’s see.
Thanks for great thread!
Here is one particularly good and new article:
Even though it’s been already discussed in details in Implementing Mask R-CNN I think it’s worth mentioning
1 Like
This has to be the funniest thing I have ever read. Thanks!
Adversarial Patch
Adversarial Logit Pairing
Optimizing Neural Networks with Kronecker-factored Approximate Curvature
K-FAC: Kronecker-Factored Approximate Curvature
1 Like
@mmr:
I did a talk on the Alpha Go series of engines the other day, you might find it interesting:
Starts ~20 minutes in, the audio is rough for the first 5-10 minutes, sorry.
Slides:
3 Likes
A illustrative fully coded nlp attention example from Harvard NLP group.
http://nlp.seas.harvard.edu/2018/04/03/attention.html
4 Likes
Thanks.
By the way, if you post the arxiv abstract link, e.g.
https://arxiv.org/abs/1703.06870
instead of the paper PDF, e.g.
https://arxiv.org/pdf/1703.06870.pdf
then that makes it easier for people who use Mendeley to store their bibliographic references. (Yes, you can get from one to the other by replacing pdf with abs, but you have to remember that’s how you do the transform.)
Thanks!
3 Likes
Read the YOLOv3 paper today. It was awesome, and definitely wish more papers were like that 
Also just read the paper on FitLaM (by @jeremy and @sebastianruder). It was an awesome read too, and I could barely contain myself as I read it. I hope we’ll see a lot more of that, especially with tasks such as machine-translation.
I did want to mention, though, that I could not find the result of the ablation studies in the paper at here (https://arxiv.org/pdf/1801.06146.pdf). This is briefly alluded to at https://www.youtube.com/watch?v=_ercfViGrgY&feature=youtu.be (This is basically 1:57:03 on Lesson-10). I’ve also included a screenshot.
I got particularly interested in that the validation error was 5.63 (w/out pretraining) vs 5.00 (w/ pretraining) for the IMDB task. Does that mean that we only gained .63% reduction in the error with a pretrained model on wikipedia?
I’m probably just missing something. At any rate, great job guys! Also @sebastianruder, if you just need someone to help with your ablation studies, feel free to directly message me. I’ve got a 2 x GTX 1080Ti machine pretty much eating dust at about this time. Furthermore, I’d be very interested to do some more experimental research on the application of the the FitLam (or ULMFit, whatever you’re calling it now ) on more kinds of NLP tasks. Let me know … email is apil.tamang@gmail.com
Screenshot of the ablation studies I’m referring to:
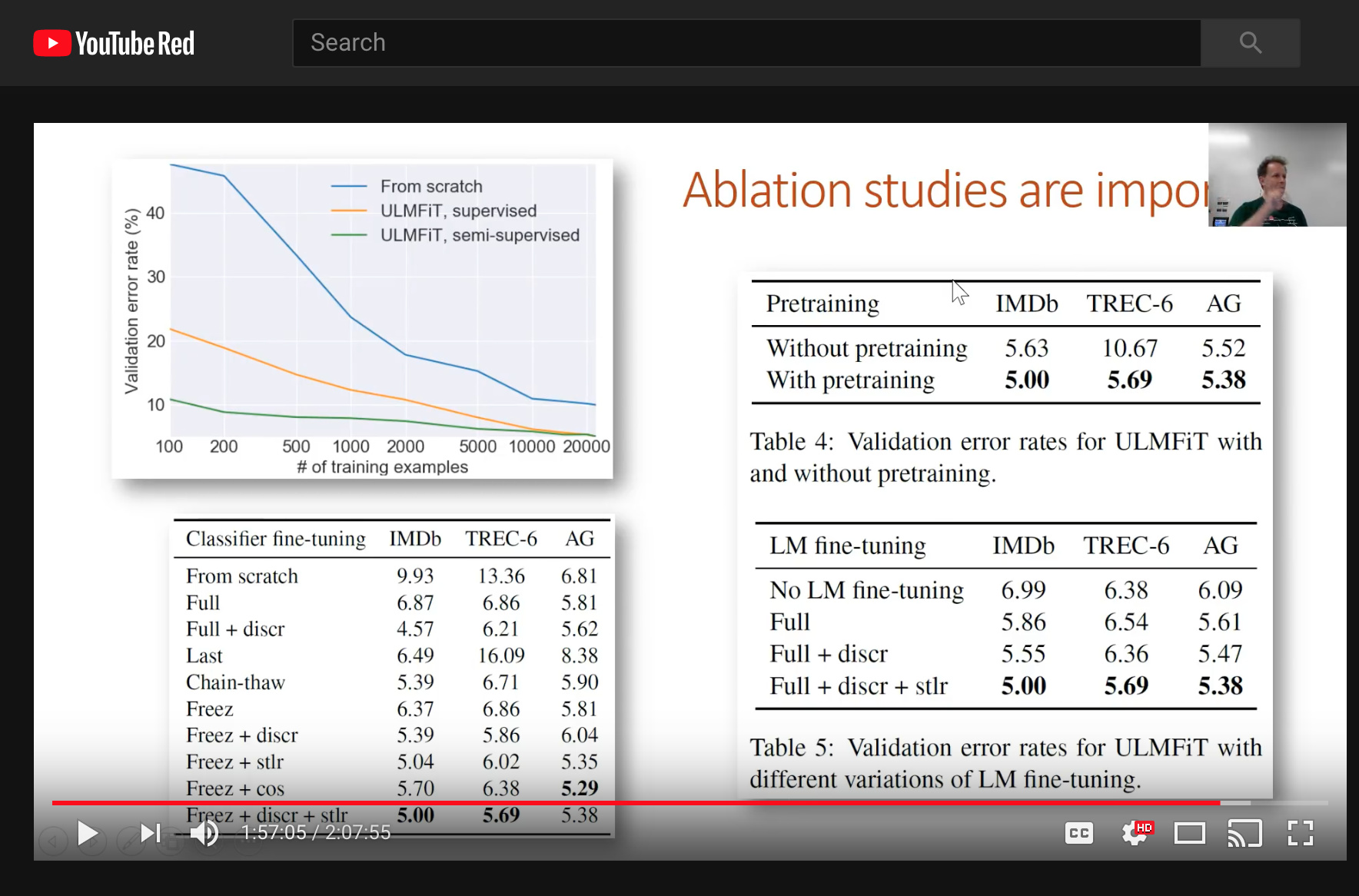
2 Likes
Ah remember to be very careful of how you interpret errors. You want to look at relative improvement. It’s about a 12% relative improvement. Or alternatively thing about the % change in the number of incorrect classifications (which is the same number - just another way of saying the same thing).
The benefit is greater for smaller datasets - as you can see from the TREC-6 result and from the top left chart in your image.
The paper with the ablation studies in isn’t out yet. Hopefully in 3 weeks or so we’ll be able to make it available. But I tried to make all the key bits of info available in the video.