I’ve tweaked our seq2seq model in the translate notebook and added beam search but haven’t found much success improving the results  Though all the code change required is here, hope it can save you some time trying out beam search
Though all the code change required is here, hope it can save you some time trying out beam search
5 Likes
It’s too bad I can only give you one like on this, after 5 days of looking at this I still don’t have working code. I see you took a similar approach to the direction I’m headed in. I’m going over your code now and will get back to you after I’ve played with it. But thank you so much for your help.
2 Likes
I feel I have missed something, but I couldn’t see any instructions on acquiring the cifar10 dataset in a suitable form for the lesson. The standard pytorch loader for cifar10 loads it into memory, but Jeremy’s approach requires the data in directores. Can anyone tell me how this is accomplished?
Hi Chris,
I was stuck at the same point,
http://files.fast.ai/data/cifar10.tgz
Found this on a forum thread, jeremy seems to have provided a parsed and processed version of the dataset.
Hope this helps 
Alternatively, if anyone is interested
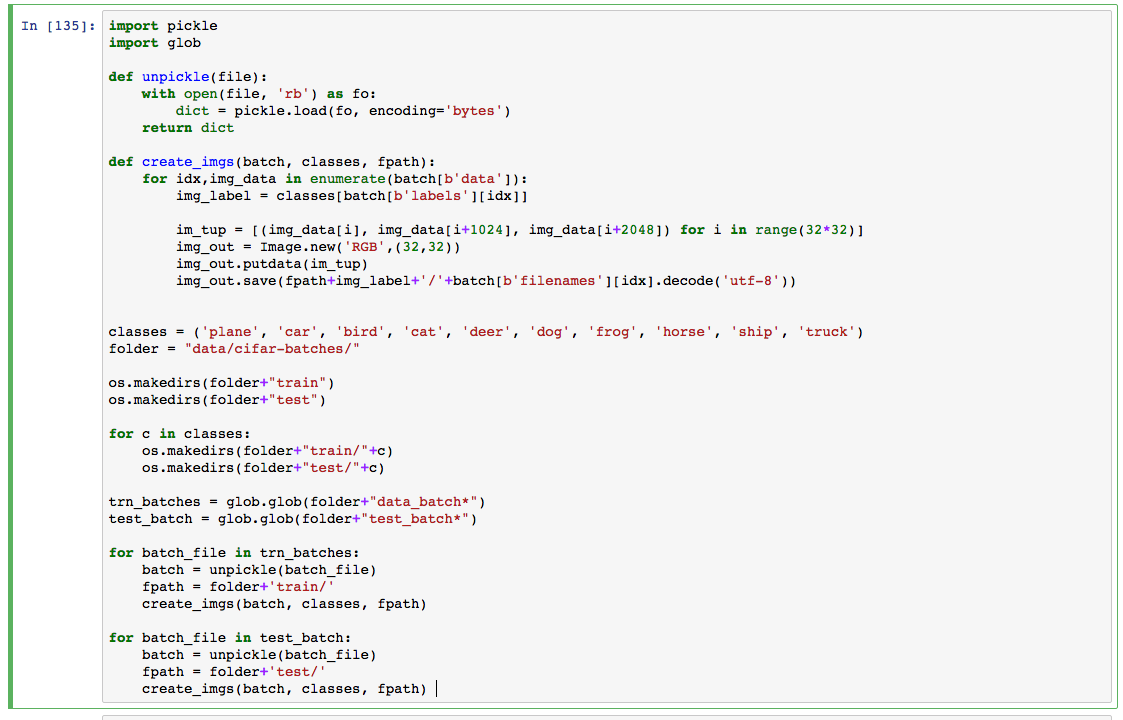
Does the same pre processing 
2 Likes
Thanks very much - I’ll take the files and the technique 
1 Like
Sanity check
I have a feeling that Seq2Seq models and GANs are very much related in ideology
-
Machine Translation is similar to Neural style transfer, as we are learning some latent information about a sentence or an image and using a style/language to transform the latent information into a new form.
-
Super Resolution is similar Language Enhancement, we can enhance the resolution of an image by upsamling/deconv with GANs (SRGAN) or other conv nets, I think its possible to convert a loosely formed sentence into a well formed sentence
ex: ‘He was very amazing in talking to audience’ ==> “He was great at addressing the audience”
If I’m remotely correct about the above two points, I think while doing GANs we can re-use the following
- TeacherForce our generator (may lead to quicker GANs)
- Run any NNet to find class probabilities for every image in the batch and use it as ‘attention’ parameter for the generator to focus learning class-wise (It will reduce noise for the generator and while generating images outside training, it can randomly select from any class and generate a sharper image)
- Discriminator : Generator train ratio (#train iterations) can be inspired from below

