Maybe it’s overblown, I’m not entirely sure. I haven’t run the tests myself. I’m going off of what’s in this blog post. Andrej Karpathy said as much as well, so I’m inclined to think it’s an issue worth thinking about. But I’ve not seen any tests comparing the two.
The only thing I can find from Karpathy is a tweet about this, and there is no reference to a source: https://twitter.com/karpathy/status/869289384687714304
(In an older tweet he actually asks whether PCIe lanes are a bottleneck, so at that point he wasn’t sure himself: https://twitter.com/karpathy/status/648263066304446465)
Several of the replies to both these tweets are from people who say the PCIe lanes actually do not appear to matter.
This whole thing seems to be a myth that gets repeated whenever the subject of building your own box comes up. Not very good science. 
If you’re building a box with 4 or 8 GPUs, then definitely do pay attention to the number of PCIe lanes. You’re going to need a higher-end CPU and motherboard for this anyway.
But if you’re just going to be using 1 or 2 GPUs, it does not seem to matter (as long as the motherboard supports an 8x/8x split between the first two PCIe slots).
When I was building my own box I got concerned about this too because every single blog post says you need to get > 16 lanes. But then I asked a friend who had recently built a 2-GPU box on a motherboard with just 16 PCIe lanes and he wasn’t even close to maxing out his PCIe bandwidth even with both GPUs running at full speed.
It’s just not an issue for 2-GPU systems, and so you can save yourself some money because you don’t need the high-end CPU and motherboard.
3 Likes
edit: I just went for it and the fans turn on after a certain temperature 
OK here’s a weird one — I finally got my system up & running with all the drivers configured (8 hours later…), but when I run a PyTorch example on the GPU, my fans aren’t spinning.
Card is the EVGA 1080Ti FTW3; cursory googling says that they might not come on unless the temperature reaches a certain threshold, but before I go crazy and destroy my card does this sound right?
Hi!
I currently have a setup with a GTX 1060. I want to upgrade to a GTX 1080 ti. I’m thinking of getting the founders edition card by asus or gigabyte, but am worried about the sound levels.
Anyone else who’s got a founders edition 1080ti? Is it too loud? My PC is in my bedroom, right next to my bed and I’m worried it may be too loud.
What speeds do the fans run at while training?
Did you get the Hybrid card (i.e. with water cooling)? Mine never goes over 40C and the fan never spins, but that’s the water-cooling doing its job.
The Founders Edition (FE), or the later/custom version also known as “Aero” or “TurboFan” by some vendors, have a “less” efficient cooling system, in theory, than the pure Gaming versions with 2 or 3 oversized fans.
Now the real benefit of FE or Aero, imho, is that their cooling system expels the air directly “outside” your PC case, as opposed to the Gaming versions who basically blow it “inside” your case, and around your CPU cooler (not cool to cool when you get hot air as a cooling source), thus transfering the heat expulse to your case fan in the end (usually a basic 120mm in the rear, fighting alone vs the 120mm CPU cooler and the 3x80mm GPU fans, plus the heat sum of powersupply, motherboard, rams, HDs etc.).
If you’re concerned about your PC cooling/fan noise while sleeping, here’s a cheap solution: https://mynoise.net/, no joke.
Or this one, even more basic but still very efficient to trick your brain to ignore fan noises after 30 mins or so: https://rain.today/
1 Like
@machinethink I didn’t. I got a Founder’s Edition card, it was available for much cheaper from a guy who wanted to buy a laptop instead! 
@EricPB I did do my research on the FE cards. Looks like they’re the way to go if building a system with multiple GPUs! Thanks for the sites, they look interesting. I’ll try them out soon.
Haha, I’m assuming this means that those cards make noise, I’ll find a way to live with it.
@shreeyak You can’t cheat the laws of physics 
If your 1080Ti GPU is running at 85°c under load, and its fan(s) run at 3200rpm for several hours (I use Psensor on Ubuntu), that extra heat has to go somewhere. Inside the small wolume of a PC case = bad idea.
Now using a water-cooling system might be a solution, though more expensive. Plus, afaik, any watercooling system, whether for CPU or GPU, requires a dedicated spot on the PC frame to place its cooling/exhaust fan/radiator. On most standard PC cases, that spot will be in place of the regular 120mm air-fan in the upper rear panel. If you use it for your watercooled GPU’s fan, then you’ll need another spot for the regular 120 mm air-fan (the one in charge of expulsing the hot air from your non-watercooled CPU cooler + all the heat sums).
If you go for one GPU watercooled and one CPU watercooled, then you’ll need a case with 3 spots (water + water + air) for exit fans.
It exists, it’s not rare but more expensive, so you need to think this through in advance when choosing your PC case.
Last tip: when running 6-hours+ model training with CPU/GPU at 80%+ workload, open your PC case by taking off the side panel and “let it breathe”.
Some will say “No way, it will screw up the internal airflow designed by the engineers”.
My experience is “All the temperatures dropped, so screw the engineer ‘internal airflow’ gibberish and I’ll stick to the data”.
So try it and look at the Temp/FanRPM data from Psensor & co.
