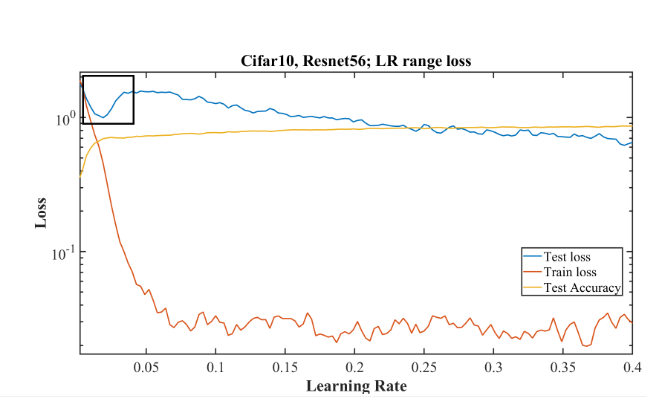
… the test loss within the black box indicates signs of overfitting at learning rates …
I understand that as the training loss is less than test loss it means we are overfitting. But isn’t that true for the whole graph? I mean the test loss is more than train loss everywhere. So why does this box indicates signs of overfitting?
Question#2
Leslie shows this picture in which he mentions that the plateau is what we want to achieve for optimal model.
But same as before the test loss is higher than training loss. Doesn’t that mean we are overfitting already to the training data?
Question#3
Leslie mentions this
The takeaway message of this Section is that the practitioner’s goal is obtaining the highest performance while minimizing the needed computational time. Unlike the learning rate hyper-parameter where its value doesn’t affect computational time, batch size must be examined in conjunction with the execution time of the training.
I did not understand the part when it is said that learning rate’s value does not affect computational time. The computational time per training, per epoch? What is computational time referring to here?
The point here is that you can observe in the early phase of the training process: you don’t need to spend hours to do practical hyperparameter selection.
This is true, but slight overfitting is OK, it can be due to the fact that train and validation sets don’t have perfectly equal data distributions. Our main goal, for the given train/validation datasets, is to minimize the validation loss by choosing the right hyperparameters.
Changing the batch size does affect the total computational time. Usually, there is an optimal batch size for a given problem and hardware combination. I’m not sure, but I think that larger batch sizes on GPU are always better, as long as a single batch fits into GPU memory.
I get the part with batch size affecting total computational time. Because the number of iterations per epoch is reduced with each iteration having more data. But doesn’t higher learning rate do similar thing? Not per epoch but in terms of number of epochs needed.
Hmm, this is interesting, I’ve never thought about it. I guess he is talking about per-epoch time then. I like to think about those types of problems in the budget terms: for a given problem and hardware resources, what are the hyperparameters (from learning rate to net architecture) that give you the best performance for a given amount of time? In that formulation, learning rate doesn’t change computational time, while batch size does (you can do more or less forward/backward passes for a given time).
Learning rate does change computational time in terms of budget. If my learning rate is very small it might require me to run more epochs. Thus my p2 instance would need to run for longer period of time. If it is large p2 instance might need to run for smaller period of time. Am I wrong?
I’ve meant that in the “budget point of view” you don’t run the training until a certain performance is achieved (e.g. I want >90% accuracy, and that would require to train a model for at least 21 hours), but vice versa: you have a fixed time interval, and you want to get the smallest validation loss in during that interval (e.g. I only have 12 hours to spare, and the best accuracy I can achieve is 85%).
No we’re not actually overfitting unless the test loss is increasing. Having better train than test doesn’t mean you’re overfitting. At the start of the graph you can see the test loss increases for a while.
Ok. That explains it. So far (since Part 2017) I thought that as soon as we see validation loss > train loss we have started to overfit. That was confusing for me while watching the language models too. I thought we are overfitting always why are we continuing? That becomes a separate discussion then which I will do separately after thinking about the lectures a bit.
Just remember: our goal is a model that does as well on the test set as we can make it. There’s no reason that this would happen when the training set error is higher than the test set - in fact, that would be most unusual.
In Part 1 didn’t we stop after the epoch when training set loss got smaller compared to validation set loss? At that point you mentioned now we are overfitting. We did not stop at the point where the validation loss increased. Also just to be precise when we say overfitting in general we mean overfitting on the training set, correct?
Question, did you mean validation set in the above statement? Because on a on-going basis we compare train with validation rather than test set. test is kept till the end as per the separation of train/valid/test.
This is also a confusing thing in Leslie’s paper (he does mention it explicitly but still confusing) is that he keeps on using test or validation interchangeably. If he is doing the hyperparameter tuning on a test set then all of my understanding of train/test/validation is wrong. Or the paper is confusing.