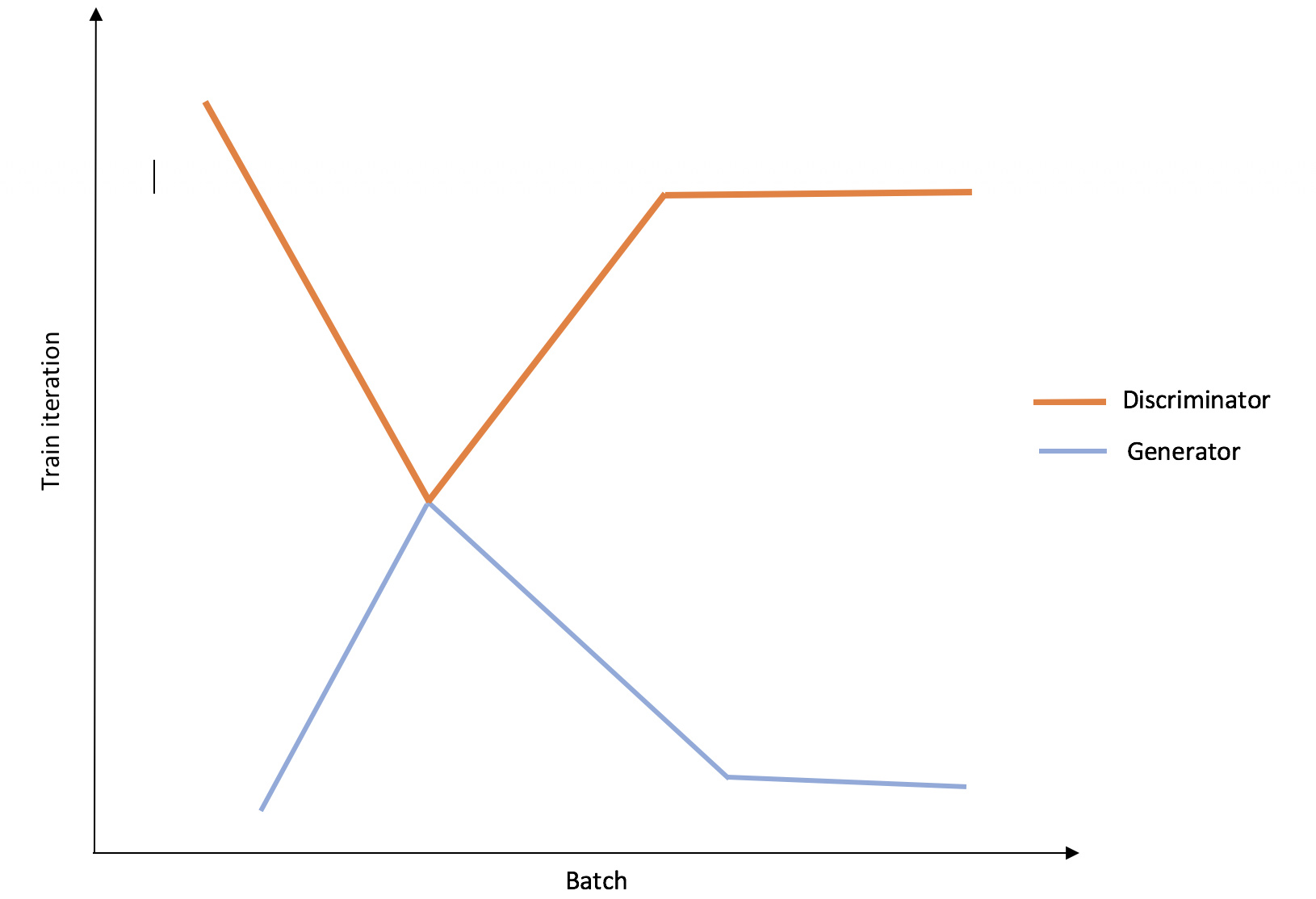
I’m writing it all out because I’m not sure if I’m thinking in the right direction but if I am, I might ask for help in implementing some of the parts; I’m still struggling with converting my thoughts into a functional code.
-
Can you discuss your “super resolution” of sentence idea a little bit more?
From what I understand about upscaling, we’re just applying a few different possible algorithms to groups of pixels, say color interpolation- but how do you do the same for any given sentence (or a subset of a sentence)?
What’s the loss function to decide how “well formed” a sentence is?
-
Can you explain what effect using such a relationship of training iterations for Generator vs. Discriminator over training time would have?
1 Like
We’ll be studying it tomorrow. But take a look at the SRGAN paper he mentioned if interested.
1 Like
I ran DCGAN on 7000 clothing images and got following images.


