@jeremy Thank you for the pointer to the NIN paper.
As a quick summary: the paper proposed a new structure called MLPConvBlock to replace “vanilla conv block”, and MLPConvBlock can be efficiently implemented using 1x1conv in the following fashion:
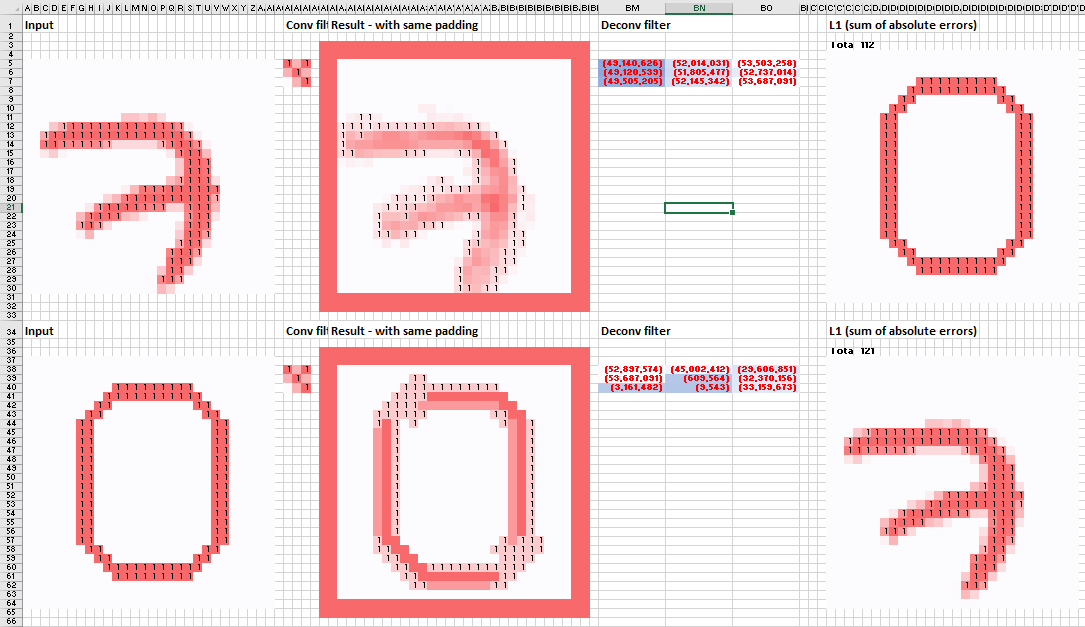
In Cycle GAN, the maximum single value in “Deconv filter” (in blue) could be over -53 million although the the values of “Conv Filter” were ranged from -1 to 1.
This is awesome! I’m curious as to how you implement this, though. For the GAN, how did you do the min-max optimization? Especially, having a hard time wrapping my head around how you implemented the discriminator. Did you just choose an arbitrary convolutional filter for the discriminator?
Hello
I can not see the video, I was away this week and trying to view lesson 13 but the video is not available.
would you please help?
Regards
Ibrahim
Setup a deconvolutional filter as usual. Then, using “solver” to minimize the sum of the loss function (L1 or L2) by “changing variable cells” (ie the deconvolutional filter).
I have question about loss function. Jeremy told that numbers were too small and it didn’t learn. But when I see block 84 in Jupyter notebook with *1e6 in the end, I recall school lessons about precision, where teacher told to use big numbers in the beginning of equation. Does this rule apply here, should it work better with better precision, if we rewrite 1e6*torch.mm(x, x.t())/input.numel() ?
That may be better - although in this case the problem didn’t occur until later in the optimization when it calculated the gradient and step size, so it doesn’t really matter.
