That’s right.
Take a look at the probabilities and tell us what you find! 
How do you get this kind of summary ?
When using learn.summary() on the resnet34 model, my last layers (before the flatten layer) are the following (also the the display is very different from yours):
Blockquote(2): BasicBlock(
(conv1): Conv2d (512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
(relu): ReLU(inplace)
(conv2): Conv2d (512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True)
So the last kernel size seems to be 3*3 and not 7*7 so I am a bit confused.
That doesn’t look like the output of learn.summary. Can you please double-check what code you ran?
After reading your answer I re-run learn.summary and got a different result (a better one):
Blockquote (‘BatchNorm2d-120’,
OrderedDict([(‘input_shape’, [-1, 512, 7, 7]),
(‘output_shape’, [-1, 512, 7, 7]),
(‘trainable’, False),
(‘nb_params’, 1024)])),
(‘ReLU-121’,
OrderedDict([(‘input_shape’, [-1, 512, 7, 7]),
(‘output_shape’, [-1, 512, 7, 7]),
(‘nb_params’, 0)])),
(‘BasicBlock-122’,
OrderedDict([(‘input_shape’, [-1, 512, 7, 7]),
(‘output_shape’, [-1, 512, 7, 7]),
(‘nb_params’, 0)])),
So I rerun all my code again and it turns out that learn.summary give me a again the “bad” output (the one I posted before).
To get the “good output” of learn.summary I have to train the learner, save it and reload it and then use learn.summary.
I don’t understand how that’s possible. If I train and don’t save/load I don’t get the “good” output. If I save/load without training I don’t get the “good” output either.
Hello, I would need help in setting up interpreter on Visual studio code:
My Visual Studio code was installed even before I had setup environment for Part1v2 back in October so it was not installed with Conda. Today I downloaded fastai using:
git clone https://github.com/fastai/fastai.git
Next, I pointed Code to the folder which looks like below:
Then, I looked for fastai interpreter but the code didn’t list it
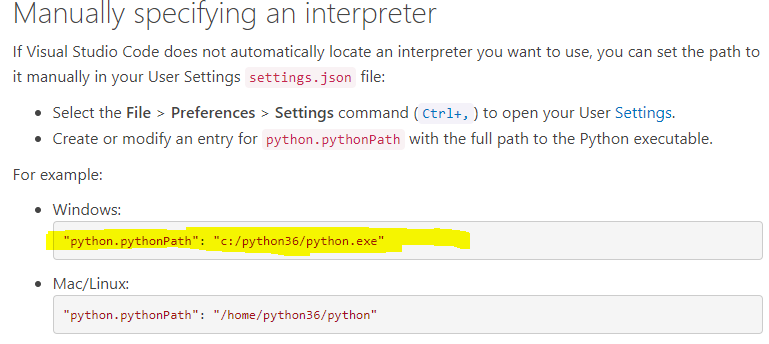
Lastly, I looked into this blog to add an interpreter manually but got struck at below highlighted line. Question - What line should I replace highlighted the line with for fastai?
Thank you!
Make sure you use learner.summary() — pay attention to the two parenthesis at the end ie. you are calling a function. Instead, if you just do learner or learner.summary you will get a slightly different representation of the model
1 Like
Hey Vikrant,
I usually do something like this … may work for you:
cd fastai
conda env create -f environment.yml #create an env called fastai
conda activate fastai #this works for latest conda, otherwise do `source activate fastai`
Now, you should be able to search for it using the python:select interpreter from the vscode command palette (scroll till you find the fastai one). If you just select it in UI, the settings.json will be automatically updated.
Give it a shot and best luck
A
3 Likes
Thank you, Asif.
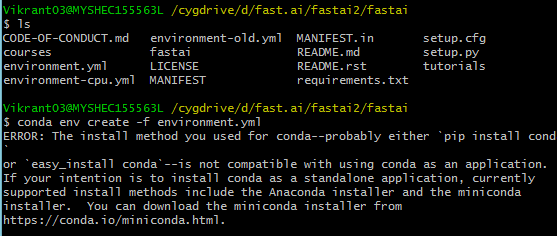
I believe all of these commands are to be run on Cygwin (I’m on windows 8.1)? If so, this is what I get.
