It shouldn’t assuming that you stick to the same precision (if bound by pixels, stay to that). It is just a different way to defining the same thing.
1 Like
Given the move towards differentiable programming, why not use complex-valued weights instead of real-valued weights?
Complex functions, if differentiable, are infinitely differentiable—and complex numbers represent rotation and scaling more succinctly than real numbers and so should require fewer parameters in a model?
5 Likes
Does anyone know the name of the extension for atom that does the search function Jeremy just did in VSC?
So far I’ve been using ‘find in folder’ but this functionality looks pretty neat.
2 Likes
Now it’s just predicting the same class that the largest bounding box has for a particular image, with resnet34.
Later in the notebook, they just run a regression with 4 outputs for x1, y1, x2 and y2, again with the same resnet34.
Even later, they combine classification and regression in a single model with 4 + number_of_categories outputs and create a custom loss that breaks the outputs into classification and regression parts and applies L1 and cross-entropy losses to these parts.
10 Likes
If small squishing doesn’t hurt classification too much, why not include a small random squish in default data augmentation? Has this been tried?
5 Likes
hi @jeremy, do you have any experience with AMD ryzen cpu’s for deeplearning box (as oppose to Intel i5/i7)?
Speaking of pdb, if anyone in the middle of debugging (pdb.set_trace()) and accidentally hit Shift+Enter (command for running a notebook cell) without quitting the debugging session properly (i.e. quit during debugging session), one will get stuck in that cell “forever”. I usually have to restart the notebook at this point. Does anyone know any way to exit the debugger at this situation without restart and re-run everything?
2 Likes
It’s what they use in the object detection papers, IIRC.
1 Like
Thanks for that! It would be great to edit the top post (it’s a wiki post) to include this information there directly, if you (or anyone else) have a moment.
Yes it can do - it depends on what the neural net finds easier to model. I haven’t experimented with both - could be an interesting thing for participants in this course to study and write up!
4 Likes
Just finished watching the lesson, some questions or points:
- I don’t know if it’s just me, but calling open_image using IMG_PATH/something with Pathlib on windows 7 is giving me some problems (TypeError: bad argument type for built-in operation), but when I do str(IMG_PATH)+’/’+something it works well. Surprisingly, it’s fine if I don’t call open_image, for example using PATH/“something” for the jsons at the beginning. Might be something else entirely.
- Just a SMALL INSIGNIFICANT thing but I’m kinda autistic
 it’s “vice versa” and not “visa versa”, but who cares
it’s “vice versa” and not “visa versa”, but who cares - Can’t use md either on Windows, but I think I remember somebody already found a fix, and I’ll go look for it now!
- What about images in which NO object is there / NO object should be detected?
- Another very quick question about a problem a bit more complex than simple classification: I want to classify an object, for which I have multiple views (not always the same number of views). How should a problem like this be tackled, in principle? Single frame classification (one label per frame) and some kind of “traditional” ensemble approach, multiframe classification (one label for object), some mix (CNN+RNN? How else?) ?
 it’s “vice versa” and not “visa versa”, but who cares
it’s “vice versa” and not “visa versa”, but who cares@jeremy tagging you, and thank you for today’s lecture! Glad to hear @rachel’s voice, too!
1 Like
Yes in fastai.transforms you’ll see there is a RandomRotateZoom class that sometimes will call stretch_cv. I wrote it ages ago and haven’t updated it to handle y-transforms, but you could easily fix it up, or just add a RandomStretch transform following the RandomRotate class for sample code. I’d be happy to take a PR that does this FYI.
4 Likes
I still couldn’t understand what were we training?
Since we already had the images, their classes, bbox coordinates as well, so Jeremy plotted them using Matplotlib in a cool way,
So what was the training done for?(sorry if it’s noobish but I still can’t get the intuition behind doing so)
Thanks
Edit
Probably It’s answered here
2 Likes
The pascal-multi notebook seems to be inspired by YOLO, segmenting the pictures in a similar way. But the notebook from yesterday did just try to look at only the largest objects, no YOLO-like segmentation.
1 Like
In this case, we already had the bbox coordinates with us,
What would be the way to generate them on a personalized dataset?
I think (not sure ) it can be done using the V1 cmap technique, and get the dimensions from the cmap region or its done using Image Segmentation?
In short, the following 4 parameters (x1, y1, x2, y2) is what we are training for and trying to predict for the validation set !
Somebody who knows better, please correct me here if I’m wrong.
