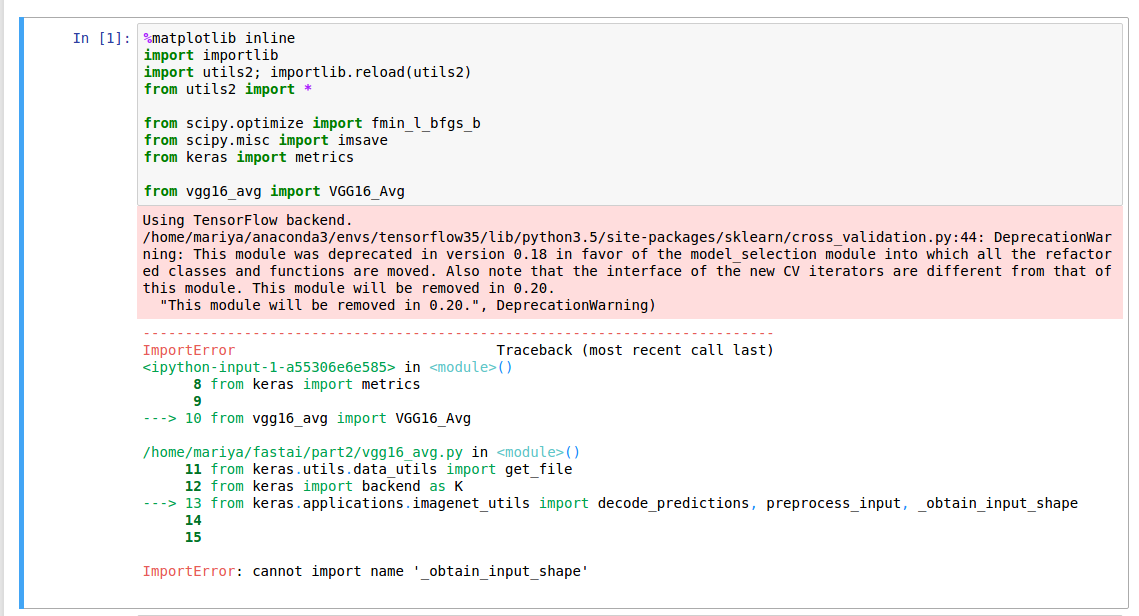
This post is editable by all of you! Please edit it to add any useful information for this weeks class, including links brought up during class, other helpful readings, useful code/shell snippets etc. Also, please help organize this wiki post by putting things in sections, adding/editing prose, etc.
NB: Discourse does not allow multiple edits at the same time - if two people save, most recent wins. So copy your edits before saving, just in case!
Lesson 8 Wiki
Class links
- Lesson 8 video
- Lesson 8 video timeline
- Lesson 8 discussion
- Lesson 8 assignments
- Lesson 8 notebooks & files
Papers
[A Neural Algorithm of Artistic Style] (https://arxiv.org/abs/1508.06576v2)
- Original artistic style paper
- 26 Aug 2015
- Handy summary of the paper; NB many other paper summaries also available at that repo
What problem are they solving?
Generate an image that has the content of one image and the style of another. “Style” here means colors and textures.
What is the general idea that they are using to solve it?
Use a pre-trained CNN to extract the content of one image and the style of the other. Combine the content with the style.
A step-by-step explanation:
- Choose a CNN pre-trained for image classification (e.g. VGG trained on ImageNet).
- Generate a random input image.
- Choose a measure and measure the difference between the input image’s CNN activations and the content image’s CNN activations (e.g. MSE).
- Choose another measure and measure the difference between the input image’s CNN activations and the style image’s CNN activations (e.g. MSE of the Gram matrices).
- Choose a way to combine the differences and combine them (e.g. a weighted sum).
- Minimize the combination by changing the pixels of the input image (which will then change the CNN activations, the differences, and finally the combination).
- Repeat using the modified input image until it looks good or doesn’t change.
The CNN activations can come from multiple convolutional layers.
What kind of results are they getting?

What previous work are they building on?
-
Deep convolutional neural networks for image classification
-
Non-photorealistic rendering, particularly texture transfer.
