That is all exactly right. But this earlier statement isn’t: each of those parts would be compared against 4+c filters to see which one activated it the most.
Ok, I think I’m starting to understand this. Just have to rewind a lot. Glad I have study group tomorrow to bounce some ideas off hiromi and metachi!
Note that the loss function is nearly identical to the single bounding box loss function we used at the end of pascal.ipynb. The only significant difference is that we first have to solve the matching problem.
(There’s also a much more minor difference that we use binary cross entropy and ignore background, instead of categorical cross entropy, but it’s fine to totally ignore that difference for now)
A while ago, I ran into this post which helped clarify the idea of BN rather well for me. Now and then, I go back to it to refresh myself when I’m confused. Hopefully helpful to more. https://towardsdatascience.com/understanding-batch-normalization-with-examples-in-numpy-and-tensorflow-with-interactive-code-7f59bb126642
3 Likes
Ow, that’s very nice, I will search more information about this. I actually face this scenario very often, In deep reinforcement learning is common to have one network body with multiple heads.
1 Like
Thanks 
Check if git pull had some conflicts , resolve them and commit and reopen.
I faced this problem when I had some commit conflicts on pascal.ipynb file. After resolving those, the notebook opened fine.
@rachel and @binga is the gist linked to at the top of the page private/correct? It’s going 404 for me. Is there a group or something I need to join or be admitted to?
yes found git full conflicts and all okay now. Thanks!
I fixed a bug yesterday and created a new gist. Updated the link now. Thanks!
1 Like
I did. But when you rerecorded that part was lost.
Oh I understand now - sorry! I highlighted @sermakarevich’s Kaggle gold medal in the Jigsaw Toxic Comments competition.
2 Likes
Oops, I missed that part too. Any chance the link with live stream is still valid ?
This was just amazing:
4 Likes
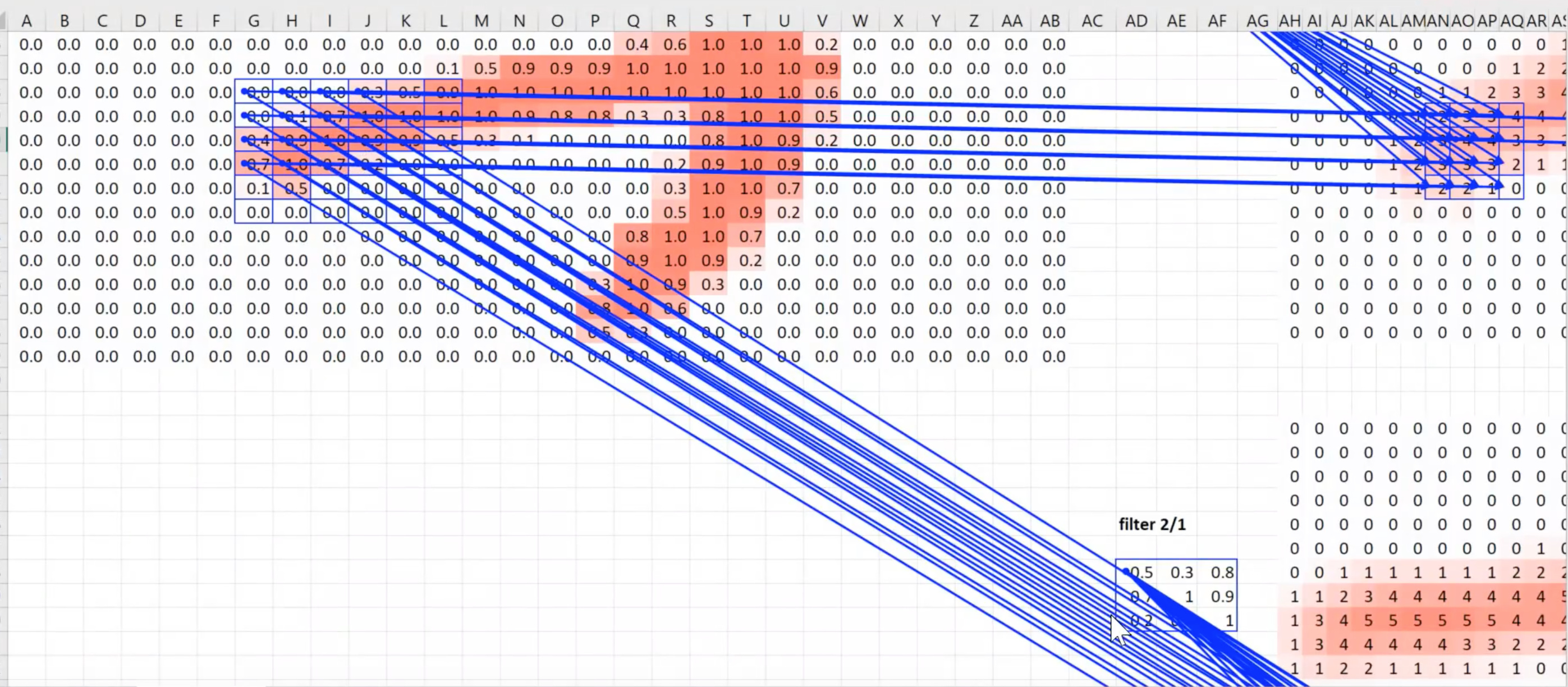
While presenting this slide @jeremy mentions two Conv2d operations performed in succession:
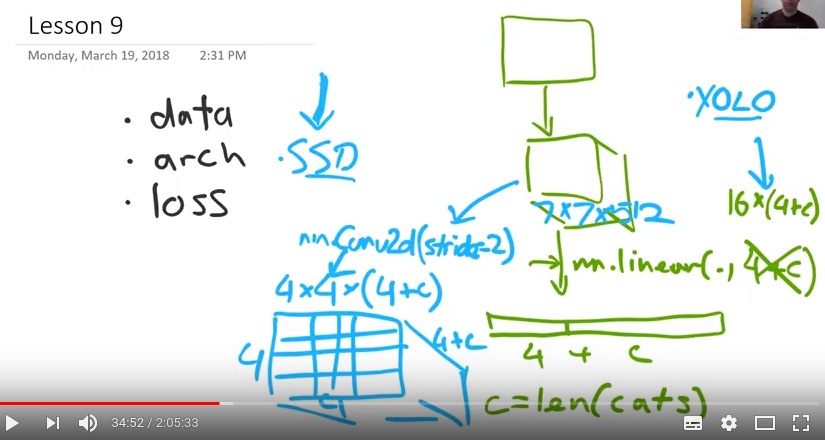
The first one is a Conv2d that takes the outputs from the resnet model of shape (7, 7, <num channels>) to a new shape of (4, 4, 4+<num_classes>).
