I still have to port that functionality in the TrainingPhase API.
Just a quick question, should I default use_wd_sched to True if Adam is used as an optimizer and there is weight decay?
Please tag me when this functionality is ready as I’ll be very interested to run experiments.
I don’t think we have enough info to say. We all need to run experiments with and without this setting and figure out whether it generally helps, hinders, or does nothing! Ideally, we should endeavor to test for each of transfer learning and training from scratch, for each of NLP, computer vision, tabular, and collab filtering. One student in SF study group did some quick tests last week with CIFAR10 and I think was seeing some signs of use_wd_sched being better.
Note that it’s not just for Adam - it should (according to the paper IIRC) improve anything with momentum, or dynamic learning rates (like LARS I guess).
Also, we should rename it, since it’s got nothing to do with sched any more, right? The name we give it may depend on what we use as the default - if we decide to default to this new approach in the future, then maybe we actually call it wd_loss and default it to False (to show that weight decay is happening inside the loss function).
Okay.
Implementing this right now but I wonder if there isn’t a bug in the current implementation: the weights are upgraded without weight decay then we subtract wd * old_weight.
Shouldn’t it be wd * lr * old_weight? That’s the formula in the paper.
1 Like
I would have thought so, yes!
Hey @ZachL, now that Jeremy accepted my PR, you can use this in the TrainingPhase API. Just add the argument wd_loss = False at some point to tell the TrainingPhase you want the weight decay to be computed outside of the loss.
Example:
phases = [TrainingPhase(1, opt_fn=optim.Adam, lr = (1e-3,1e-2), lr_decay=DecayType.LINEAR, wds=1e-4, wd_loss = False),
TrainingPhase(2, opt_fn=optim.Adam, lr = (1e-2,1e-3), lr_decay=DecayType.LINEAR, wds=1e-3, wd_loss = False)]
Don’t forget to do a git pull before to have the latest version of the library!
3 Likes
Fantastic! I will get started on my experiments right away but my initial findings may not be ready for at least a few days.
I’m trying to get the new weight decay functionality working on the collab filter dataset but receiving an error on the call to fit_opt_sched. Do you think the TrainingPhases api is incompatible with the CollabFilterDataset get_learner method? Not sure what’s going on here.
Here’s the notebook, error at the bottom:
We’ll need to ping @sgugger about that one! Not sure it’s been tried before…
Weird, I just run your notebook on my laptop without any problem. Are you sure you have the latest version of fastai?
Restarting my computer fixed the problem (??). Weird.
I have run a number of experiments and included them in the same notebook accessible here: https://github.com/zachlandes/fastai/blob/master/courses/dl1/adamw-tests.ipynb
So far, with a little bit of experimenting with weight decay, the vanilla Adam implementation with cosine annealing (is the version I’ve implemented the same as that used by fast.ai when not using the TrainingPhases API?) is achieving the best score of .758 on the collab filter problem.
Results, from best to worst:
- no weight normalization and wd_loss = True: .758
- weight normalization and wd_loss = True: .761
- no weight normalization and wd_loss = False: .784 (massive overfitting)
- weight normalization and wd_loss = False: .828 (achieved in third epoch) (massive overfitting)
In general, it seems that decoupling weight decay from loss function leads to overfitting. Also, it looks like weight normalization as suggested in the paper shrinks weights too aggressively, leading to poorer performance. Note that I only tested on movielens so far, so I’m curious how this will do on an image problem.
Thoughts?
1 Like
I didn’t have time to experiment on this fully yet, but on my experiments to check it worked (on cifar10) I got a lower loss with wd_sched=False with Adam, and the same as wd_sched=True with SGD.
It might also be that the change impacts your best learning rate or your best weight decay value.
1 Like
Sylvain, we are getting so many wonderful things through your work  I think I have now learned how to use the 1cycle policy (the concept of using lr for regularization is so immensely cool) and now starting to use docker following the howto by @hamelsmu and about to play more with the SWA by @wdhorton
I think I have now learned how to use the 1cycle policy (the concept of using lr for regularization is so immensely cool) and now starting to use docker following the howto by @hamelsmu and about to play more with the SWA by @wdhorton
Ah, the power of community
Learning the training phase API will be next thing I’ll give a go once I am able to update to the newest version.
Question - if I am reading this right, wd_sched=False will calculate the decay using the most up to date code with the bug in the equation removed?
BTW this training phase API is very cool. If Jeremy does attempt a rewrite of the library this seems like a very nice thing to use as the basis for implementing other, higher level abstractions (like the implementation of all the other training schedules you show in the notebook)
Thanks radek!
It is wd_loss = False (not wd_sched  ) and yes, it will compute the decay outside of the loss. It isn’t thoroughly tested yet, as ZachL pointed out, but I plan to get on it soon!
) and yes, it will compute the decay outside of the loss. It isn’t thoroughly tested yet, as ZachL pointed out, but I plan to get on it soon!
1 Like
@ZachL I just did one simple experiment this morning and ran the LR Finder with wd_loss=False and wd_loss=True, and there are different indeed (this on a convolutional neural net on cifar10).
