Thanks
Hey guys,
I stumbled upon this thread while searching for inspiration on the web, as I’m also trying to implement yolov3 from scratch on pytorch. I have to say, the implementations I’ve found here are indeed much more understandable and straightforward then other ones I’ve found.
However, I can’t seem to wrap my head around why there are no route layers on the implementations listed here. Moreover, the original yolov3 paper doesn’t mention the existence of such layers (see table 1 on the paper), even though they are mentioned in the cfg file on the authors github.
Can any kind soul provide me some clarification?
Thanks in advance!
Hey Antonio, the discussion here refers to just the convolutional base of YOLOv3, which is Darknet-53. The route layers are for constructing the U-net/feature pyramid network that sits on top of the Darknet-53 base. Hope that helps.
I’m working on a full implementation of YOLOv3 in fastai v1. Has anyone managed to get the pre-trained Darknet-53 weights into the fastai implementation of Darknet? I’d like to avoid training the network from scratch.
Ben, I would look at https://github.com/ayooshkathuria/pytorch-yolo-v3/blob/master/README.md
They read in the weights from darknet. There is also a good blog on paperspace that explains things to go with it. The other repo to look at is
https://github.com/DeNA/PyTorch_YOLOv3/blob/master/README.md
It implements training with transfer learning from the darknet weight files.
After spending many hours trying to understand Darknet-53 and the fastai implementation of it, I discovered this thread which was fun to read through because it addressed a lot of the questions I had while looking through it. E.g. why it’s called Darknet-53. Here’s how I explain it to myself: the darknet53 config file shows that, after the global avg pool layer at the end of the feature extractor, a 1x1 convolutional layer with 1000 filters is used to transform the 1024 features after the final residual connection into the 1000 in the ILSVRC; they basically replace a flatten->dense with a conv.
My question is about the current fastai implementation of Darknet-53, in particular this part in the Darknet init:
layers = [conv_bn_lrelu(3, nf, ks=3, stride=1)]
for i,nb in enumerate(num_blocks):
layers += self.make_group_layer(nf, nb, stride=2-(i==1))
nf *= 2
layers += [nn.AdaptiveAvgPool2d(1), Flatten(), nn.Linear(nf, num_classes)]
self.layers = nn.Sequential(*layers)
Why is the stride set to 2-(i==1)? That means that the second “group layer” (the 128 filter layer if nf=32) has a stride of 1 while the rest of the group layers start with a stride of 2, downscaling the spatial resolution while increasing the number of filters. If it was 2-(i==0) it would get rid of the stride 2 in the 1st “group layer” rather than 2nd, which would presumably match Sylvain’s original implementation, but even that doesn’t seem to match what I see in Table 1 of the Yolov3 paper, which shows a stride of 2 at the start of every “group layer”. Here’s what I think it going on:
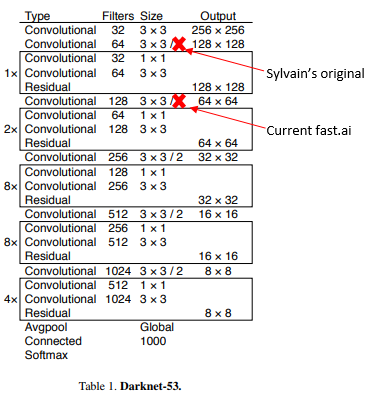
It seems to me that the for loop should be:
for i,nb in enumerate(num_blocks):
layers += self.make_group_layer(nf, nb, stride=2)
nf *= 2
Let me know if I’m on the right track.
1 Like
Thanks for the fix, Jason.
Hi Ben, did you manage to get the pretrained Darknet-53 weights into the fastai implementation of Darknet? Also, how did your YOLOv3 implementation in fastai v1 come about?
1 Like
Hii @kapil_varshney,
I’m looking for ways to implement yolov3, with darknet weights. Kindly share if you have found a solution.
Thank you,