In the lecture we are not provided the other settings for the convolution but I guess they would be easy to figure out by looking at the notebook. My guess is that they are performed with a (3, 3) kernel and a padding of 1. These are quite common settings that preserve feature map size with a stride of 1 and I assume they might be what we go here for with a stride of 2, which gives us the ‘(4 ,4)’ feature maps.

Here however, we perform another set of convolutions going from (4, 4) to (2, 2). Given how these two convolutions seem to be doing roughly the same thing, I would expect their parameters to be the same. But I don’t see how we can go from (4, 4) to (2, 2) with a filter size of (3, 3) and a stride of 2. We could do one side padding but that sounds absolutely horrible 
The only settings that seem reasonable here for the 2nd convolution would be padding of 0 and a (2, 2) kernel.
But is this really what is happening here? More interestingly, if these convolutions don’t share parameters, why is that?
I was really blown away by the observation that a receptive field will ‘look more’ at what is in the center. (this is nicely shown using excel where there are more values feeding into the center of a receptive field than its sides). Could this be a factor that plays into the conv params here? If we want to look as best as we can at a square we should probably look at the center given the nature of a receptive field and the padding of 1 is counter productive. Going from (4, 4) to (2, 2) seems to be doing just that.
But why the earlier convolution?
Or maybe this whole reasoning is wrong and there is something else happening here?
3 Likes
Not sure I understand—why wouldn’t you get from (4,4) to (2,2) with a (3,3) conv, a stride of 2, and padding 1? Those settings should exactly halve the size of the input
I think you would need a stride of 3 for a 3x3 kernel with a padding of 1. But then you end up looking at a lot of zeros.
The formula for the output size is (W−F+2P)/S+1, where W is the input size, F is the size of the conv kernel, and P is padding. For this case I guess it would come down to how you do the rounding. You’d get (4-3+2)/2 + 1, or 3/2 + 1, and I think you do integer division (round down), so you’d get 1 + 1 or 2 as the output size.
Source for formula: http://cs231n.github.io/convolutional-networks/
I think I see what you’re saying though—in that case you wouldn’t be using the right or bottom padding, so in that sense it would be a “one side padding” like you mentioned.