To improve image quality and control the characteristics of generated images, I added Conditional GAN-like network
(I crawled text data also when crawling the images, and used some of them as labels).
Below image is generated with same noise while sweeping a few parameters. You can see arm positions and cloth pattern changes.
It’s not working as intended quite yet, but it’s super fun 

11 Likes

I have 6 GPUs on my PC
This is what is happening now (1 working and 5 doing nothing)
Is there any way to include them all in the process?

6 Likes
We’ll cover this tonight 
7 Likes
Am I right with the points I mentioned here? I’m testing the iteration relationship myself but for the rest of it I seek your advice.
Sorry for the late reply.
Can you discuss your “super resolution” of sentence idea a little bit more?
I think jeremy will talk about this as he has mentioned in the comment.
Can you explain what effect using such a relationship of training iterations for Generator vs. Discriminator over training time would have?
I’m myself testing this to have concrete results but I strongly feel that the generator is trained with a decreasingly strict manner first and then increasingly strict manner next as the training ratios decreases and then increases and has a lowest of 1.
This peak nature is inspired from lecture 8 and the idea behind this to ease up generator training initially but make it hard eventually so that it learns better.
In case this is of interest, here are results of some experiments in Cycle GAN and art generations I ran: here

Thanks!
Alena
5 Likes
I wish I could like this 100 times! 
I don’t know - it sounds like an interesting direction to experiment in!
1 Like
Hi, I’ve been pondering how to combine image generators and pre-trained image models. Intuitively, it seems like you should somehow be able to use a pre-trained image model like Resnet or VGG to jump start a generator. As in, the pre-trained model already knows about edges, curves, and more abstract features. So shouldn’t we be able to take advantage of that?
Though when I get down to actually considering the implementation, things kinda fall apart. Going from a low-dimensional space (the output class, or output dimensions) to a higher dimensional space is tough. You can’t just “undo” a linear layer, especially with something like ReLU. And same with convolutions. There are many many input configurations that could have generated the outputs at any given layer of a model. So it seems like you’d explode into some insanely huge possible input space as you went backward from layer to layer. But still, the question remains… that it seems there should be some kind of way to extract the information known from the pre-trained model.
So I guess my question is… are there any ways to extract an approximation of the input space that, when given a set of transformations (the neural net), could have been used to generate a given output? If you could, I would think that you could sample from the known possible input space at each layer, and then go from there… any thoughts on this?
From experimenting I figured that Adam and WGANs not just work worse - it causes to completely fail to train meaningful generator.
from WGAN paper:
Finally, as a negative result, we report that WGAN training becomes unstable at
times when one uses a momentum based optimizer such as Adam [8] (with β1>0)
on the critic, or when one uses high learning rates. Since the loss for the critic is
nonstationary, momentum based methods seemed to perform worse. We identified
momentum as a potential cause because, as the loss blew up and samples got worse,
the cosine between the Adam step and the gradient usually turned negative. The
only places where this cosine was negative was in these situations of instability. We
therefore switched to RMSProp [21] which is known to perform well even on very
nonstationary problems
2 Likes