The last survey showed that quite a few people are having trouble understanding how keras is used to implement models. I know from chatting to a couple of you that learning python is part of this challenge. I’m planning to create some introductory python data science videos that you can use to help get up and running with the basic python skills and tools you need.
It would help me a lot to do a reasonable job of this if I have some experience answering questions about this topic. There hasn’t really been many (any?) questions about python and keras syntax and methods on the forums yet - so I’m hoping that creating this topic will encourage some questions; I’m especially interested in python beginner’s questions.
I’ll start with a tip. If you want to know how some python function or method works, just precede it with a ‘?’ in jupyter notebook, like so:
Since I did not find any other thread dealing with questions specific to Pandas, I am posting here.
I am not very experienced with Pandas and hence am trying out various things for learning.
I have a text file(~3GB) with the dataset, however I am only reading the first n rows using pandas.read_table by setting nrows parameter. This works pretty fast even for 300000 rows.
After this, I need to transform the data and am doing this using pivot_table. Now, this is where I am currently facing an issue. Everything works fine when I do this for upto 60000 rows. After that, pivot_table causes a crash. Not just the script, but the computer itself crashes.
I have tried several things so far- like using pivot(also crashes), manually transforming the data(this however doesn’t get the data in the exact desired format). I also tried using numpy.genfromtext. However, in that case, transformation becomes more complicated as there are non-numeric indices.
I would be interested to know of any tips or solutions to handle this performance issue of pivot_table.
I’m guessing you’re running out of RAM. That would explain the whole machine crashing. Can you please share the pivot command you are running, and tell us the number of distinct items that will be in each of your rows and columns? Because pivot() creates an exponentially large dataset (product of # distinct / column) you need to be careful of what you ask pandas to do!
@vshets - I already had a look at the link, but could not use a similar approach because if I break down into chunks, then I will have to manually do the transformation which is a lot more processing than this. But yes, I would definitely be interested if there is a way to avoid pivot and use an alternative.
@jeremy - The dataset is in the format of a text file, where each line contains one triplet (field1, field2, field3), and overall has:
• 1,019,318 unique items in field1
• 384,546 unique items in field2
So a sample of data would look like this
abc s1 9
xyz s2 1
pqr s3 189
abc s2 3
And I need to transform it to the following:
s1 s2 s3
abc 9 3 NaN
xyz NaN 1 NaN
pqr NaN NaN 189
Ah well that explains it! Your table would be of size 1,019,318 * 384,546 , which is going to more than fill up your RAM…
Why are you trying to create this crosstab? It’s far far bigger than any human could look at in an entire lifetime, so I assume it’s because you want to analyze it with some tool. Any such tool is likely to work better with the raw data, rather than the crosstab.
If you’re just trying to look at a subset of the data in crosstab form, see my lesson4 notebook Excel export section to see how to select a subset of data to pivot.
@jeremy - Sorry. Those unique items are in the entire file, which is around 3GB. I am only trying to look at about 300000 lines. So that would approximately be 7000 * 25000, which I feel should be okay.
Should pivot not work for this? Are there any other alternatives that I could consider for the crosstab?
@jeremy - true It is actually part of a project task in one of my courses at University.
The task is to use the system that works well on known (field1, field2) ratings, train the model and then test it on the unknown ratings.
On the crosstab, Alternating Optimization needs to be applied using Latent Factor Models.
Later, to evaluate the model, RMSE(Root Mean Square Error) will be computed on the test set.
You don’t want to create a crosstab to create a latent factor model. Take a look at our lesson4 notebook - the only time we create a crosstab is the show a demo in Excel; the actual keras model uses the raw ratings table.
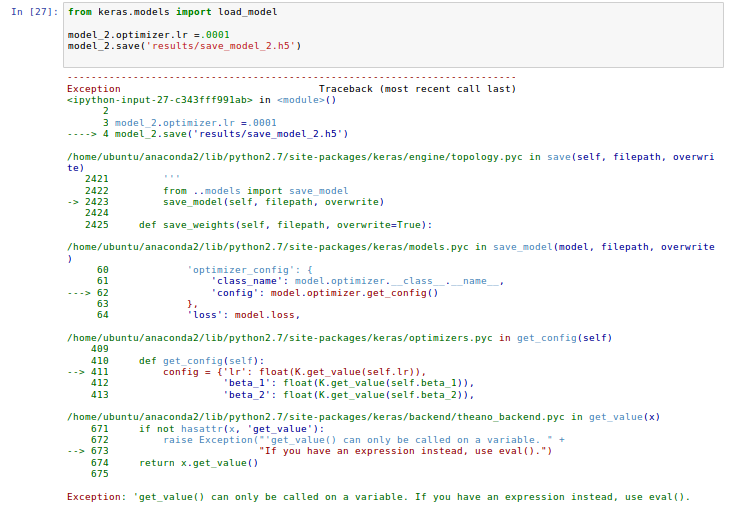
did anyone have problems saving their model with keras? I’m getting an error where the save function can’t seem to grab the learning rate despite being very explicit about setting it.
I can save the model architecture as a json and the weights separately, but i’d like to keep the model’s optimizer state so I can shut down the server and start again. Even if the function isn’t getting the learning rate I set, there is a default value so I’m wondering why get_config() is raising an exception. Thanks for any help!
Great question. The officially correct way to set the learning rate is:
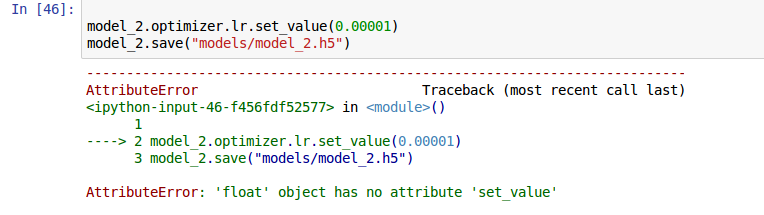
model.optimizer.lr.set_value(0.0001)
whereas in my code I’ve tended to use:
model.optimizer.lr = 0.0001
If you use my approach, you can’t save the model using save(), although you can still save_weights(). Since I only use the latter, I’d never noticed this problem before. Sorry about that! You might want to stick to using set_value() when setting the learning rate
I did read that forum topic in regards as part of troubleshooting; I thought the final verdict was that how one set the learning rate was a matter of preference. But now I guess we know a little better. thanks for your patience!
@jeremy I was going through your statefarm-sample notebook (after I tried my own…) and have several questions.
It gave me an error when I did
"model.compile(Adam(), loss=‘categorical_crossentropy’, metrics=[‘accuracy’])"
telling me that Adam is not defined. I went to the Keras website and corrected it to
"model.compile(optimizer=‘adam’, loss=‘categorical_crossentropy’, metrics=[‘accuracy’])"
and it was fine. I am simply wondering why your command didn’t work for me in case there is something interesting going on.
What is the difference between model.fit and model.fit_generator (the latter was used in your statefarm notebook)? I see keras does not have the function fit_generator, so was fit_generator defined in util which we imported at the very beginning?
I would also like to know where the function get_batches from? Is it from util class as well?
Why is that in the validation batch, batch_size is twice as much?
Thank you and @rachel for all the good work. Merry Christmas!

 It is actually part of a project task in one of my courses at University.
It is actually part of a project task in one of my courses at University.