number channels are obtained by taking number of equivalent filters, which is our choice.
my understanding is that the disproportionate scales of bounding box error and classification error are one time fixes for a given model. For a given model tweaking them once to match their scales, as part of model building would be enough.
How about normalizing losses, with a desired limits.
Tagging @jeremy on this. The youtube link at the top now starts from mid-chapter(from where you started recording locally)
Maybe the youtube stream video (before the recording) can be glued to that one. was planning to go through the lecture again this evening. would be super if it can somehow be restored.
I don’t think it is a joke  Would love to learn more of a story behind the person who authored this paper Thus far my encounters with YOLO has been quite strange so there must be some nice backstory. Love the graphs BTW.
Would love to learn more of a story behind the person who authored this paper Thus far my encounters with YOLO has been quite strange so there must be some nice backstory. Love the graphs BTW.
I haven’t had a chance to read it fully but so far I think it is great
Love the finishing words of it as well.
For another easter egg that only takes a little bit of the light spirit from the yolo v3 paper, check out the first bibliographical reference in this very serious Inception paper
1 Like
Thanks, time to read some papers.
Try this one out as well, AI Journal , Covers DL,NLP,RL,CV,Adversarial examples,GANs + Research (aspect) in depth.
1 Like
Yes it would be great. The initial missing part - don’t know how much - makes difficult to connect the lessons. If it is not possible could someone describe what happened from the real beginning to this point ? Thanks.
Really? I thought it was a real paper. Jeremy mentioned it in the class, no?
But to normalize we also need to know the scale of the loss, I think it would be similar to multiplying to some constant to make it similar.
My bad. I just saw it on reddit and posted the link here.
The YOLOv3 paper is written in a humorous style, but I’m pretty sure that the architecture updates and reported results are real
2 Likes
Don’t let the light-hearted style of the paper fool you, the YOLOv3 update is real The updated version is available for download on the official website including some other info on it. Feel free to check it out here: https://pjreddie.com/darknet/yolo/
4 Likes
For me the coolest thing is that this paper cites itself (see #14)…recursion!
![]() under Formulas. Use it together with
under Formulas. Use it together with Trace Dependents as Excel debugger.
2 Likes
Definitely not a joke. Please stop confusing more people in the forums. It’s rather easy to look these things up if you’re unsure. Lighthearted language doesn’t necessarily mean that “It’s a joke paper”.
(Also, that’s one Damn Good Resume.)
EDIT: Re-reading this, I can see that I came off a bit rude. We’re all learning here, I apologize for the unnecessary tone. 
3 Likes
Can someone point me to the video for this lesson? Would like to watch again.
Here is my understanding, please correct me if I am wrong.
To add one = add a new category (bg: background) in addition to the existing categories. However, we don’t want the model to predict background.
To subtract one, only bounding boxes with existing categories remind.

Some of my highlights from YOLOv3 (There are so many, just read it):
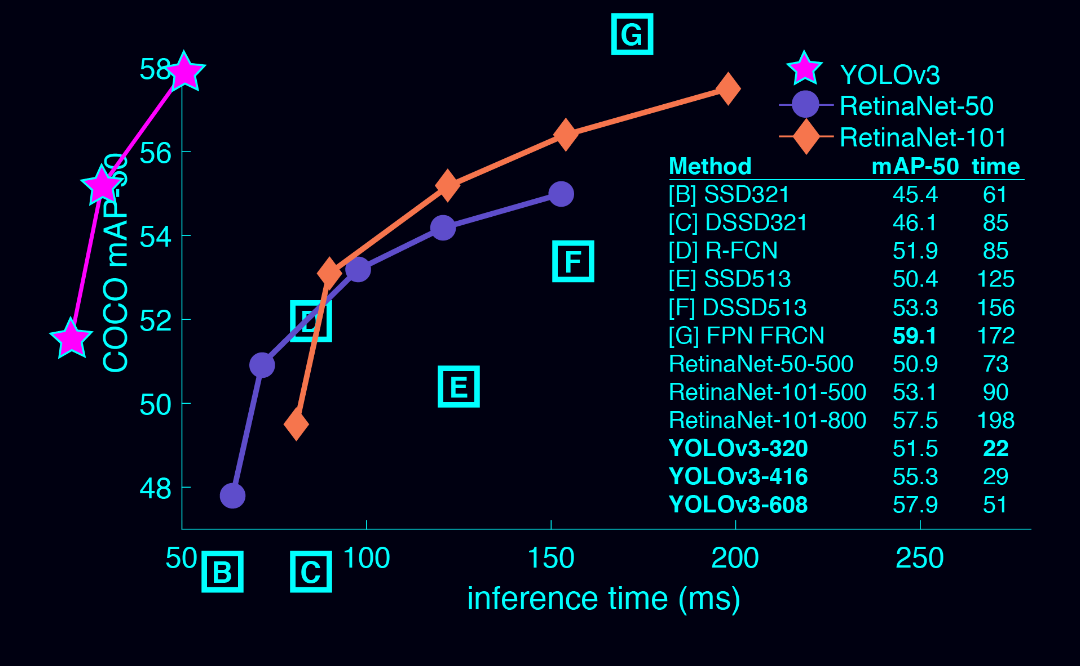
Figure 3. Again adapted from the [7], this time displaying speed/accuracy tradeoff on the mAP at .5 IOU metric. You can tell YOLOv3 is
good because it’s very high and far to the left. Can you cite your own paper? Guess who’s going to try, this guy → [14].
But maybe a better question is: “What are we going to
do with these detectors now that we have them?” A lot of
the people doing this research are at Google and Facebook.
I guess at least we know the technology is in good hands
and definitely won’t be used to harvest your personal information
and sell it to… wait, you’re saying that’s exactly
what it will be used for?? Oh.
Well the other people heavily funding vision research are
the military and they’ve never done anything horrible like
killing lots of people with new technology oh wait…
I have a lot of hope that most of the people using computer
vision are just doing happy, good stuff with it, like
counting the number of zebras in a national park [11], or
tracking their cat as it wanders around their house [17]. But
computer vision is already being put to questionable use and
as researchers we have a responsibility to at least consider
the harm our work might be doing and think of ways to mitigate
it. We owe the world that much.
3 Likes