Cool examples of neural style
Links mentioned during class
- Jeremy’s liked tweets - over a thousand deep learning papers and articles recommended by Jeremy, and a great place to find interesting DL researchers to follow
- http://www.arxiv-sanity.com/ - great way to find similar papers to what you’re interested in, and get recommendations. Be sure to login, and save papers that we’re working on
- http://www.mendeley.com/ - Jeremy’s recommended app for reading, organizing, and annotating papers
- https://www.reddit.com/r/MachineLearning/ - good source of deep learning news
- Tensorflow Dev Summit Videos
- Import AI newsletter - deep learning news
- WildML news - another deep learning newsletter
Code snippets
- To get all files for the lesson (h/t @ibarinov):
wget -r -nH -nd -np -R index.html* http://files.fast.ai/part2/lesson8/
(files out-of-date)
Steps needed for Style Transfer using VGG:
Content extraction
- Read the cont_image
- Resize cont_image
- Preprocess : RGB ->BGR and normalize
- Create VGG_avg
- Generate P(l) = activations for the cont_image at layer l
- Generate F(l) = activations for white noise image at layer l
- content_loss = MSE(P(l), F(l))
Style extraction
- Read the style_image
- Resize style_image
- Preprocess : RGB ->BGR and normalize
- Create VGG_avg
- Generate Gram_matrix for original image, A(L) = Inner product of F * Ft for the layers L, where F is the vectorized feature map. (There is some weight to the loss for each layer?)
- Generate Gram_matrix for white noise image, G(L) similarly above
- style_loss = MSE(A(L), G(L))
Style transfer
- loss(c,s,x) = a * content_loss(c, x) + b * style_loss(s, x), where c = content image, s = style image, x = generated image
- Use scipy’s implementation of L-BFGS to find the values of “x” that minimize the loss (fmin_l_bfgs_b(loss, x0=x, args=(c, s))). In our case, “x” happens to be image pixels, and thus we end up searching for the image that is close to both the content image © and the style image (s).
An Introduction to Tensorflow
The software library is called TensorFlow and the central unit of data in TensorFlow is known as tensor. Tensors are values shaped in the form of arrays varying from zero to any number of dimensions. When you hear a “Rank” of a tensor it refers to the number of dimensions of the tensor array.
Example:
3 # A Rank 0 tensor
[1, 2, 3] # A rank 1 tensor
[[1, 2, 3]] # A rank 2 tensor
TensorFlow Dev Summit 2017 notes
Keynote
- History:
- DistBelief in 2012
- Scalable and worked well in production
- But not flexible
- Designed for CPUs, GPUs were bolted on
- Worked for simple models but sequence models and reinforcement learning problems were hard to express
- TensorFlow
- Supports many platforms
- CPU, GPU, Android, iOS, Raspberry Pi, ASICs (e.g. TPU)
- Supports cloud platforms and virtual machines
- Supports many languages
- Visualization and monitoring tools
- TensorBoard
- Supports many platforms
- Progress to date
- Nov '15 (v0.5): Launched
- Dec '15 (v0.6): Faster on GPUs; Python 3.3+
- Feb '16 (v0.7): TF Serving
- Apr '16 (v0.8): Distributed TensorFlow
- Jun '16 (v0.9): iOS; Mac GPU
- Aug '16 (v0.10): TF Slim
- Oct '16 (v0.11): HDFS; CUDA 8; CuDNN 5
- Nov '16 (v0.12): Windows 7, 10, and Server 2016; TensorBoard Embedding Visualizer
- Feb '17 (v1.0): XLA (accl. linear algebra), TF debugger; pip package; better API; stable API
- DistBelief in 2012
- Applications:
- Word lens (augmented reality; translating text in images to other languages)
- Spam detection
- Smart reply (“Are you free tomorrow?”–> “Yeah, what’s up?”)
