interesting, I do a subset with 1/100 data, get over fit very quickly with very different loss with adrian.
Results of Classification model with tradeoffs:
When I ran the classification model with Unfreeze, having 8GB of GPU memory forced me to use a BS of 16 and my results were (0.19827, 0.9427). When I ran the last classification model with freeze_to(-1) instead, I was able to run with BS=48, but the results were (0.1718,0.93818). Unfreeze works better even with a much smaller batch size; which as @narvind2003 pointed out; is probably because we’re re-training a LM to do classification.
Okay, I pored through the fine annotated notebook and now I understand: there are amazingly some words in the IMDB set which are NOT in the IMDB set, and in order to capture those, we need to make a new word->code mapping instead of just using the wikipedia103 word->code mapping.
I had not realized that there would be so many words of frequency > 2 (like melodramatics, phillipino, fantasyfilmfest, etc.) in the IMDB database which would not be in Wikipedia103.
1 Like
Exactly!
It’s crazy the kind of stuff people write in movie reviews!
May I ask how long if it takes for training 1 epochs for you?
I am now training on GCP. Would like to know what’s the speed for people who have a GPU like 1070 1080 or 1080 Ti. It’s kind of annoying as I was using the cheap preemptive instance which I found GCP keep terminate my instance when I train for >30 mins. I now move to a normal instance with P100, hoping it can finish training overnight.
With K80 it takes ~ 1.5 hours. Roughly 1.5 iteration / s
With P100 it taks ~25 mins. Roughly 4 iteration / s
Yes, I am aware of overfitting. However, earlier @adrian did the same thing with a subset of data and get a quite different loss. I was curious why I get such a different loss compare to him. I did not have time to investigate it though, as I train it before I went out and my instance get terminated by Google before I come back. 
I haven’t look into the model architecture, but I guess the model is just too large if I am only using 1/100 of the data.
Thanks.  So it’s roughly comparable to GCP’s P100. Glad to know P100 is not too bad. Hope I can finish the training overnight.
So it’s roughly comparable to GCP’s P100. Glad to know P100 is not too bad. Hope I can finish the training overnight.

I did a git pull and I am seeing this error. Anyone else?
/mnt/work/fastai/courses/dl2/fastai/torch_imports.py in children(m)
22 warnings.filterwarnings('ignore', message='Implicit dimension choice', category=UserWarning)
23
---> 24 def children(m): return m if is_listy(m) else list(m.children())
25 def save_model(m, p): torch.save(m.state_dict(), p)
26 def load_model(m, p): m.load_state_dict(torch.load(p, map_location=lambda storage, loc: storage))
NameError: name 'is_listy' is not defined
Git blame points me to this commit X hours ago
Yes is_listy from core isn’t imported
1 Like
Oops! Fixed now.
2 Likes
I was stuck on this for a while as well, but looks like it is resolved now.
Oh sorry I made an incorrect comment about the earlier post’s val loss and accuracy based on me mis-reading it - I’ve deleted my comment and the replies now so others don’t get confused!
2 Likes
Ok now I’m really confused. It’s just plain old overfitting right?
Yes please ignore everything I said in my now-deleted comments.
1 Like
I have a question about epochs/sampling.
The “standard” way of training a model is to go through the entire training set multiple times (i.e. multiple epochs) by shuffling it at the beginning and splitting it into mini-batches.
I’ve also seen some people don’t use epochs and this type of shuffling of the training set. Instead, they just train the model on mini-batches, randomly sampled from the training set. Occasionally, the training set is reshuffled (to make each sampled mini-batch different).
How the second approach compares to the “standard” one?
Also, the second approach (without occasional reshuffling) seems great for the sequential data: given that you’re already grouped your sequences into batch_size blocks (e.g. 64), you can just sample a starting position and bptt window size to get a next mini-batch. If you ignore a few first and last characters in each batch_size part, all characters have an equal probability to be chosen. It should be better than just a sequential sweep through the training set, because it adds more randomness to the training process, along with the random bptt sampling. Does this make sense, or maybe people and fast.ai already do this?
Hmm… interesting. The second approach doesn’t guarantee that all training samples will be considered, correct? I’m not sure if that’s a good idea if you have a smaller dataset to train on.
We could combine both approaches and see if it helps with the training in any way.
Also, for sequential models it depends on whether you need the RNN to be stateful. For classification, there is an explicit need to preserve the full input sequence (like a full movie review).
But fast.ai data loaders make it possible to try these options fairly easy.
They’re close enough to identical, once you’ve done a few epochs.
It makes a lot of sense - the approach we stole from AWS LSTM that we mentioned in the last lesson is similar to this, but each batch ends up on a randomly different starting point. I can’t see any benefit from doing both of these.
Feel free to experiment, of course!
1 Like
Would you give a little hint what you were thinking initially?