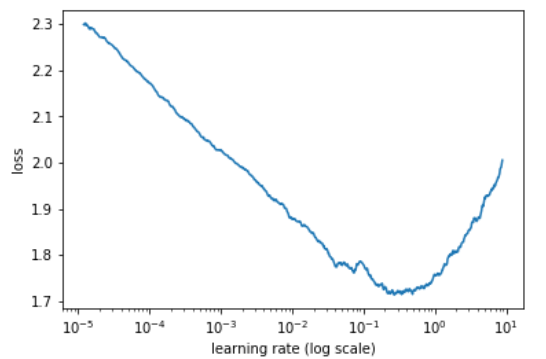
This is with wd_loss=False. Minimum is at 0.3-0.4 so 3e-2 seems like a safe LR while being high.
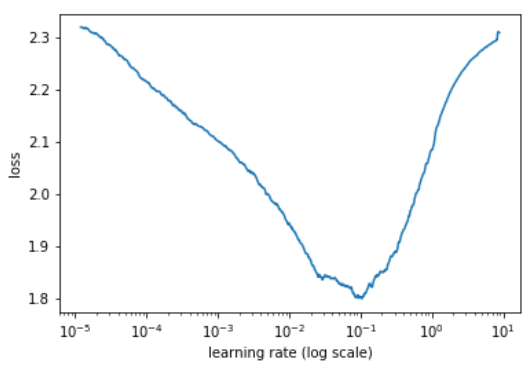
This is with wd_loss=True, and not only is the minimum lowest (1e-1) but also the divergence is more pronounced so going further than 1e-2 for a max LR would be very risky.
Then I ran the a standard SGDR training (cosine annealing with restarts) with 3 cycles, cycle_len=2, cycle_mult=2 and found it fared way better with wd_loss=False (82%accuracy with lr=3e-2, 83% with lr=1e-2) than wd_loss=True (65% with lr=3e-2 (too high indeeed), 73% with lr=1e-2, 79% at 5e-3).
Like I said earlier, the different weight decay regularization affects your best choice of learning rate (it might also change the optimal value of wds), so be sure to always a learning rate finder that reflects the conditions of training. How? With the new training API of course  This is how I got my first picture:
This is how I got my first picture:
phases = [TrainingPhase(1, opt_fn=optim.Adam, lr=(1e-5,10), lr_decay=DecayType.EXPONENTIAL, wds=wd, wd_loss=False)]
learn.fit_opt_sched(phases, stop_div=True)
3 Likes
Hey sgugger - very promising! I spent maybe an hour playing with the API to find and test different learning rates yesterday. I am a little confused (there’s definitely something I’m missing) - the trainingphases notebook suggest using either exponential or linear decay for learning rate finding. But as you can see in my notebook, I use cosine annealing of learning rate for all phases. How would you proceed? By the way, after a bit of experimenting with learning rate I was able to reduce the loss a bit for the wd_loss=False learners, but the rank ordering remained the same. I’ve added the experiments to the notebook in github. I will try using the learning rate finder and playing with it a little bit more, but my suspicion is that Jeremy was right about shallow networks not benefiting as much from wd_loss = False.
It’s possible it doesn’t work in this case, of course.
For the LR Finder, when I say you should run it so that it reflects the conditions of training, I’m talking about all the parameters except the learning rate: this one should go from a minimum value to a maximum value, either linearly (if those values are close enough) or exponentially (if they are far apart). It doesn’t matter how you do your training after, this is the best method we have to pick a good learning rate (and the one used in lr_find()).
The others parameters (momentum, wds, wd_loss, optimizer) should be the same ones as in the training.
1 Like
Will these functions work with PyTorch 0.4? I tried updating today so that I could compare AdamWR against amsgrad, but I discovered that there is a new required argument for all optimizers, including optim.Adam, namely params. When using fast.ai’s ConvLearner.pretrained() (which I call learn) with resnet34, I am not sure what to pass as the model params to the optimizer. Any idea? If I try learn.model.parameters() I get the error
ValueError: optimizing a parameter that doesn’t require gradients
I had read that all the notebooks were working with pytorch 0.4 but obviously this required params argument is a breaking change…
Please let me know if I’m missing something obvious!
Edit: I should note that I tried:
opt_fn=optim.Adam(filter(lambda x: x.requires_grad, learn.model.parameters()), amsgrad=False)
Which solves the above ValueError but then learn.fit no longer works
TypeError: ‘Adam’ object is not callable
Scroll to bottom of this notebook for full traceback: https://github.com/zachlandes/fastai/blob/master/courses/dl1/dog-breeds.ipynb
Try
opt_fn = lambda *args, **kwargs: optim.Adam(*args, amsgrad=False, **kwargs)
insead of
opt_fn=optim.Adam(filter(lambda x: x.requires_grad, learn.model.parameters()), amsgrad=False)
2 Likes
That worked, thank you! Can you tell me why it worked?
By the way, AdamWR gave me slightly better results than amsgrad - in both cases with wd_loss = False.
Edit: I should say, nearly indistinguishably better…
1 Like