- Cucumber sorter
- Dermatologist-level classification of skin cancer
- Ophthalmologist-level detection of diabetic retinopathy
XLA
- Just-in-time (JIT) compiler for TF
- Better on GPUs, worse on CPUs (for now)
- Ahead-of-time (AOT) compiler for TF
- Smaller binaries on mobile (600KB instead of 2.6MB)
- Makes models faster
- Makes models smaller
- Experimental
TensorBoard
-
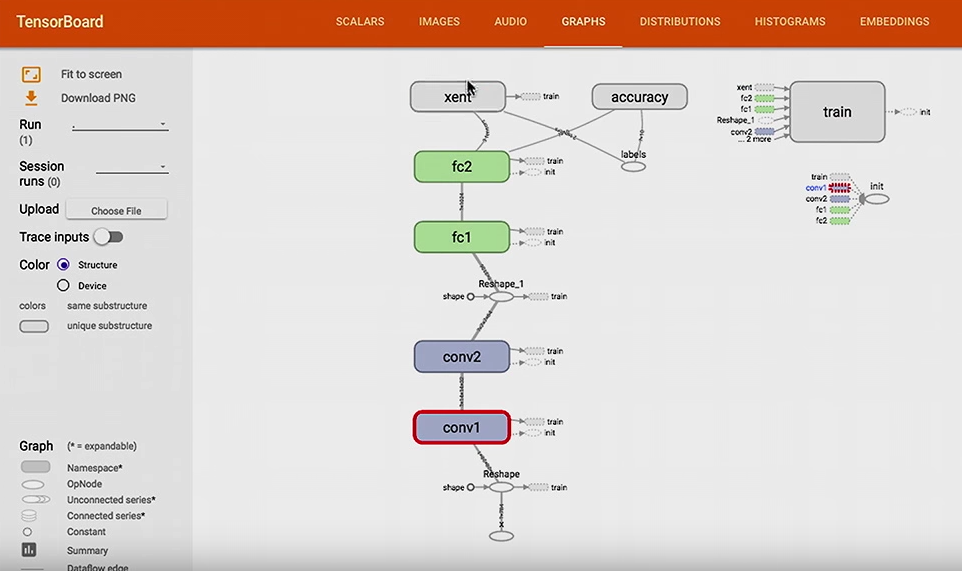
Visualizing the computation graph
- tf.summary.FileWriter
- A Python class that writes data for TensorBoard
- Code example
- tf.summary.FileWriter
writer = tf.summary.FileWriter("tmp/mnist_demo/1")
writer.add_graph(sess.graph)
$ tensorboard --logdir /tmp/mnist_demo/1
- Summaries
- tf.summary.scalar
- tf.summary.image
- tf.summary.audio
- tf.summary.histogram
- Code example
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter("tmp/mnist_demo/3")
writer.add_graph(sess.graph)
for i in range(2001):
batch = mnist.train.next_batch(100)
feed_dict = {x: batch[0], y: batch[1]}
if i % 5:
s = sess.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, i)
sess.run(train_step, feed_dict=feed_dict)
$ tensorboard --logdir /tmp/mnist_demo/3
- Hyperparameter search
- Parent directory
- Child directory for each hyperparameter
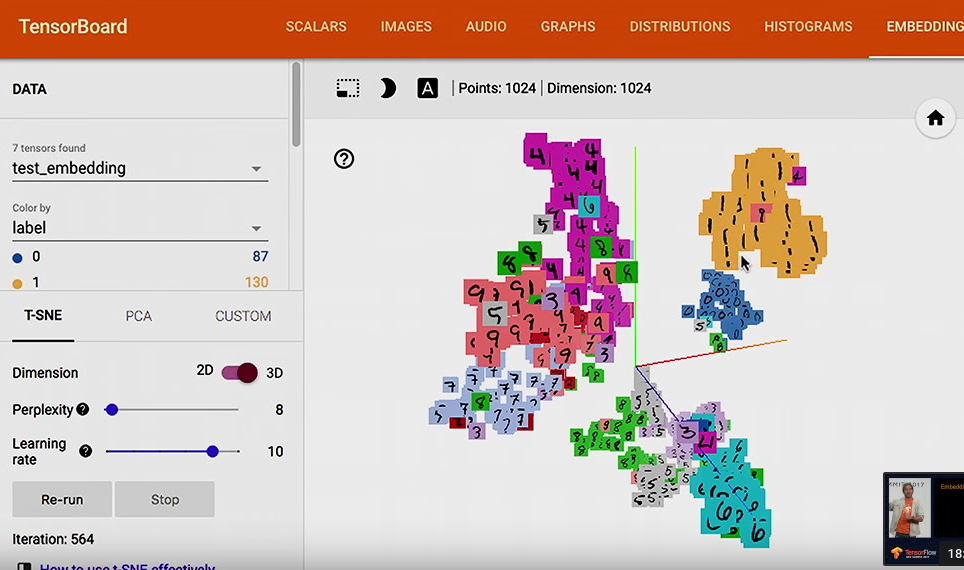
- Embedding visualizer
High-Level API
- Layers: Layer-oriented API (like Keras)
- tf.layers
- An API that maps to architecture descriptions
- Compatible with Keras
- Estimator
- model_fn
- API:
- train_op: fit()
- eval_op: evaluate()
- predictions: predict()
- export_savedmodel()
- For TensorFlow Serving
- Canned Estimators
Integrating Keras & TensorFlow
- Keras: An API for building deep learning models
- Integrating with TensorFlow means:
- New features with the Keras API:
- Distributed learned
- Cloud ML
- Hyperparameter tuning
- TF Serving
- New features with the Keras API:
- Take-aways slide:
- For TF users: an accessible high-level API with good defaults
- For Keras users: powerful TF features for your Keras models
- tf.contrib.keras by TF 1.1 (mid-March 2017)
- tf.keras by TF 1.2
- A big step in making TensorFlow and deep learning accessible to as many people as possible.