No I certainly hope I never gave that impression - I’m sorry if I did!
It’s pretty common - I do the same, unless it’s a case where it matters. Generally you can assume people are talking about a validation set, unless it’s obvious otherwise from the context.
I am watching the intro to machine learning Lesson 2. At https://youtu.be/blyXCk4sgEg?t=1434 you mention that we are overfitting when the the score for validation set is less than the score for training set. So is the intuitive way of when we are overfitting different in deep learning compared to Random forests?
I occasionally interview researchers through my affiliation with MLConf. This time, I learned I could interview whomever I wished, and Leslie Smith was the first person to come to mind. Also, I had googled him, and there was limited info on his career, so I was interested in learning more.
This is such a good paper. I love how practical it is and straightforward it is. I wish more papers had Remark sections! I completely missed this paper initially, but I will definitely be reading more of Leslie Smith papers going forward. That interview was awesome as well. Nice job Reshama!
One takeaway I am seeing from the paper is about weight decay:
If you have no idea of a reasonable value for weight decay, test 10−3, 10−4, 10−5, and, 0. Smaller
datasets and architectures seem to require larger values for weight decay while larger datasets and
deeper architectures seem to require smaller values. Our hypothesis is that complex data provides
its own regularization and other regularization should be reduced.
This paper is a gem for the practitioner. Despite had already seen many of those suggestions in the Fastai videos, it was good to understand a lot of the rational behind on why this or that works and to give attention to some ideas that are less discussed in the videos (as all the discussion about weight decay as @KevinB said) .
One question that came to my mind is: If we should use the largest batch size our GPU memory allows, and given that the size of the network does not change during training, one could calculate the maximum (optimal) batch size considering GPU memory, network size and frozen layers and never running out of memory. Right?
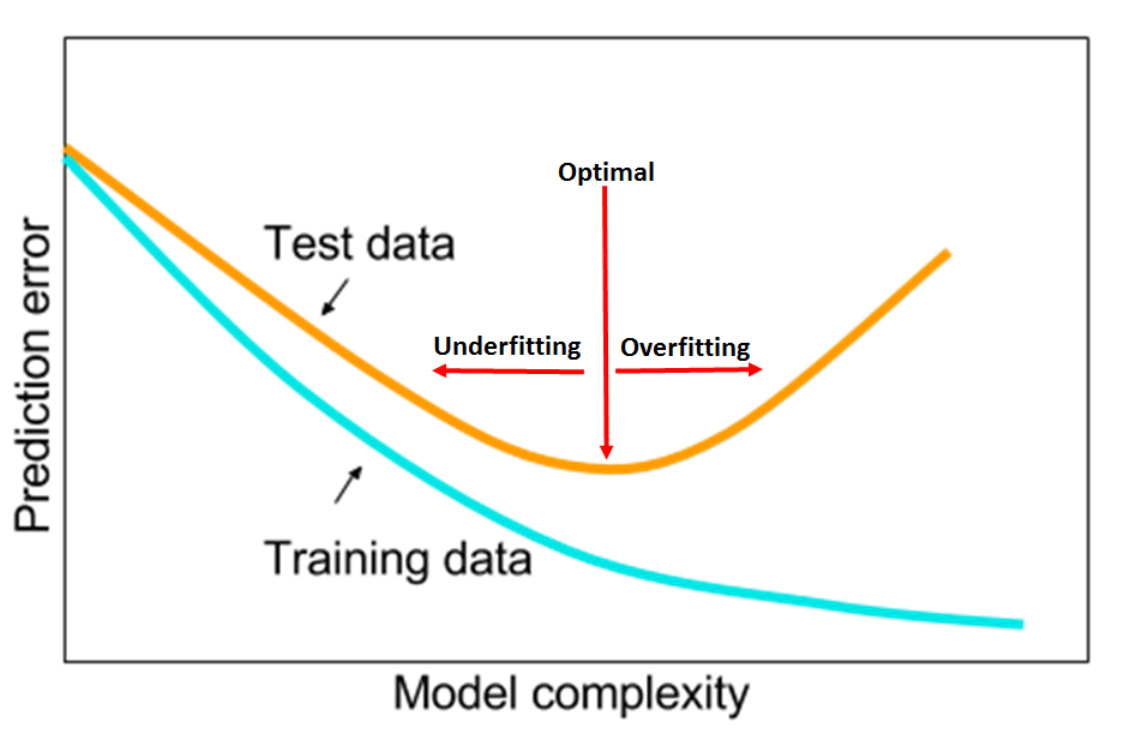
 But yes the intuition is very different - for DL having a much lower training loss is pretty common.
But yes the intuition is very different - for DL having a much lower training loss is pretty common.
