Thanks Romano, makes perfect sense now.
removing the rescaling worked. Thanks
- Why is np.array([123.68, 116.779, 103.939], dtype=np.float32) and not float64?
- What is the point of style_wgts= [0.05,0.2,0.2,0.25,0.3]. Why pick those numbers?
- Why do you add content loss and style loss together. Isn’t the entire point to do the MSE of the difference between the layer weights and the predicted weights? I don’t understand why you add the content and style loss?
-
If I recall correctly, I was getting some type mismatch errors and I needed to cast some variable types.
-
Arbitrary. You can play with those, as well as you can play with the style2content ratio.
-
Yes, but as you run the virgin image through the network you have two of those differences, one for the content and one for the style which you then add (with different weights) together.
In general, I believe those questions (plus many others that you may have) were answered in Jeremy’s video lecture, which I recommend you take.
1 Like
I saw it once. Maybe it didn’t sink in because I wasn’t inside the code. I’ll re-watch it again. Thanks.
Hi All, I am having a problem with the neural-style.ipynb. When I get to the part where the noise image pixels are trained with solve_image(), I don’t get back 10 current loss values as in the example, but rather I get this:
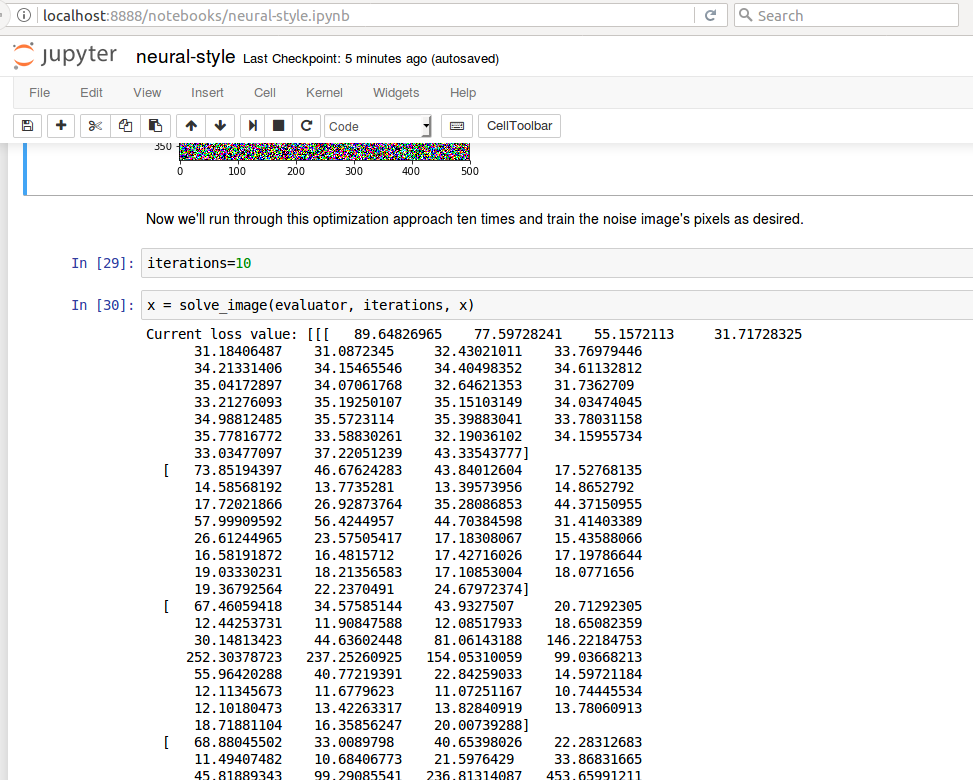
It is a very large matrix! The resulting images are plain orange blank fields. Has anyone else run into this? I am using Keras 2.0 - I have had to change a few minor things because of this version, and I’m not sure if this is related to the upgraded version.
Thanks, Christina
1 Like
Okay, I found the answer in the other thread (Lesson 8 homework assignments). Simply replace
loss = metrics.mse(layer,targ)
with
loss = K.mean(metrics.mse(layer, targ))
That will return a single mean value instead of the whole matrix. 
6 Likes
Thanks @rteja1113 & @RiB, both
def style_loss(x, targ): return K.sum(metrics.mse(gram_matrix(x), gram_matrix(targ)))
and
def style_loss(x, targ): return K.mean(metrics.mse(gram_matrix(x), gram_matrix(targ)))
work, but using the one with K.mean results in lower losses – but I can’t tell the difference in the resulting image.
Yes, they should both work as they are one the scaled version of the other. However, we had noticed that in some cases scaling (either directly through K.mean or by manual quotient with height, width and channels) was conflicting with gradient initialization. Given what I have seen, I would not be surprised to learn that K.mean fails to converge for large images.