Last tip after the last tip: your PC case air intakes (usually in front and below) are insanely efficient at gathering all the dust in the flat/room, think of your PC case as a vacuum-cleaner always on.
Especially if placed on the ground (vs. on a desk/shelf) and uber-especially if you have a pet dog bringing all kind of shit in his fur/pelt twice a day.
Using a real vacuum-cleaner on those air intakes once a month can do miracles 
3 Likes
@EricPB thanks for such a detailed reply!
Those are exactly the considerations that made me get a founders edition card! Ordered one yesterday. Will be starting this course next week (I know some DL from my Udacity robotics nanodegree).
Your points are spot on. I do have a dog. And a cat. Fur creates a mess everywhere. I cleaned the front panel mesh today itself!
I’m rebuilding my PC. Planning to get the Thermaltake View 71. Sides are semi open, hehe.

Can’t really leave the case open because my cat loves my room for some reason and is always looking for places to snuggle into 
I’m thinking of the new i7 8700K, 16GB RAM, TT View 71 case, Kraken X62 cooler (later) , GTX 1080ti. Will add another GPU later.
I want to deep dive into DL. Goal is to create the StarCraft AI bot and deep reinforcement models for humanoid robot gait+ balance. And of course, vision applications: 3D camera navigation.
Check the Antec Nine-Hundred series (V1, V2 or V3).
Maybe not as sexy with all the bling-bling multi-color leds on fans and the super-slick glass panels of the Thermaltake View 71.
That Antec serie is light on cosmetics and heavy on specs, very serious air-flow potential (I owned two of these when I was multi-boxing on WoW, never failed for 5 years+).
Yeah, PCIe lane speed is clearly not the most critical factor for a lot of ML workloads. Again, I can’t find a lot of hard evidence online that it matters that much. For example, see this server
It includes 10 GTX 1080 Ti cards in one chassis. While it’s dual CPU, there’s no way it can provide enough PCIe 3.0 x16 lanes for all those cards!
But this graph shows that it still gets a linear speed up on performance:
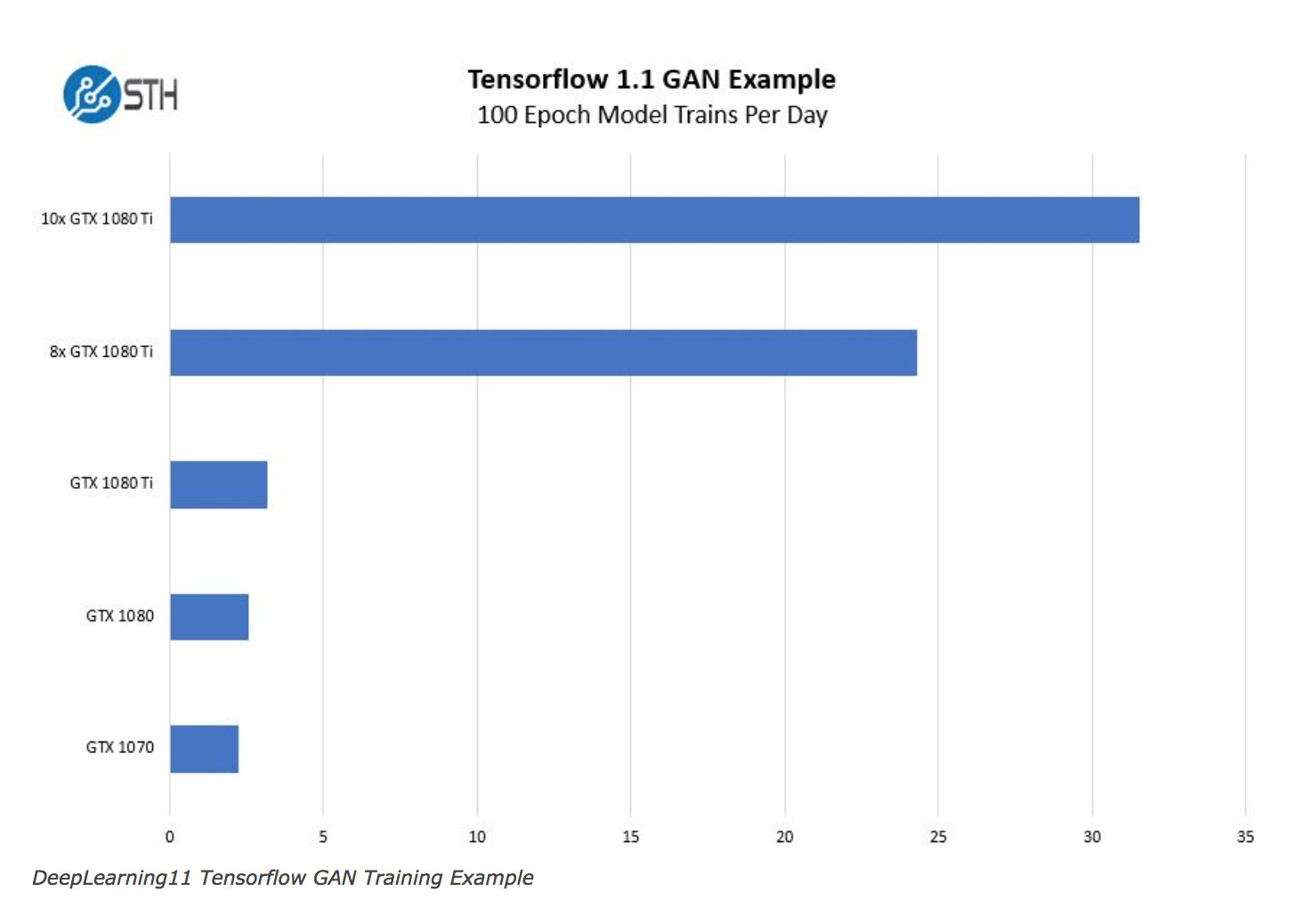
Most of the benchmarks around slots are around gaming, which is a very different workload.
