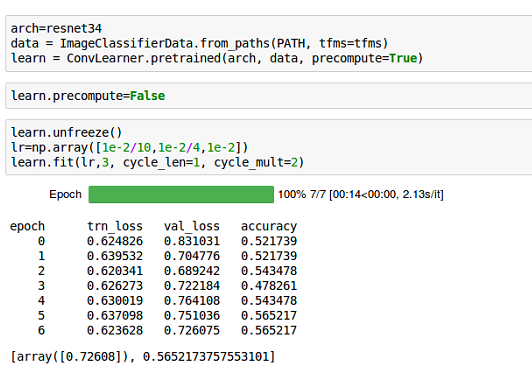
Hello! I am new in deep learning and just came across fastai courses that are really helpful. I hope I am at right place to ask some basic question. I am trying to classify the mammograms ( two-class classification of Normal and Abnormal mammograms). I have 113 images in each class that I split into 70/30 % for training and validation. The original image size was 1024×1024 that I resized to 256×256. I am using lesson 1 code of pre-trained resnet34. However, my accuracy is very low only 56%. I tried different learning rate from very small to very large, fine-tuning and data augmentation, decreasing batch size (as mentioned in lesson 1 and from forum discussions)but accuracy didn’t increase. I thought that its due to the limited data set issue so I used the brain tumor data for two-class classification( High-grade and low-grade glioma) with 3500 images in each class and split into 70/30% for training and validation. But accuracy is again very low for this dataset as well (57% only).
I tested the same code of lesson 1 on natural images for two-class classification with fewer images and got reasonable accuracy, but for medical images it’s not working well.
I would try higher learning rates for the earlier layers, since mammograms are nothing like the things the resnet network has been trained on. maybe try something like [1e-2 / 9, 1e-2 / 3, 1e-2] oder something similar.
Please keep us updated… I’ll start with my radiology residency in 4 months and I’m very interested in this stuff
Hi,
aug_tfms accepts a list of transformations. These start all with Random~. So in a jupyter notebook use Random + tab. But I don’t think that’s the main problem.
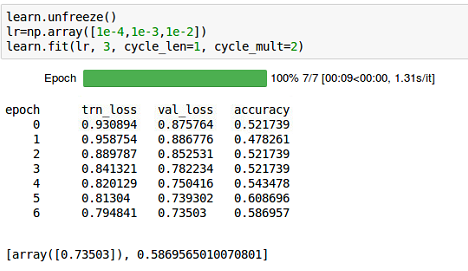
During training, the validation score is much more important. If you look at it, it’s still going down and your still underfitting. So I would say:
train longer, adapt the learning rate and experiment a bit. (Your training loss should be at least 0.05 lower than val_loss)
The most important thing is to find out if your model is able to overfit. Then you can start thinking about more data augmentation, different models, image sizes…
I dont have the code in front of me but I think some of the transforms affect the color. color = subtracting the mean of the color and dividing by standard deviation. might be interesting to see if those transforms are being applied and if so how they look after they are applied.
Thank @rasmus1610 for reply. Actually, I have tried different combinations of differential learning rates (also the one u have suggested) but there is no improvement in accuracy.
yes sure, I am a beginner in deep learning for medical Image classification and segmentation and will keep on adding stuff if I am going to get some good results for medical data
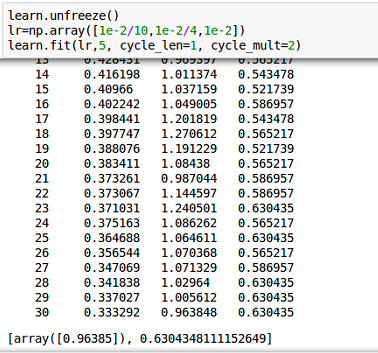
yes before applying transformations (keeping precompute=True) I still tried to find out the best combination of differential learning rates, but accuracy is still low. with longer training model starts to overfit with validation loss going up and training loss going down
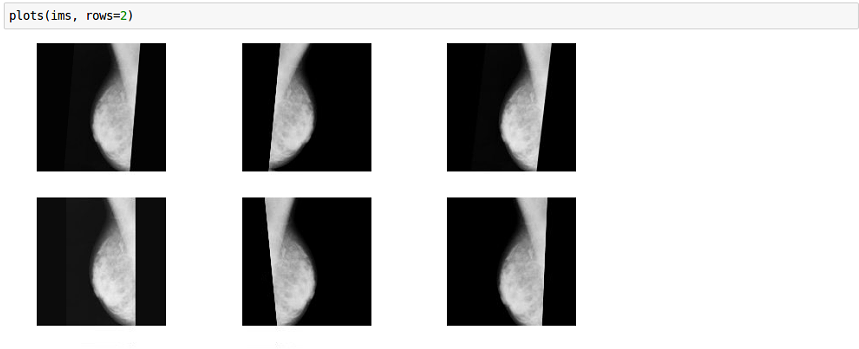
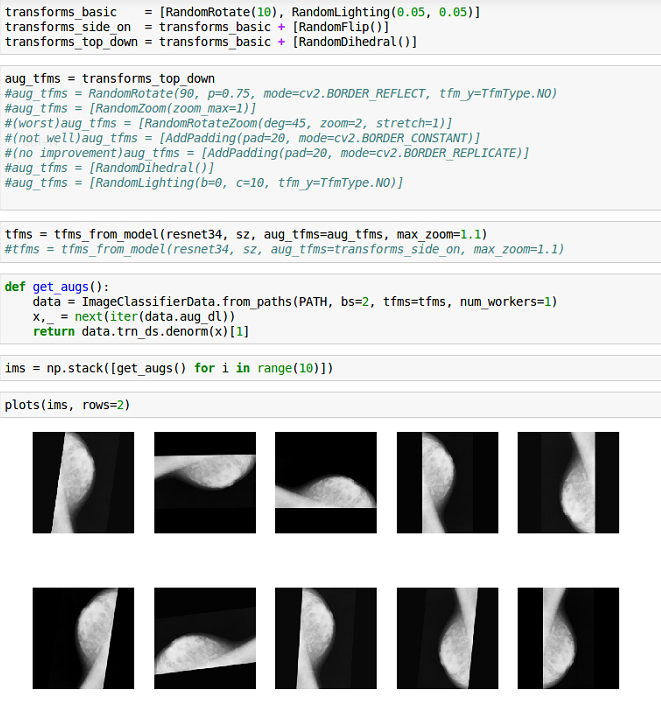
After struggling a lot with learning rate I moved to apply the data augmentation, now the code with transformations being applied looks like this
I am mainly focusing on improving accuracy using fine tuning and differential learning rates, as from Jeremy’s first lesson medical data have different kinds of features altogether (compare to ImageNet images), so we have to re-train many layers.
Are color transformations applicable to grayscale images such as medical data? If they are, I will definitely try to apply them once I get some reasonable accuracy without transformations and then compare how these transformations help to improve the results
Normally in image augmentation, you are leveraging your outside knowledge of the system (in this case, mammograms) in order to produce images for training.
Your augmentations are producing completely unrealistic images – there are no mammograms in the dataset where the breast points up, I’d imagine. I would pay more attention to smaller perturbations (e.g. translations or small rotations) and abandon flipping them completely.
Thank you @zearo I will keep this thing in my mind while augmenting data. That’s probably the reason that data augmentation has negative effect on results!