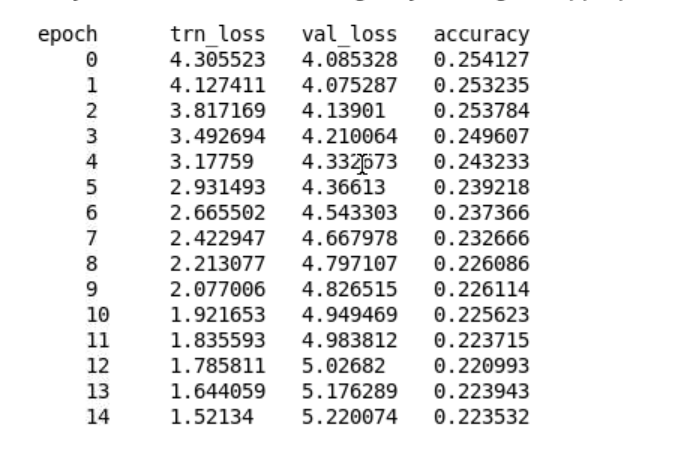
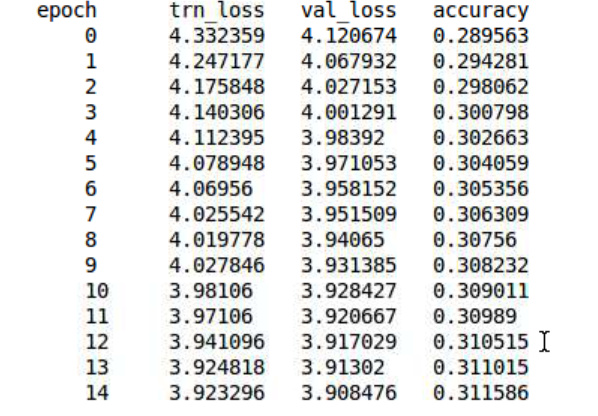
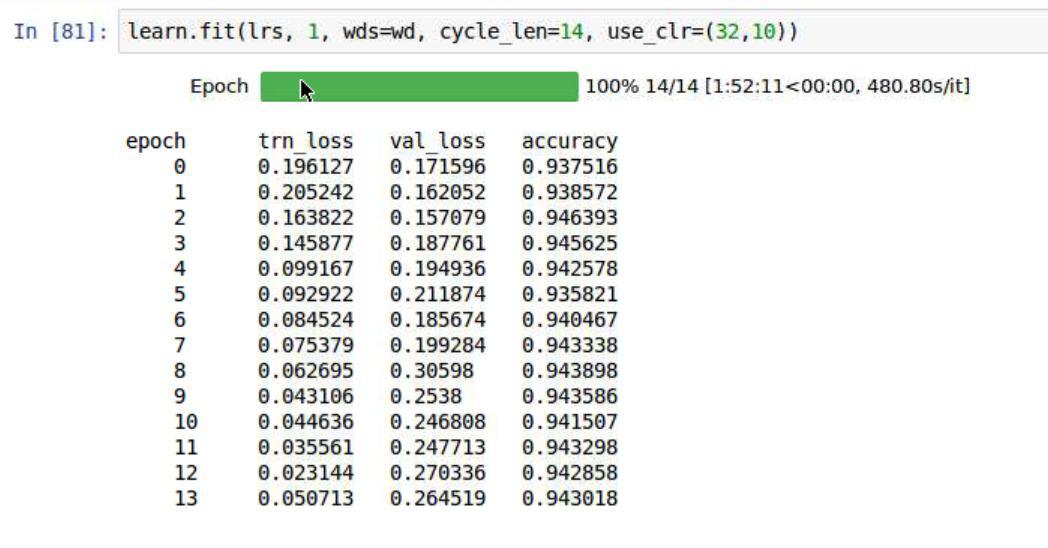
After training overnight with full dataset, I overfit my classifier again. I notice in the original notebook, in second epoch the validation loss goes up a lot. Not sure why I overfit so much, as I almost change nothing except I don’t have time to train full 15 epochs for my language model and has slightly higer loss.
My Language Model:

Notebook langauge Model:
My Classifier:
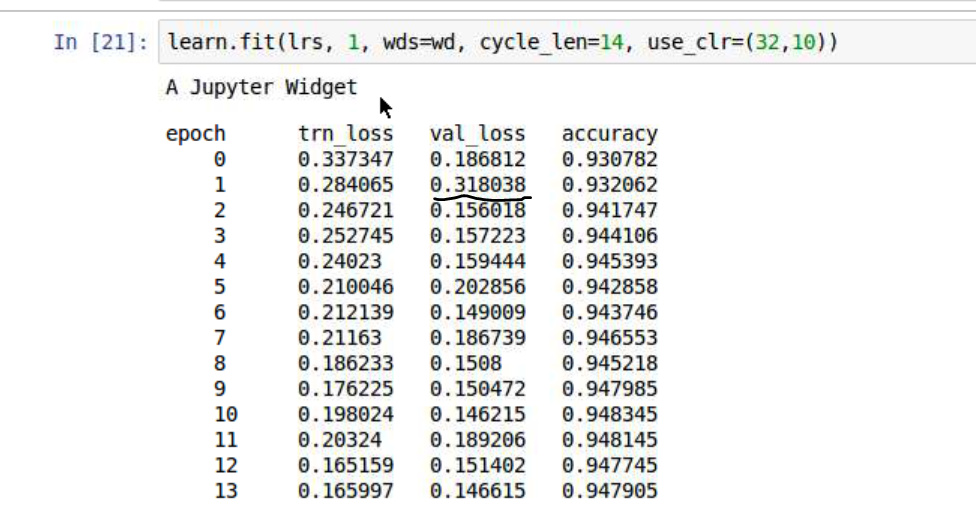
Original Notebook:
I found your notebook with comments highly useful - have spent hours going through it 
Thanks a lot for sharing this!
2 Likes