Thanks for a such great work, @slavivanov
On last weekend I’ve finally managed to get spot instance running with persistent storage.
It was a long way, with obstacles as nvidia-smi command showing errors. So, maybe my experience could help somebody.
Note: If you are looking for exact solution, just jump to the part “How I managed to get rid of nvidia-smi problem” and skip failure experience.
For all steps described below I was using guides from the article: https://medium.com/slavv/learning-machine-learning-on-the-cheap-persistent-aws-spot-instances-668e7294b6d8
First of all I’ve tried to create an instance from the Step 1: https://medium.com/slavv/learning-machine-learning-on-the-cheap-persistent-aws-spot-instances-668e7294b6d8
As you can assume, I already had some instances, keys and VPC generated by fast-ai scripts
So, I need to clean the environment for seamless experience. Yes, lost some data, but it wasn’t something, what I’m able to recover easily.
If you want to follow the same step, there is a really helpful guide in the wiki: http://wiki.fast.ai/index.php/Starting_Over_with_AWS
Note: Don’t forget to clean not only AWS environment, but also to delete local “aws-key-fast-ai.pem id_rsa” key. Otherwise create_vpc.sh script will fail with an keypair problem error.
After cleaning environment and creating VPC, start_spot_no_swap.sh script works as a charm. Instance is created just by calling one command.
Note: Play with bid_price value here. By default, it is 50 cents, you can make lower or higher, based on demand in your area.
Flushed with success, I got Step 2 - having persistent data storage. I’ve skipped approach with mounting disk and got directly to automated root volume mount and hit the bumpy road.
I’ve tried to follow instructions from section 3.1 - cloning config from the instance. Script worked fine, old instance was terminated and new one was created.
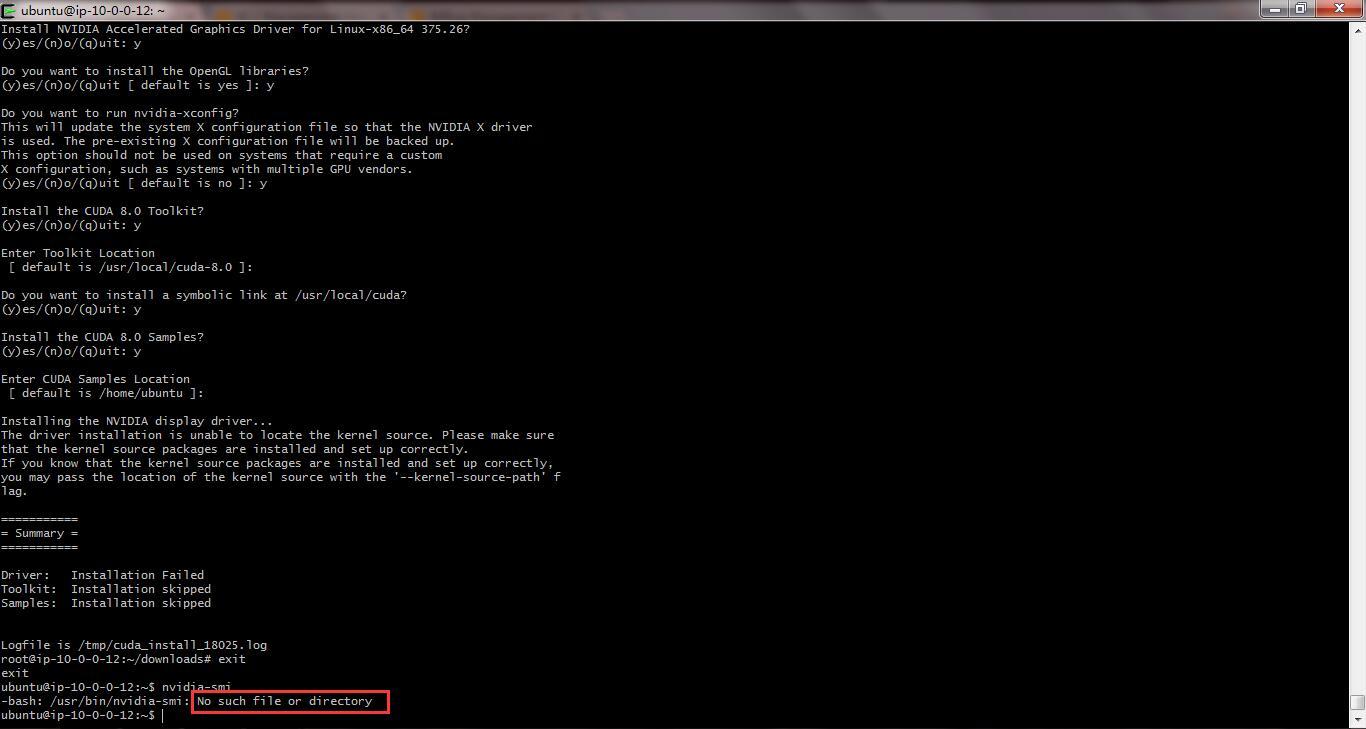
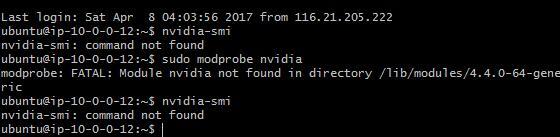
I was able to login, but unfortunately when I tried call nvidia-smi, it showed me the same error as @slazien and @justinho had.
I tried to call ‘sudo dpkg --configure -a’, but result was the same.