TensorFlow at DeepMind
- DeepMind moved to TensorFlow
- Data center cooling
- AlphaGo
- WaveNet
- Natural-sounding speech
- Music generation (nonvocal)
- Learning to learn by gradient descent by gradient descent
- Trained a neural network to train a neural network
Skin Cancer Image Classification
- Stanford
- AI lab + medical school
- Skin cancer
- Most common cancer in the US
- 1 in 5 Americans will develop skin cancer
- Estimate for 2017: 87k new cases of melanoma and 9.7k deaths from it.
- Survival rate for melanoma is 98% if detected early
- Estimate for 2020: 6.1 billion smartphones in circulation
- “If your program can differentiate between hundreds of dog breeds, I believe it could make a great contribution to dermatology.” - Dr. Rob Novoa, Jan 27, 2015, to the Stanford AI lab
- Dataset:
- 129k images, 2k diseases
- Base classes: 2k
- Superclasses: Benign, ambiguous, dangerous, deadly
- Training:
- “We find that training on finer classes results in better performance.”
- If they want less-fine classification, they sum the probabilities of the constituent classes.
- Transfer learning with Inception-V3 (V3 worked better than V1)
- Evaluation:
- Sensitivity: True position / positive
- Specificity: True negative / negative
- Confusion matrices
Mobile and Embedded TensorFlow
- A low-level talk
- Offering unique user experiences
- Real-time translations (e.g. Word Lens)
- Predicting next words on keyboards
- Scanning old photos
- Detecting diseases real-time
- Working closely with hardware builders
- ARM, CEVA, Movidius, IBM, Intel, Qualcomm
- TF support for:
- Android, iOS, Raspberry Pi
- Tutorials for getting started with TF + Android/iOS/RaspberryPi
- TF + Android examples
- TF Classify
- TF Detect
- TF Stylize
- Managing binary size
Distributed TensorFlow
- Data parallelism
- Model paralellism
- Very large models (wide and deep)
- Outrageously large models
- Core concepts of distributed TF:
- Replicating your model
- Device placement for Variables
- Sessions and Servers
- Fault tolerance
TensorFlow Ecosystem: Integrating TensorFlow with Your Infrastructure
- Data preparation, training, and serving.
- Data prep
- Import from various sources
- Proprocess the data
- Export in a file format that TF supports (e.g. TFRecords)
- Data prep tools
- Apache Spark, Hadoop MapReduce, Beam
- Training
- Local vs. Distributed
- Distributed training tools (cluster managers)
- Kubernetes, Apache hadoop, Mesos, Slurm
- Distributed storage tools
- Hadoop HDF5, Google Cloud Storage, AWS
- Container engines:
- Docker, Rkt
- Distributed training concepts:
- Parameter servers
- Workers
- TensorBoard is compatible with distributed training
- Be careful with your choice of file formats (for data and for models)
- Serving models has nuances; TF Serving handles them:
- Loading a new version of a model
- Batching inputs efficiently
- Isolation between multiple models (by default they contend for hardware resources)
- When to use in-process TF over TF Serving?:
- Mobile
- Batch inference
- Very strict latency requirements (TF Serving involves round-trip RPCs)
- Run one fewer service
Serving Models in Production with TensorFlow Serving
- History of software:
- 2005: No source control
- 2010: Source control & continuous build, but not for ML
- 2017: Great tools for ML but still have a way to go
- “Just because we have a best practice, doesn’t mean that everyone uses it yet.”