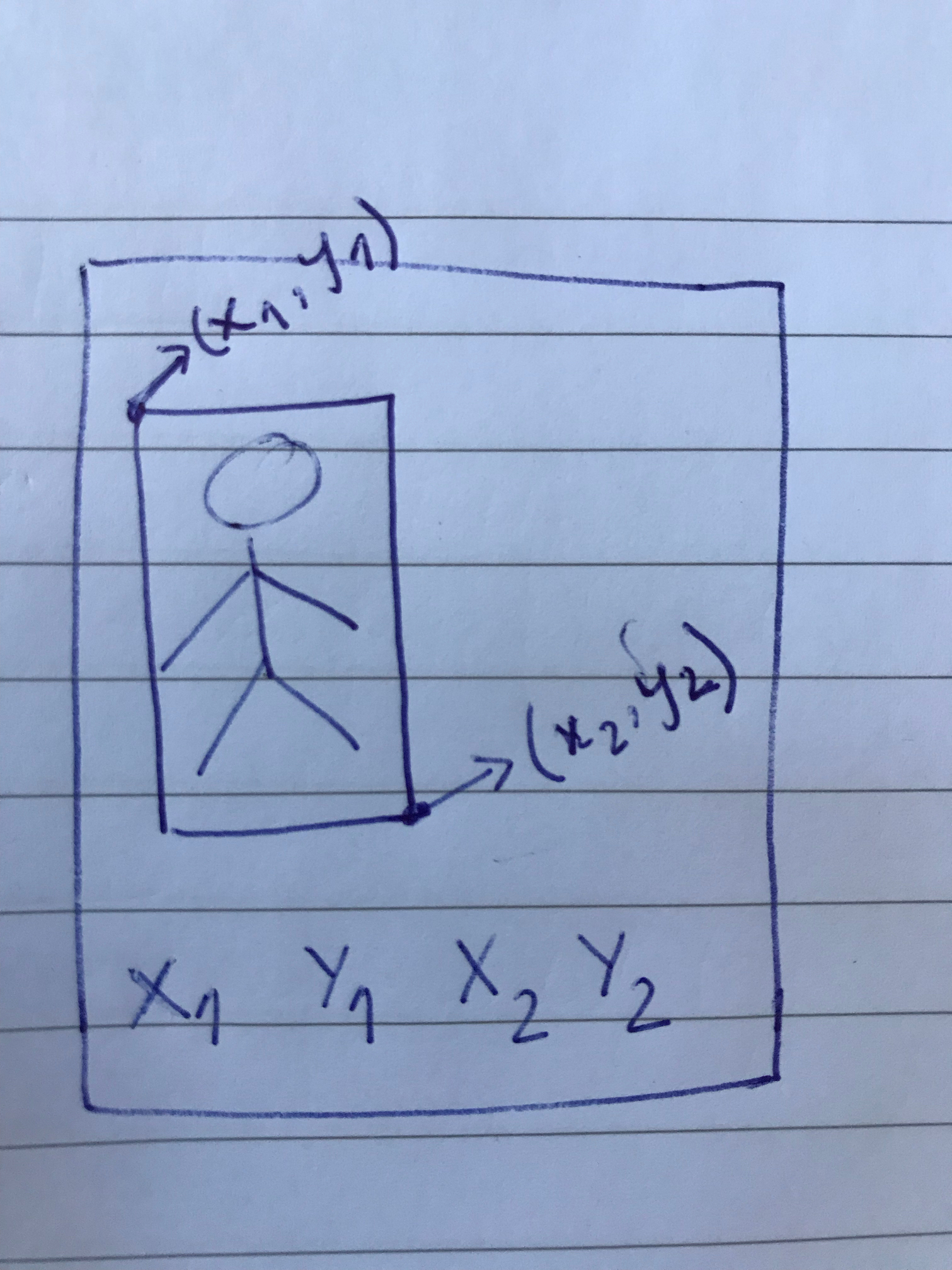
13 Likes
Yes, but we only use them for the training set. And, we compare/validate them for the validation set. Hope that clarifies.
1 Like
Completely forgot about validation and test sets…
My bad…
It all makes sense now…
Thanks for replying
Hi @ecdrib. I have the same problem. Will you share your understanding?
I am also very interested to try pytorch/fastai on windows.
Haven’t try it yet, but this is seems what you are looking for :
Howto: installation on Windows
2 Likes
Then what’s the loss function or the metric involved then?
Is it Area of the two boxes then?