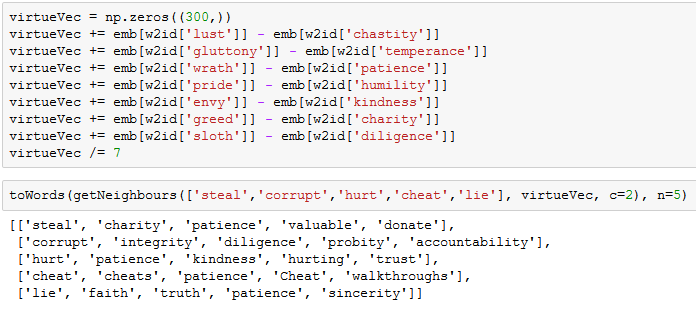
I’ve tried scoring a few articles from different sources all relating to Trump’s brilliant handling of the summit with North Korea. Results as follows - in ascending order of linguistic flair!
source
score
CNN
0.026314
BBC
0.034686
Guardian
0.042723
New York Times
0.044835
Washington Post
0.047775
New Yorker
0.050230
Financial Times
0.051934
Reuters
0.058019
I wasn’t expecting the FT and Reuters to feature at the top of this leader-board. I think its probably has something to do with the tiny sample size (1 article), which is then skewed by certain quotes within the text.
As a further test I’ve tried it on a very reliable source of wordy prose - the London Review of Books (something my more learned friends enjoy). A random article from here scored a whopping 0.089, so I guess the measure does work a bit.
By the way, the score is the average per word score above a certain threshold, i.e. it is just measuring the average frequency of particularly high scoring words.
@sermakarevich Regarding toxic comments competition: I had the impression that good end result was heavily dependent on preprocessing and not so much on the actual nn model. Can you comment on that? Did you experiment of how big of an impact was made by prep step vs model? Thank you for sharing you work! Really appreciate, I was struggling with this competition myself also
First of all the scores on the leaderboard were really close for ~ 25 - 50% of participants. So I would say most of people had really good models. The difference on the leaderboard made:
cleaning, yeah
robustness
augmentation
How much it helped it is really hard to say as it is almost impossible to run your 20-30 models without and with text cleaning. Robustness was about training different models with different architectures, different embedding vectors, different cleaning, hyper - params and being able to blend them properly with OOF predictions of the train set. Augmentation was about translating comments into other language and back.
A couple of days ago our gold medal was lost because some team which was banned proved their innocent. Glad this happened as I cant imagine the disappointment when you worked for 2 months and then don`t have even submission history.
@er214, in your blog post, you talked about how you found the spelling error vector in a GloVe embedding, but when you tried again with an embedding trained on Wikipedia, the signal was much weaker.
I see from posts in this topic that you used Common Crawl, but you didn’t mention that in the blog post, might be helpful.
@Ducky Thanks for all your comments and edits on the blog. Much appreciated!
Regarding the points about IMDB versus BBC news, I was hoping for a more distinct difference in the formality score distribution much as you suggest. However, the scoring metric correlates highly with word frequency. So, very low frequency words get similar scores to misspelled words. This skews many of the news reports since they often include rare proper nouns.
I’m trying to think of a way to remove this word frequency effect- leaving just the spelling/formality effect, but not sure how to go about it. Maybe some kind of denoising technique might work?