Just started Part 2, thanks again for the amazing work. After 30 minutes of Googling and StackOverflowing I’m stuck trying to understand this class.
Can you please explain how the initializers work? Or point me to a reference?
class Evaluator(object):
def __init__(self, f, shp): self.f, self.shp = f, shp
def loss(self, x):
loss_, self.grad_values = self.f([x.reshape(self.shp)])
return loss_.astype(np.float64)
def grads(self, x): return self.grad_values.flatten().astype(np.float64)@kevindewalt The l_bfgs function excepts 2 separate values; loss and gradients. The evaluator class is just separating those values.
A question on how we calculate the style loss. I suspect the source of my confusion is my unfamiliarity with how tensorflow works.
Recreate input
The loss function just uses layer outputs,
loss = metrics.mse(layer, targ)
Recreate style
Loss function passes something different to gram_matrix.
loss=sum(style_loss(l1[0], l2[0]) for l1,l2 in zip(layers, targs))
My question: why do we pass l1[0] and l2[0] to style loss instead of l1 and l2?
I created
for l1,l2 in zip(layers, targs):
print(l1[0].shape)
l1[0]
which produces
(397, 595, 64)
(198, 297, 128)
<tf.Tensor 'strided_slice_56:0' shape=(198, 297, 128) dtype=float32>
I did some reading on tensorflow and couldn’t find anything about a “strided_slice” which provides any hints.
Hi all,
I have a question about the use of
K.function([model.input], [loss] + grads).
The inputs of loss and grads are different; whereas grads can directly take the input of model.input, loss is created from layer, which is not the same variable as model.input. How does the Keras function know the difference?
Thank you!
1 Like
Confuse with the codes of lesson8, I am not sure what are they doing.
Following are my questions and guess
model = vgg16_avg.VGG16_Avg(include_top=False)
layer = model.get_layer('block4_conv1').output
# The layer_model output the activation of the input
layer_model = Model(model.input, layer)
# pre-calculate the output of the "block_conv1", put them into K.variable
# because predict output a numpy array but not a Tensor
targ = K.variable(layer_model.predict(img_arr))
# mse will compute the loss between output of the layer and targ
# value of targ is precomputed, but what is the purpose of layer?
# It would take the input image and output the activation(same as layer_model?)?
loss = metrics.mse(layer, targ)
grads = K.gradients(loss, model.input)
# We cannot call loss nor grads directly, instead we feed them into K.function
# As gtseng asked, what is happening when we call fn(input_img)?
fn = K.function([model.input], [loss]+grads)
I spend several hours to find the answers by DuckDuckGo, read all of the replies of Lesson8 Discussion, tweak and run the codes many times but still cannot clear the miasma in my head, please lent me a hand if you can, thanks.
bump
Anyone, anyone … Bueller…
@tham Your guesses are basically correct. The purpose of “layer” is to retrieve the output of the intermediate layer. You must distinguish between the layer_model (which is a keras model defined to do the precomputation) and the layer itself (which is just an intermediate tensor which contains the layer which is in turn fed to the Model module to build the layer_model. Therefore, layer does not take anything as input or output, layer_model does.
You do not call the fn directly, you feed such function into a solver, along with the symbolic definition of the function loss and gradient with respect to its input. Once fed into the solver, the input of the function is iteratively modified so as to minimize its loss and gradients.
I hope this helps.
1 Like
Thanks, I think I got it now, These kind of programming paradigm are quite confusing at the first time I meet them, now I gradually get it(I hope). Please correct me if anything wrong
#this line specify the layer_model which can do precomputation and the
#input can feed into the Mode later on
layer_model = Model(model.input, layer)
#this line feed the intermediate tensor, layer into the mse
loss = metrics.mse(layer, targ)
#this line feed the loss function(I guess TensorFlow need it to figure out how to find gradient)
#and model.input into the gradient
grads = K.gradients(loss, model.input)
#this line feed the model.input and loss,grads into the function, because
#we create layer_model before, TensorFlow know how to create a Model
#by model.input and layer. We concatenate loss and grads, because we want
#the function find loss and grads, I guess this function will call loss first,
#then call the grads
fn = K.function([model.input], [loss]+grads)
I think the codes after updated on github are easier to read, less confusing(at least for new comers).
Whatever, lesson 8 and the notebook are awesome, for me the most important part is it show us
how to implement the algorithm write on the paper, teach us how to read papers.
By the way, write a post to record my understanding about the implementation details of lesson 8, I hope I get it right.
The function at the end only tells you that the concatenated list of loss and grads is the output that you want to - eventually - minimize. So, when you feed it to the solver bfgs, it will try to minimize the loss and will stop when the gradients are also zero (a minimum, hopefully not just a local one).
1 Like