I am working on a kaggle submission but I cannot actually predict the whole test.csv as I am getting an out of memory error for both learn.predict(is_test = True) and when trying to do it manually:
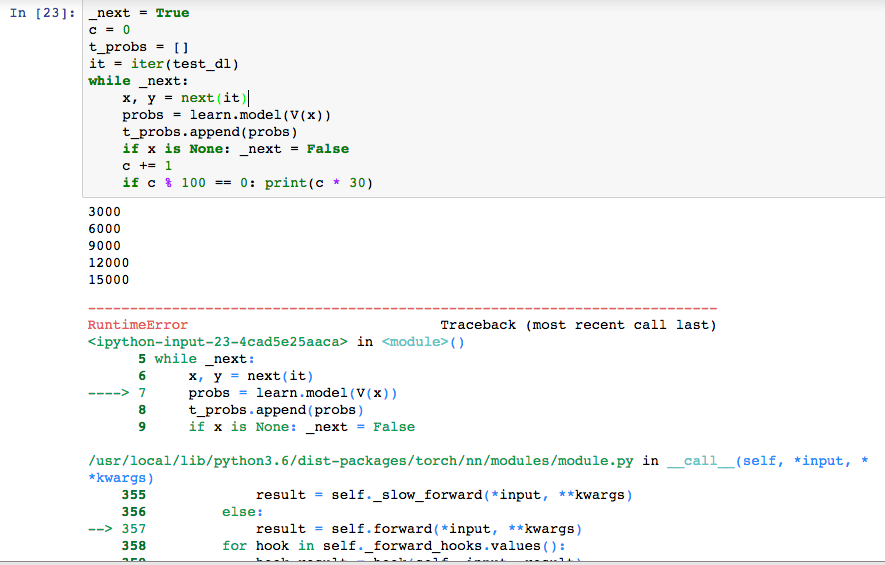
_next = True
c = 0
t_probs = []
it = iter(test_dl)
while _next:
x, y = next(it)
probs = learn.model(V(x))
t_probs.append(probs)
if x is None: _next = False
c += 1
if c % 100 == 0: print(c * 30)
I can see how it iterates over this loop about 500 times and then ends with a
RuntimeError: cuda runtime error (2) : out of memory at /pytorch/torch/lib/THC/generic/THCStorage.cu:58
in the forward method. It seems like gpu memory isn’t being freed between forward calls
Many thanks @sgugger!!! This version works now without OOM
learn.model.eval()
it = iter(test_dl)
while True:
x, y = next(it)
probs = to_np(learn.model(V(x)))
Calling predict, however, still runs out of GPU memory, but maybe it can’t really accomodate large datasets. My test set has about 500k rows, 300M of CSV.