- Goal: Develop best practices for ML, and make them the default configuration for ML tools
- “Serving”: How you use your ML model after you’ve trained it
- Continually training models and continually deploying them
- TF Serving: A flexible, high-performance serving system for machine learned models, designed for production environments
ML Toolkit
- Tools
- Linear / logistic regression
- Clustering
- KMeans clustering
- Gaussian mixture model (GMM)
- WALS matrix factorization
- Support vector machine (SVM)
- Stochastic dual coordinate ascent (SDCA)
- Random forest
- DNN, RNN, LSTM, Wide & Deep, …
- Properties (of the implementations of the tools):
- Usable
- scikit-learn-inspired Estimator APIs
- Extensible
- Combining the tools in novel ways?
- Chaining a DNN after KMeans?
- Scalable
- Distributed implementations of the tools
- Fast
- Usable
Sequence Models and the RNN API
- Case study: Google Translate
- Sequence to sequence
- Encoder and decoder
- Encode from source language to vector
- Decode from vector to target language
- Topics
- Reading sequence data
- Goal: Pad, but minimize the amount of padding needed
- Approach 1: Static padding
- Need to know the maximum length ahead of time
- Wastes time
- Wastes space
- Approach 2: Dynamic padding
- Max sequence in the batch sets the sequence length
- This is still pretty close to static padding in terms of waste
- Approach 3: Bucketing
- When reading a sequence, place it into the shortest bucket it can fit into
- Approach 4: Truncated BTT via State Saver
- ?
- Approach 1: Static padding
- Goal: Pad, but minimize the amount of padding needed
- The RNN API
- A library of RNN architectures
- A flexible API for implementing your own RNN architectures
- Fully dynamic calculation
- Fast and memory efficient custom loops
- Goal: Handle sequences of unknown length
- Fused RNN cells (flexibility vs. efficiency)
- Optimization for special cases
- XLA fused time steps (use on GPUs, not CPUs; no speedup on embedded devices, but makes the models smaller)
- Recommendation: Try XLA and benchmark your intended use case
- Dynamic decoding
- Reading sequence data
Wide & Deep Learning: Memorization + Generalization with TensorFlow
- Wide: Memorization: “Seagulls can fly.” and “Pigeons can fly.”
- Deep: Generalization: “Animals with wings can fly.”
- Wide & Deep: Generalization + memorizing exceptions: “Animals with wings can fly, but penguins cannot fly.”
- Wide & Deep tutorials available; The Wide & Deep Project
Magenta: Music and Art Generation
- Can ML generate compelling media?
- Compelling media
- Music
- Images and video
- Text
- Jokes
- Stories
- Compelling media
- Interface for creative coders and artists
- pip install magenta
- The importance of critical feedback
- Musicians and listeners
- Music and art co-evolve with technology
- Turning technologies into artistic instruments
- Using them in novel, unintended ways
- “Breaking” them
- Merging them
- Turning technologies into artistic instruments
- Examples:
- Image inpainting
- Music generation (similar to image inpainting)
- Artistic style transfer
- “If you’re not using TensorBoard, you want to be using TensorBoard.”
- magenta.tensorflow.org
Case Study: TensorFlow in Medicine - Retinal Imaging
- Diabetic retinopathy: fastest growing cause of blindness
- 415M people with diabetes, each at risk of going blind
- Regular screening is key to preventing blindness (e.g. once a year)
- The doctor takes a picture of the back of the eye with a special camera, and then looks at the picture
- Shortage of eye doctors to do this task
- Doctors are inconsistent with each other
- Dataset: 30k images, 880k diagnoses (labels)
- Hired an army of doctors to label the images (54 doctors)
- F-score of model: 0.95; Median F-score of doctors: 0.91
- How did TF help?
- Quick prototyping
- Starter architectures
- Pre-trained models
- Experiment at scale
- GPU support
- Fast training
- The above helped them focus on their other problems:
- Finding the right problem
- Getting the data & labels
- Validating & deploying
- Quick prototyping
- Next steps:
- Validation of the model by hospitals
- Custom hardware to take the images and run the models
- Low-cost and easy to use hardware