I humbly come to you looking for troubleshooting advice on how to correct degraded performance on my system, undoubtedly due to uncontrolled changes in my environment.
In short
Training (aka batch processing) is still as fast as I experienced with my early goings and on par with other posts from lesson 1 and 2. But validation now takes forever (about 2s per image). So even on sample size scale it’s unworkable.
Question: what happens during validation that I might have sabotaged?
In long
My setup: AWS P2, fastai AMI, Python 2.7, Keras 2
In my Jupyter notebook, the batches get processed very fast until the ultimate one where it hangs for a long time. For example:

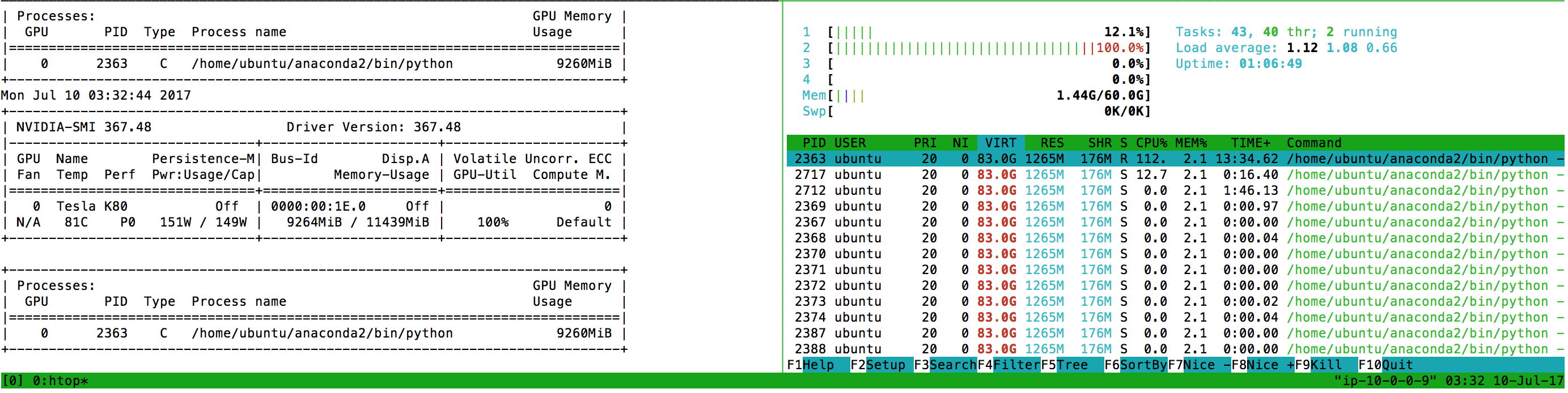
I’m confident the GPU is being used for both training and validation. Below is a screenshot with nvidia-smi and htop output. I suspect the GPU is asked to do something inefficient/dumb, but I don’t know what it is.
Here is a notebook screenshot hinting that cudnn and cnmem are enabled:

I did some basic Python profiling, using lprun, to understand where the time is spent. I think it has confirm what is plain to see in Jupyter. That is, most of the time is spent in the test_on_batch() (keras/engine/training.py) and not very much in train_on_batch() (same source file)
Next steps
I understand I have the nuclear option: wipe out my EC2 instance and restart. I may still do that.
But this feels debuggable. I just don’t know where to go next. Thanks in advance for your advice.