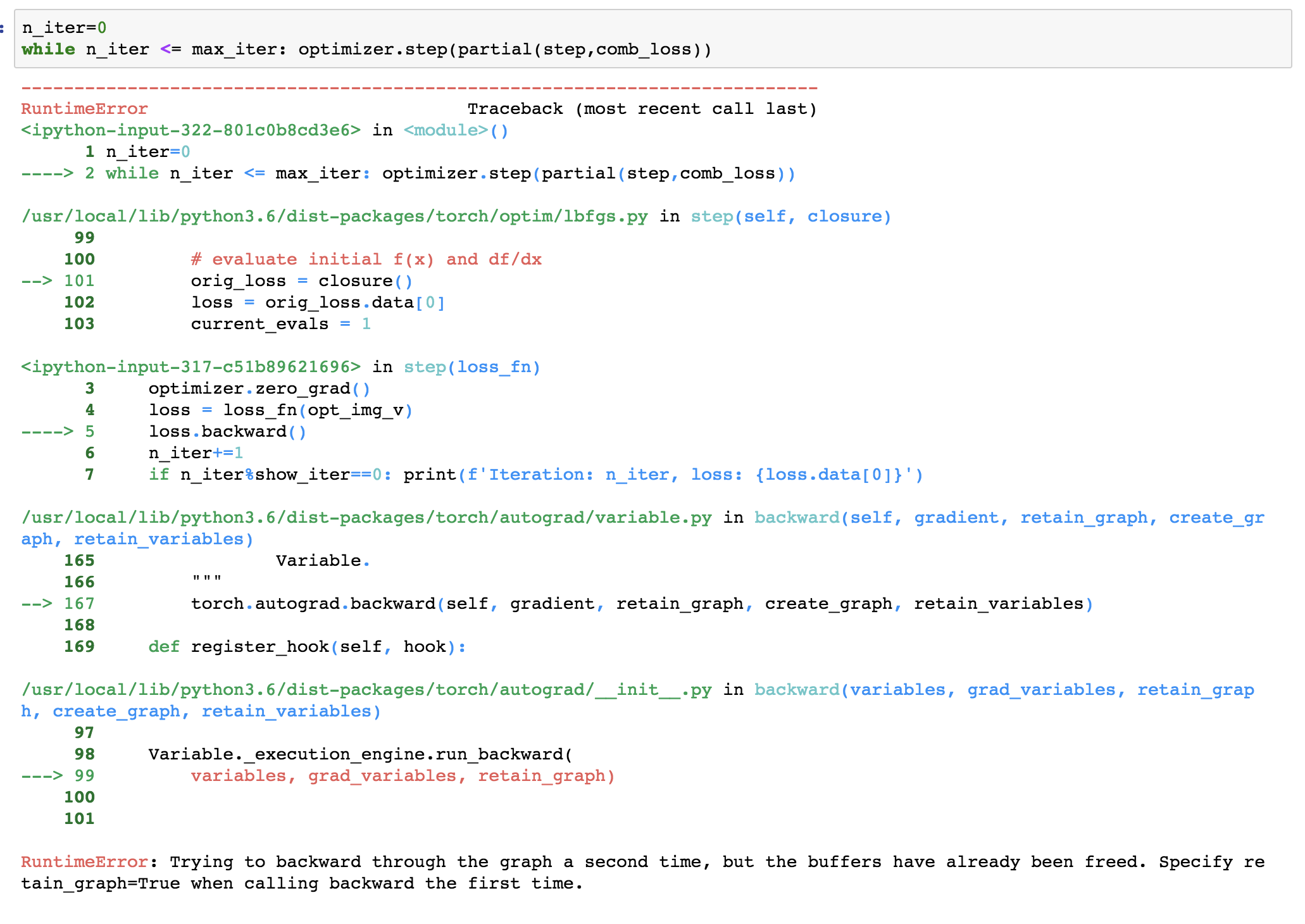
Does anyone run into this issue when trying to rerun the notebook shown in class? I am stuck at the last part of the style transfer when trying to run the iterations on the comb_loss function. Thanks in advance!
I have a question regarding the architecture that you guys are using to generate these new pictures. Did anyone try using the ResNet like Jeremy told in the class?
I am struggling to get any good output there. I am yet to try anyother.
“Style transfer typically requires neural networks with a well-developed hierarchy of features for calculating the loss. Thus for this purpose, the good old vgg-16 and vgg-19 architectures work very well. But inception architectures (unlike resnet architectures) also have the same property.”
and i guess it makes sense. Since ResNet uses skip connections to combine different layers, it does not maintain an interpretable coarse- to-fine feature hierarchy from the last layer to early layers as the VGGNet does. Each layer of ResNet contains both semantical abstraction and spatial details from earlier layers.
It’s a really interesting issue. I’m not sure I agree with this post’s reasoning however. Because resnet has occassional downsampling layers which don’t have skip connections, it does still have a coarse-to-fine feature hierarchy.
I think the issue may be due to the fully connected layers.
Hello,
I created a small blog post about neural style transfer using what I learned from Lesson 13. Please check that out and give me some feedback to improve the content.
Thanks…!!