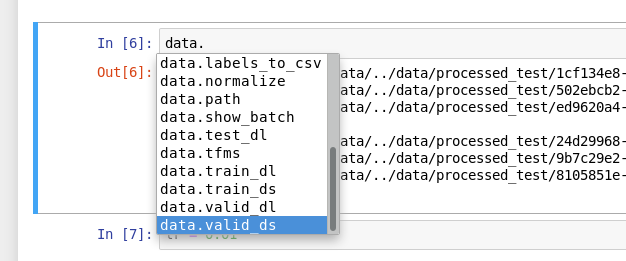
I am unable to make predictions with my test data, always cuda out of memory, independent of batch size.
The progress bar arrives to the end, so 100% of my test data passes the model, but when the output is computed, error.
I don’t have problems with the valid set.
out = learn.get_preds(is_test=True)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-132-588810aa18f3> in <module>
----> 1 out = learn.get_preds(is_test=True)
~/fastai/fastai/basic_train.py in get_preds(self, is_test)
175 def get_preds(self, is_test:bool=False) -> List[Tensor]:
176 "Return predictions and targets on the valid or test set, depending on `is_test`."
--> 177 return get_preds(self.model, self.data.holdout(is_test), cb_handler=CallbackHandler(self.callbacks))
178
179 @dataclass
~/fastai/fastai/basic_train.py in get_preds(model, dl, pbar, cb_handler)
36 def get_preds(model:Model, dl:DataLoader, pbar:Optional[PBar]=None, cb_handler:Optional[CallbackHandler]=None) -> List[Tensor]:
37 "Predict the output of the elements in the dataloader."
---> 38 return [torch.cat(o).cpu() for o in zip(*validate(model, dl, pbar=pbar, cb_handler=cb_handler, average=False))]
39
40 def validate(model:Model, dl:DataLoader, loss_fn:OptLossFunc=None,
~/fastai/fastai/basic_train.py in validate(model, dl, loss_fn, metrics, cb_handler, pbar, average)
47 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None)):
48 if cb_handler: xb, yb = cb_handler.on_batch_begin(xb, yb, train=False)
---> 49 val_metrics.append(loss_batch(model, xb, yb, loss_fn, cb_handler=cb_handler, metrics=metrics))
50 if not is_listy(yb): yb = [yb]
51 nums.append(yb[0].shape[0])
~/fastai/fastai/basic_train.py in loss_batch(model, xb, yb, loss_fn, opt, cb_handler, metrics)
17 if not is_listy(xb): xb = [xb]
18 if not is_listy(yb): yb = [yb]
---> 19 out = model(*xb)
20 out = cb_handler.on_loss_begin(out)
21
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
--> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
---> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
--> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/conv.py in forward(self, input, output_size)
724 return F.conv_transpose2d(
725 input, self.weight, self.bias, self.stride, self.padding,
--> 726 output_padding, self.groups, self.dilation)
727
728
RuntimeError: CUDA error: out of memory
It is probably how I created my test ds, the SegmentationDataset expects x and y values, so i just called the constructor with (x,x) as I don’t have y values for test data.
Then used:
def get_tfm_datasets(path, val_idxs, size):
datasets = get_datasets(path, val_idxs)
tfms = get_transforms(do_flip=True, max_rotate=4, max_lighting=0.2, max_warp=0.15)
return transform_datasets(train_ds, valid_ds, test_ds=test_ds, tfms=tfms, tfm_y=True, size=size, padding_mode='border')
train_tds, _, _= get_tfm_datasets(PATH128, range(400), 128)
to get trasnformed datasets.
Any idea?