Ha yeah, I had run into a separate issue where Torch wasn’t accessing my GPU properly (that’s why our errors are slightly different [torch.FloatTensor of size 64x17] vs [torch.cuda.FloatTensor of size 64x17 (GPU 0)]).
If you are operating with GPU you first need to switch the tensor to cpu before converting to a np array. This seems to work ok
def f2(preds, targs, start=0.17, end=0.24, step=0.01):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
return max([fbeta_score(targs.cpu().numpy(), (preds.cpu().numpy()>th), 2, average='samples')
for th in np.arange(start,end,step)])
@nithiroj I’ve had the same issue. I went into the ~/fastai/models.py line 43 and changed the y to call y.float() and same for line 54 to get it to work but not sure if that’s the right fix though. BinaryCrossEntrpopy expects a float tensor target and not a long tensor which is causing this error. But since this is a classification task it would make sense that our target is a one-hot encoded vector represented as a long tensor.
Hi every one,
I’ve found really instructive the Planet exercise in lesson 2. So I decided to focus on this dataset, while tackling a different (I believe relevant) problem:
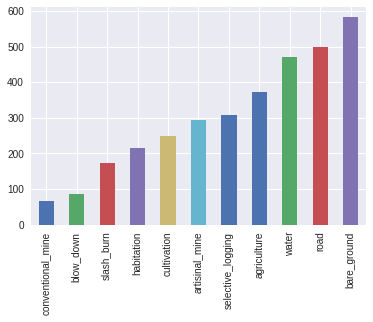
I think the F2 score proposed disregards how good are the models at classifying the minority labels, although these are most important to understand impacts on Amazonia (mining, logging, urbanization, roads, etc.).
The imbalance between classes is huge (the “clear” and “primary” labels appear more than 25000 times, whereas labels such “conventional_mine” only a hundred times or less). I think this imbalance cannot be fixed by oversampling the minority classes (as this will also create duplicates of the dominant ones).
So as a starting point, I focused only on images with “clear” weather and moreover, considered the forest as background, i.e. only selecting images where “primary” coexists with the rest of the labels (such that we do not need to care about "primary" anymore).
I ended up with a very small set of 2864 images. Still imbalanced, but at least following a linear distribution of classes (as opposed to exponential, see 1st Figure in Kernel https://goo.gl/241C2b).
For this small dataset, I followed the steps (leading to F2-scores above .9 in the original problem):
1) Start with small image sizes: sz=64.
2) Find learning rate for and fit (2 epochs, cycle_len=1, cycle_mult=2), leading to F2-score=0.7 (validation).
3) Enabling data augmentation and fitting (3 epochs, cycle_len=1, cycle_mult=2), F2=0.725
4) Unfreezing and training last layers ([lr/9,lr/3,lr], 3 epochs, cycle_len=1, cycle_mult=2), F2=0.728
5) Applying steps 2)- 4), but now using larger sizes, sz=128. I Achieved only F2=0.765. Although it kept improving, at this stage I did not push further for more epochs, as it had already started to overfit.
What would be the best way to tackle this kind of imbalance problem in multi-label classification? and how to get better results in this particular dataset?
Hi everyone,
This competition uses F-2 score which based on precision and recall as the metric. I am wondering how precision and recall are calculated in this multi-label problem.
Does it calculate precision/recall for each label and take the average? If so, the result may be biased since the labels are unbalance.
Really appreciate if someone can help me out here!!!
If the network contains a fully connected layer. Now suppose that the previously input images are all the same size, and the dimensions obtained after convolution are all the same, for example, a×b, followed by a 1×c fully connected layer, then you are now convolving. The size of the weight matrix between the output and the fully connected layer is (a × b) × c. But now if you enter an image larger than the original input, you have to have the convolution output be a’ × b ‘If it is connected to the full connected layer, the size of the weight matrix is (a’ × b’) × c, obviously not the same as the original weight matrix, so it can not be used and trained.
Why does set_data not change the network architecture, how does it train?
Does anybody have scripts to convert the predictions into kaggle submittable csv? I did some sorting and copying but it takes too long to convert the whole 40k test predictions.
Hi folks,
I submitted in Planet classification challenge after going through part-1 notebooks.
I have couple of queries here.
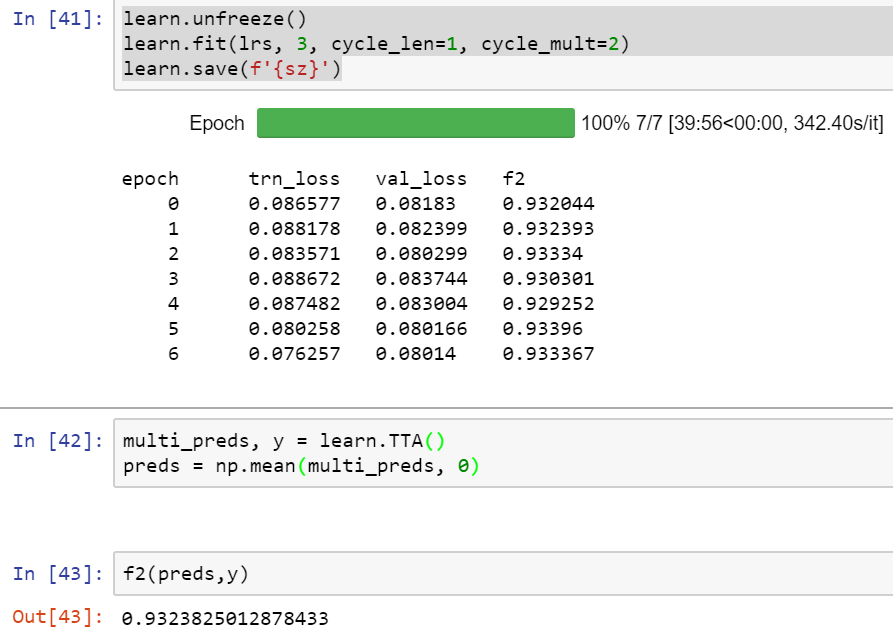
My public score evaluated to 0.90770 despite achieving 0.9333 f2 score on validation set(10% of train-jpg).
I observed average training speed 342sec/it in last phase of training(sz=256 and unfreezing all layers),this speeds seems to slow for paperspace instance.
I have a quick question about learn.tta(is_test=True): In the code for this challenge it ends up returning a 3d array of size (5, 61191, 17). I understand the 61191 and 17, but I’m not sure what to make of the first dimension. Why do we get 5 of them? I would have expected only 2 dimensions and, in fact, all of the code samples in this thread take the first member of that array and ignore the rest of them.
Because TTA by default returns predictions on 4 random data augmentated images + 1 original image. We need to do an average over it to get the prediction for the original image like:
multi_preds, y = learn.TTA()
preds = np.mean(multi_preds, axis=0)
Not only for learn.TTA(is_test=True), it should also return the similar dimensions if it were called on the validation set like learn.TTA() . It too needs to be averaged in the next line to get the actual probabilities.
Note: In the planet competition, the model has softmax as its last activation layer. Hence it directly returns the actual probabilities.