I remember there was a post here that showed that with a convolutional workload, there’s no way that it could saturate the bus (or even a 1x PCIe slot). The bottleneck is in the computation and the memory bandwidth on the GPU card itself (ie. transferring data within the card, and not even going to the CPU’s memory).
I bought an AMD Ryzen Threadripper 1900X mainly because it supports up to 64PCIe lanes. But in hindsight I don’t think it matters all that much.
When using the AWS P2.xlarge instances the bottlenecks I see all the time when I run htop and watch -n 0.5 nvidia-smi are to do wit GPU utilisation, GPU total RAM capacity, single-threaded CPU utilisation while preprocessing data, and CPU RAM loading my training data into memory (get as much as you can).
I bought 2 GTX 1080Ti cards. Not because I think I’ll need to run both of them in parallel, but for better iteration. Ie. when I’m training and testing on one GPU, I can run another variation on another GPU.
I think time to iteration is more important in general. At least for Kaggle competitions.
And for this GPU RAM bandwidth, GPU speed (try to get the best architecture you can afford - eg. currently Pascal), GPU RAM capacity (so you can fit bigger models in memory - I’m constantly reducing model size and batch size to avoid annoying memory capacity issues). And CPU system RAM. I’d recommend at LEAST 32GB if you can depending on your datasets. I’m personally starting with 64GB as I’ve regularly had 50+GB datasets loaded in memory on AWS.
I don’t think PCIe lane speed is a big issue in practice. As long as we’re talking about version 3.0 PCIe.
Each generation of PCIe is 2x the bandwidth of the previous generation. So a x8 3.0 is as fast as a 16x 2.0 I believe. So it’s possible that some of the information out there about PCIe speed is referring to older PCIe versions.
But for most motherboards made in the last 2-3 years you could be OK.
Does anyone have some more hard data on the PCIe issue?
The funny thing is, I can’t even BUY a motherboard that supports the full 64 PCIe lanes of the Threadripper processor! I thought I’d be “futureproofing” my build. But I doubt it. I did buy a full-tower case and a 1500W power supply to support up to 4 GPUs in the future.
Though I think there’s a better than even chance that we won’t be using GPUs in the future anyway.
Look at Google’s TPU and Intel’s Nervana.
I think it’s likely we’ll be running dedicated ASIC hardware in the future which will be faster, higher density and lower power.
If anyone’s interesting, I highly recommend reading Google’s paper on the Tensor Processing Unit - It’s a very interesting insight into the kind of machine learning workloads that occur at scale in production.
I thought this table was very illuminating:

Ie. Only 5% of their models uses CNNs. 61% Multi-Layer-Perceptrons (ie. Dense Layer models). And 29% LSTMs.
Can anyone else comment on the PCIe issue in practice?
7 Likes
Made a blog post about my deep learning server box! Check it out!
5 Likes
Hi,
I am a cs masters student interested in DL/RL, I have decided to build a DL rig at a price point of about 1000 dollars. Here are the components I’ve come up with.
https://pcpartpicker.com/list/8McNr7
Can you please review it. ? Will it be possible to add an additional gpu to this later? I dont mind running two cards in 8 lanes each if the bottleneck is not too big.
Thanks
1 Like
2 points:
Is there a reason you don’t have a CPU cooler picked? The chip itself doesn’t appear to come with a stock cooler.
I’d be careful of wattage if adding a second GPU. You’ve accounted for 550W, and adding a second GPU would take you to an estimated 509W. Theoretically fine, but in the event of a power spike, could run a potential risk.
Happy PC building!
1 Like
hey,
thanks for the reply.
- Ryzen 5 1600 comes with a stock cooler(AMD wraith or something)
- You are right. Will 650W PSU be decent?
P2 has K80 GPUs that have more memory…
But I agree on 1070 - I use it for making homeworks.
1 Like
Although it supports up to 4 GPUs, the critical factor is number of PCI lanes - many CPUs have only 28, and this will limit performance
1 Like
Dear Jeremy
Where can I buy GTX 1070 for $300? It’s about $450 on Amazon.
Also I am wondering if AMD A12 can be a bottleneck for the GTX 1070?
Thanks,
Arash
Yes, I think that would be sufficient