Hello again!
I have a suspicion that either the conda environment is old or somehow corrupted.
Thats the beauty of something like conda — you can blow it away and start anew quite easily. So, If you are feeling bold, head over to https://conda.io/miniconda.html and install a fresh version. And try again.
Best,
A
PS as always back up important stuff
PPS There is a cpu (ie no gpu if it applies to you) specific environment-cpu.yml that may be more appropriate once conda thing is sorted out
1 Like
Since fastai isn’t default environment so I’ve to always activate fastai before I can use VS Code?
No don’t install in cygwin or use cygwin for this (or pretty much anything related to the course nowadays). Use powershell or a cmd shell.
No, once you’ve selected the interpreter, it remembers it.
1 Like
When we are looking at the predictions for the Largest Item Classifier, I wonder why are we applying another softmax() to the model output?
x,y = next(iter(md.val_dl))
probs = F.softmax(predict_batch(learn.model, x), -1)
x, preds = to_np(x), to_np(probs)
preds=np.argmax(preds,-1)
I believe I got the same result when I did this:
x,y = next(iter(md.val_dl))
probs = np.exp(to_np(predict_batch(learn.model, x)))
x = to_np(x)
preds=np.argmax(probs,-1)
1 Like
The documentation of patches.Rectangle says it accepts coordinates of lower-left corner. But we can see that the text showed at these co-ordinates goes to top-left.

To check I displayed the image with axis and found that y-axis is in reverse order.

Because of reverse y-axis, we are seeing the bottom-left point at top-left.
So the Pascal VOC bbox should be
[<bottom_left_x>, <bottom_left_y>, width, height]
[155, 96, 196, 174] <- car bbox
And the bbox we are inferring from above should be (y,x) of bottom-left and top-right corners
[<bottom_left_y>, <bottom_left_x>, <top_right_y>, <top_right_x>]
[ 96, 155, 269, 350]
Please correct me if I am missing anything.
1 Like
Isn`t final resnext50 layer is
Linear(in_features=2048, out_features=1000, bias=True) ?
1 Like
@jamesrequa @wdhorton @Interogativ @NitinP @jsonm Thank you all for the debate on bounding boxes! Relying on the classifier’s accuracy is still something that I tested a bit, but will try again like this:
- don’t show “no objects” instances in the training set -> All examples have an object that I want to localize and classify (this should solve the “skewed” uncertain predictions problem)
- check whether if it can handle well images with no object inside of it during inference. Will try as soon as I can and will update in here!
Hi Vijay, I am also a mac user and had the same issue. I tried pycharm, though, and the symbols appear to index properly there (worked like a charm! heh)- you could consider using it if someone else doesn’t have a solution for mac visual studio code.
1 Like
Thanks !
It’s true that learn.summary give a very different output from learn.summary().
The first one return something which start like this:
<bound method ConvLearner.summary of Sequential(
(0): Conv2d (3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(2): ReLU(inplace)
so it’s not a dict, and I don’t know which model it represents as the layer are totally different from the learn.summary() which return an ordered dict.
Thanks again !
Both the output are correct IMO. They are giving you slightly different information. I prefer to look at both
1. learner.summary() # architecture (e.g conv2d or relu etc)
2. learner — # input size, output size, number of parameters
Going back to your original question (iiuc),
I believe you are confusing kernel size with number of channels. The resulting 512x7x7 comes about for a particular combination of input size (256x14x14), kernel size(3x3), padding(1x1), stride(2x2) and a conv2d (512 channels/filters). It happens around BasicBlock-108 and kinda carries over till near the end.
This short-video from Andrew Ng’s course may be helpful (be sure to checkout few of the prior ones in the playlist)
Good luck studying 
1 Like