This is fast approximate nearest neighbors…the guy who built the nearest neighbors for spotify, also invented a method called annoy benchmarked all these methods - nmslib is the most incredibly fast way to find nearest neighbors in high dim vector space.
The other way to do this is k-means clustering (or even better, vector quantization) - but for this example, fast approx KNNs work really fast.
Personally, I enjoyed the last 20minutes like anything. The ease and the elegance with which the concept was explained and the simplicity of the implementation with what we already know from fastai library was quite phenomenal.
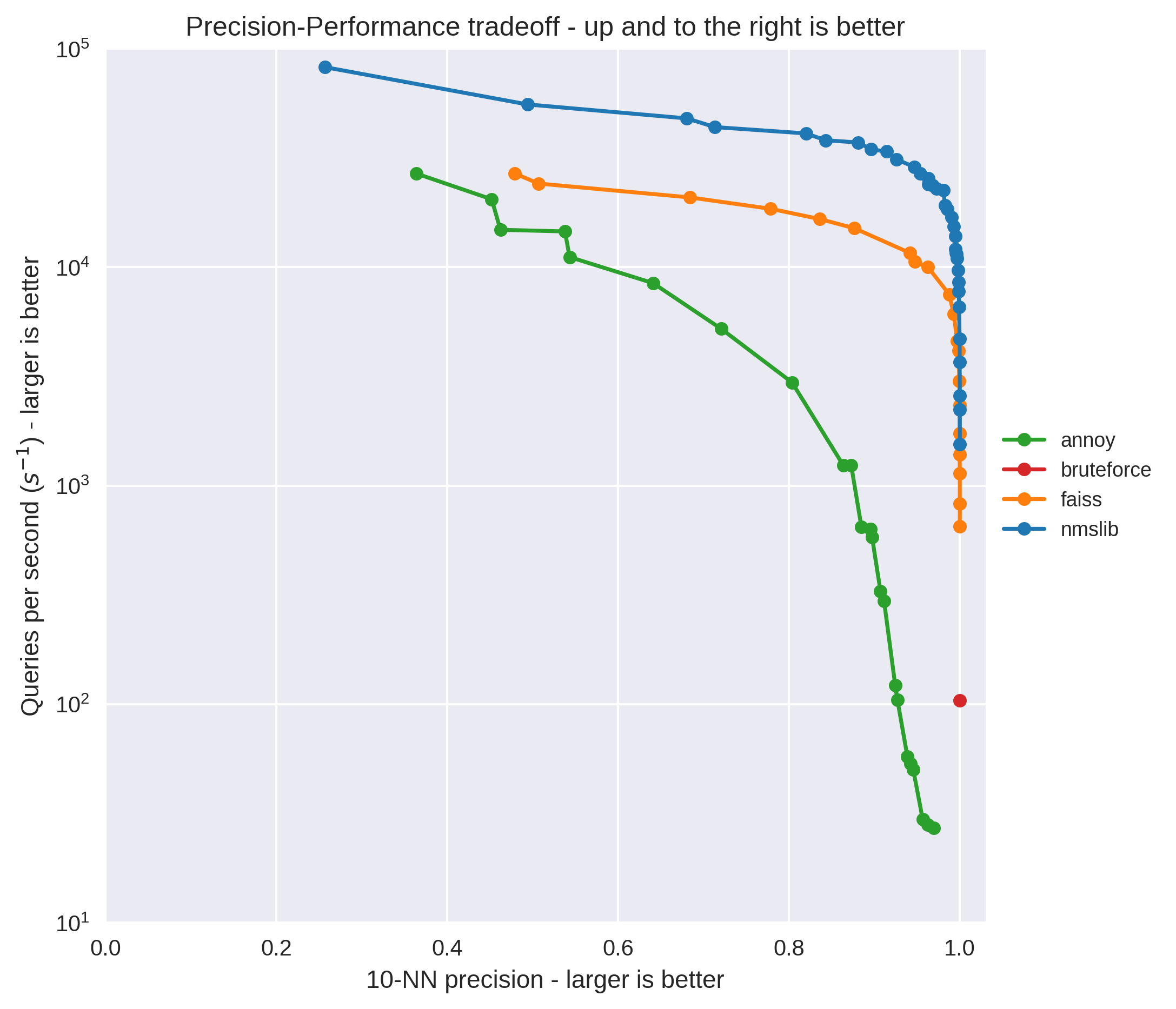
On the approximate nearest neighbors front, a friend has a great blog post outlining the tradeoffs of precision vs performance that’s definitely worth checking out.
One thing that’s worth noting is that if you’re building a production system FAISS on GPU is an order of magnitude faster than NMSLib. NMSLib runs at 200,000 QPS (Queries per second) in batch mode on the CPU (Core i7-7820x), and the GPU version of Faiss runs at 1,500,000 QPS on a 1080ti.
Faiss used to be a pain to setup but I believe they recently added pip support. I’m not sure if that includes the GPU aspect, but it’s worth considering if you need to do this at scale.
Yes I expect so - I don’t know if it would help; it’s basically the same idea as cyclegan. I’m not really fully up to date on the translation literature, so dunno if this has been done before…
Can I ask a favor - the top wiki post hasn’t been edited yet, but there’s lots of good links and resources in the replies here. If anyone has a moment would you be so kind as to add them to the top post?
Jeremy mentioned in the video we can now download has the link from Kaggle. Does anyone have the link? I can find the object detection challenge but not the usual classification challenge.