I was confused how both the linear layer and embedding layer can share weights as they have different shapes
The linear layer is nn.Linear(300,len(en_itos)) whereas embedding is nn.Embedding(len(en_itos),300) .
So I went and inspected both their sizes.
It turns out
nn.Embedding(17573,300).weight.data and
nn.Linear(300,17573).weight.data
both have the same size - [torch.cuda.FloatTensor of size 17573x300] .
That’s when I realized that when we are doing matrix multiplication we do WX+b (duh)
So W will have the shape (17573,300) . But why does embedding layer have the same shape? Because it isn’t a matrix. nn.Embedding is a lookup table. . You just query a word (one of the 17573 in this case ) and get back a 300 dim vector. That’s why Jeremy could tie both output embedding and output linear layer weights.
It all sounds simple to me in hindsight, but I was stumped by this for a while. So I hope this helps anybody who was confused about weight sharing in this code
Well spotted - it’s really handy that embeddings and linear layers have the same shape weight matrices, since we use this kind of weight tying in AWD LSTM too (the decoder and encoder use the same weight matrix).
def create_emb(vecs, itos, em_sz):
emb = nn.Embedding(len(itos), em_sz, padding_idx=1)
wgts = emb.weight.data
miss = []
for i,w in enumerate(itos):
try: wgts[i] = torch.from_numpy(vecs[w]*3) <------------- Why the 3?
except: miss.append(w)
print(len(miss),miss[5:10])
return emb
Jeremy briefly mentions that the factor of 3 above is to adjust the standard deviation of the embeddings to be 1. Is this because subsequent layers expect the inputs to be normalized? I suppose that otherwise the activations will be too low, but would like somebody to confirm if my intuition is correct.
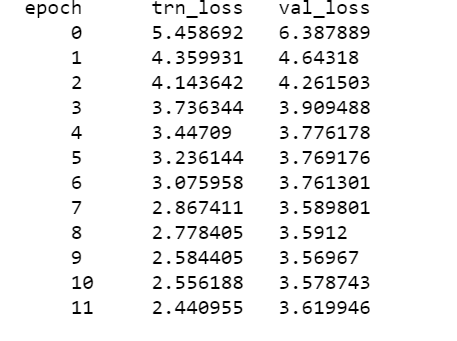
this cell takes very long time to run, on my google cloud with 26 GB ram, k 80 GPU, and 60 GB SSD, it takes forever to run.
On google colab it gets terminated or instance gets disconnected.
Normally how long should it take to run this cell?
I suppose here we are only loading wiki embeddings in a pkl format and return a dictionary of embedded vectors.
I had the same problem as you. I think it happens when you use the txt file and not the bin file of the word vecs.
But even if you use the latter, I’ve written another version of this function get_vec and posted it in this thread earlier. It should work and it has a progress bar so you’ll know quickly if it doesn’t.
def get_vecsb(lang):
vecd = {}
with open(PATH/f'wiki.{lang}.vec', encoding='utf-8') as infile:
length, dim = infile.readline().split()
for i in tqdm(range(int(length))):
line = infile.readline()
while len(line) == 0:
line = infile.readline()
w, *v = line.split()
if is_number(v[0]) and len(v)==300:
vecd[w] = np.array(v, dtype=np.float32)
pickle.dump(vecd, open(PATH/f'wiki.{lang}.pkl','wb'))
return vecd
I also struggled understanding this line of code, but more the “why” rather than the “how”.
I found it difficult to reason why the embedding weights would be a good starting point for this linear layer. Indeed convinced it should make no difference I ended up training the model without this line of code only to find it consistently did worse (however not by a massive amount).
Then i realised this - the GRU decoder layer is outputting a length 300 vector and the embedding weights are a list of length 300 vectors, so the linear layer is calculating the vector dot/scalar/inner product of the output with each of the embedding vectors. This is going to be higher if the vectors are pointing in the same direction and in this sense the max operation ends up picking a word “close” to the output vector.
On a slightly different note does anyone know why the initHidden function is required? As far as I can tell from the documentation if we don’t pass an initial hidden state to a GRU layer it just gets initialised with zeros anyway.
I think it’s mainly because the other weights are being randomly initialized to a stdev of 1 and he wants the vectors for known words and unknown words to be approximately similar in scale.
On re-watching the video for a third (forth?) time, I noticed that @jeremy was able to comment out a whole jupiter cell in two or three keystrokes. I hadn’t been aware that Ctrl+/ comments out the current line AND that Ctrl+A then Ctrl+/ does the whole cell.
Oh yea, and that Ctrl+/ will also UNCOMMENT a commented line.