I’ve tried different approaches and here are my series of unfortunate events:
- I assumed that I called config_from_instance.sh too earlier and package installation was still running on old instance. So I’ve created new one, ran top command and waited until all process are finished. Cloning from such instance resulted with the same error.
- I assumed that maybe something is wrong with drive mount, so I’ve tried to follow steps from section 3.2 with detaching and renaming the drive. Cloning from such instance resulted with the same error.
- I assumed that something is wrong with configuration generated from running instance, so I’ve tried to change AMI to ami-a58d0dc5, as it was said in the article.
- Running such instance resulted with the same error.
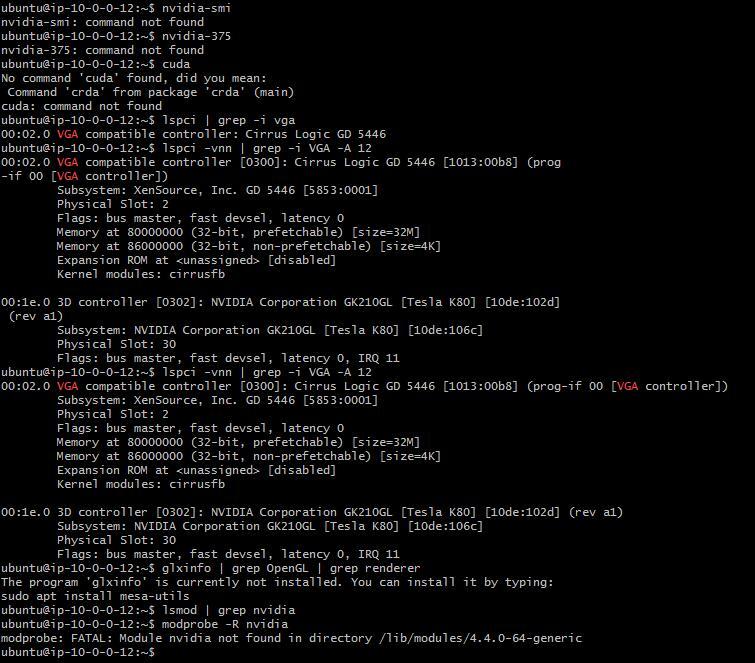
- I’m not going even to mention different tries to install/reinstall nvidia stuff. It never helped
Sorry for such a long list of failures, but I had to share this pain with somebody.
¯\_(ツ)_/¯
How I managed to get rid of nvidia-smi problem
So, after all these failures I was really ready to give up, but decided to try one more time with AMI provided by fast-ai
Here are my steps, which led to finally working instance:
- Clean your environment
- Run script to create VPC
- Run script to create Spot instance.
- Let all installation scripts finish. By my measurements it can take from 10 to 15 mins (until last dpkg appearance in top command)
- Do your stuff on the instance: clone git, download cats and dogs and so on.
- Stop instance and rename the drive, as described here: https://medium.com/slavv/learning-machine-learning-on-the-cheap-persistent-aws-spot-instances-668e7294b6d8#9f6d
- Clone configuration file to my.conf, as described here: https://medium.com/slavv/learning-machine-learning-on-the-cheap-persistent-aws-spot-instances-668e7294b6d8#9f6d
- Change values to appropriate ones. Pay attention that in article doesn’t say anything about changing key name ec2spotter_key_name, but it is required. It should be: ec2spotter_key_name=aws-key-fast-ai
- And now a trick which worked for me: put for ec2spotter_preboot_image_id, AMI provided by fast-ai, for example I’m using ec2spotter_preboot_image_id=ami-bc508adc
- As this AMI is large one, you’ll need to change default volume size in the ec2spotter-launch script. By default, it is 8 GB, we need to put 128
Change it here:
"BlockDeviceMappings": [
{
"DeviceName": "/dev/sda1",
"Ebs": {
"DeleteOnTermination": true,
"VolumeType": "gp2",
"VolumeSize": 128
}
}
After all these changes, I’m able to start instance using start_spot.sh script and have GPU accessible by theano, having all changes saved … at least it worked out few times 
Hope, all this information will help somebody to save few bucks.


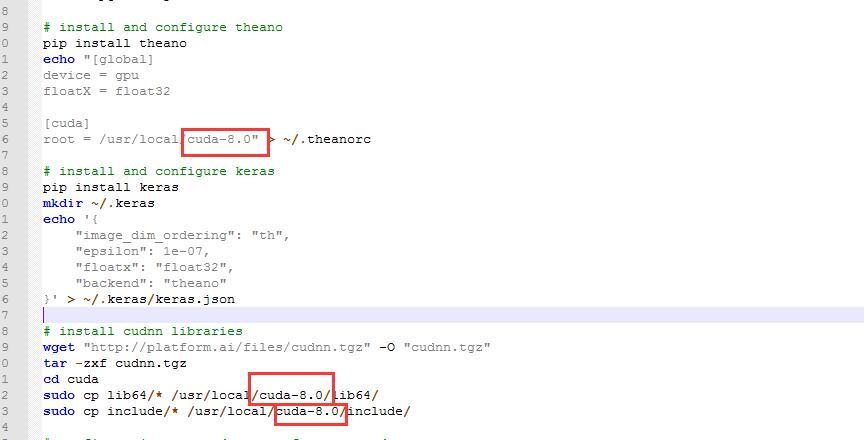
 I think I’ve done enough banging my head against the wall it’s time to reach out.
I think I’ve done enough banging my head against the wall it’s time to reach out.