Frustrated by poor translations? Try this quick and easy "fix"
I was wondering why my results were not even close to @jeremy’s, Having gone over every step in detail I “think” I figured something out. In the Tokenizer class, it’s really not ideal for our translate model, because WE are plugging in word vectors for initial weights. There will be NO word vectors for the made up tokens, so we’ll start those weights as the mean STD. I believe that this is actually worse for us then simply lowercasing uppercase words. The number iteration tokens MAY have some benefit, if each question was related in some way to the others. Anyway to try out this theory I’ve implemented the KevinTokenizer (Can you can guess why I called it the Kevin Tokenizer?)
class KevinTokenizer():
def __init__(self, lang='en'):
self.re_br = re.compile(r'<\s*br\s*/?>', re.IGNORECASE)
self.tok = spacy.load(lang)
def sub_br(self,x): return self.re_br.sub("\n", x)
def spacy_tok(self,x):
return [t.text for t in self.tok.tokenizer(self.sub_br(x))]
def proc_text(self,s):
return self.spacy_tok(s.lower())
@staticmethod
def proc_all(ss, lang):
tok = KevinTokenizer(lang)
return [tok.proc_text(s) for s in ss]
@staticmethod
def proc_all_mp(ss, lang='en'):
ncpus = num_cpus()//2
with ProcessPoolExecutor(ncpus) as e:
return sum(e.map(KevinTokenizer.proc_all, ss, [lang]*len(ss)), [])
precede upper case, sentences and mixed case words respectively. Similarly “the the” is replaced by a ‘tk_rep’ token followed by a count then the word; “tk_rep 2 the” (actually a repeat token, not a number iteration token) . These made up tokens will NEVER be found in the fast_text embeddings, so the initial weights are set to the mean STD instead. The KevinTokenizer is the same as Tokenizer except that it doesn’t make those substitutions.
BTW how are the fasttext words “tokenized” in fastext? It uses a pearl script deviced by Matt Mahoney. Which you can find Here
I agree with the first part of the sentence, but I’m not sure what you mean by: “the initial weights are set to the mean STD instead.” The weights of the embedding are randomly initialized, so while they aren’t copied from pretrained vectors, they’re not all set to the same value which to me is what that sentence implies.
Stepping back though, what does your tokenizer do differently from the base tokenizer? Does it remove those additional tokens?
I agree with the first part of the sentence, but I’m not sure what you mean by: “the initial weights are set to the mean STD instead.” The weights of the embedding are randomly initialized, so while they aren’t copied from pretrained vectors, they’re not all set to the same value which to me is what that sentence implies.
You are correct, the initial weights are random and are NOT initialized to the mean STD as I incorrectly stated.
Stepping back though, what does your tokenizer do differently from the base tokenizer? Does it remove those additional tokens?
KevinTokenizer doesn’t remove any tokens, it just doesn’t add ones that we’re sure will NOT be found in fasttext.
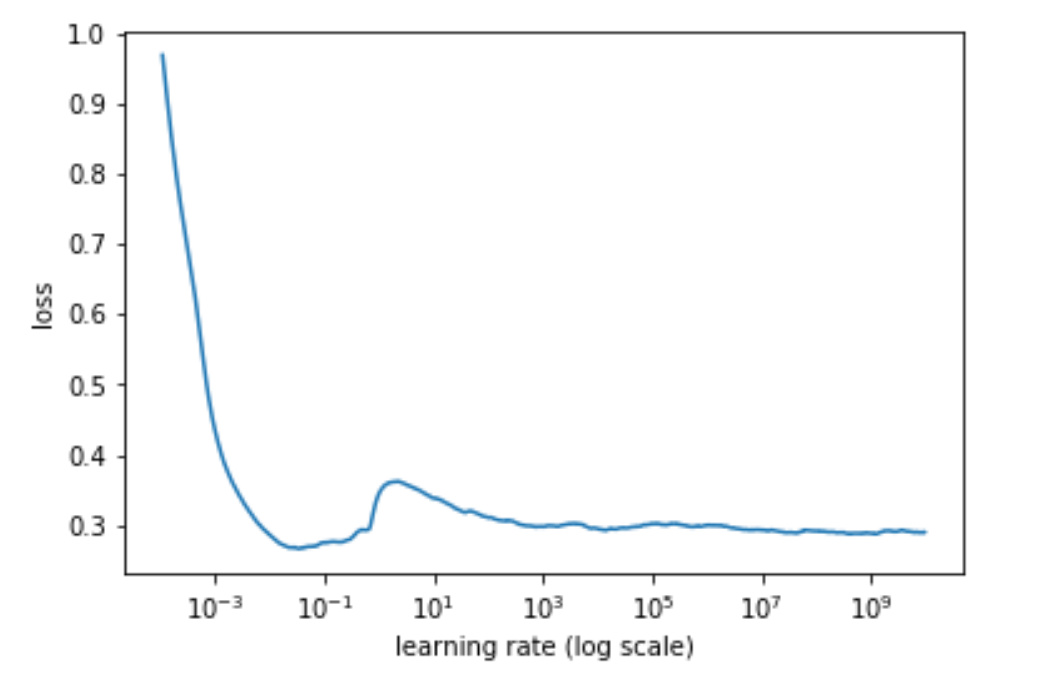
It doesn’t make sense. I just didn’t want the lr finder to run for ages, so I used a high max in the hope the loss would get really big and it would stop early. But that only worked for l1 distance, not cos similarity. The LR you want it the one before it hits the first bottom. You can just interrupt the lr finder once it starts getting much worse. (If you interrupt the LR finder you’ll need to recreate the model, since the last thing it does is reloading the original weights, which it can’t do if you interrupt it).
The thing that doesn’t make sense to me is why it doesn’t blow up until 1e+11 (see earlier plot). How can it NOT get a huge loss or explore in some other horrible ghastly way at some huge learning rate? That’s the thing I can’t wrap my mind around.
Cosine loss is bounded by one, so it can’t go up to infinity like our usual losses. I think the last flat part is just random noise averaged over the training set.