Getting an error tonight (12/03/2017 in USA) when trying to run the movelens data. I had performed a git pull and conda env update before running the notebook:
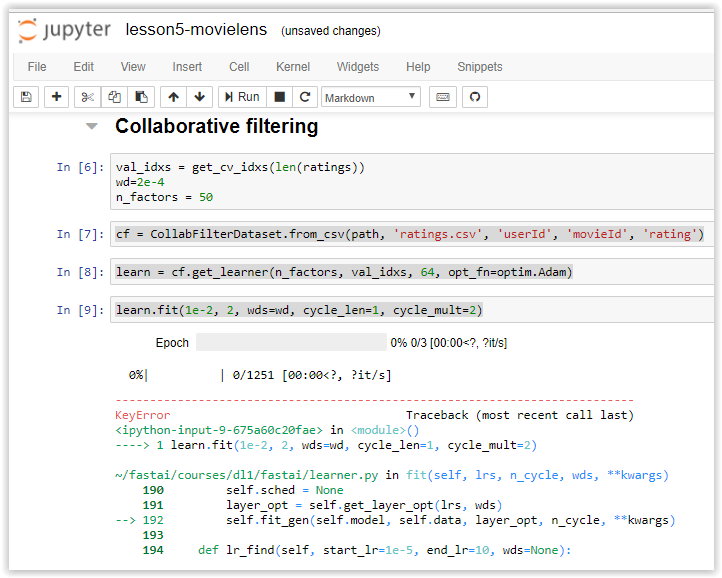
The full trace:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-9-675a60c20fae> in <module>()
----> 1 learn.fit(1e-2, 2, wds=wd, cycle_len=1, cycle_mult=2)
~/fastai/courses/dl1/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
190 self.sched = None
191 layer_opt = self.get_layer_opt(lrs, wds)
--> 192 self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
193
194 def lr_find(self, start_lr=1e-5, end_lr=10, wds=None):
~/fastai/courses/dl1/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, metrics, callbacks, use_wd_sched, **kwargs)
137 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
138 fit(model, data, n_epoch, layer_opt.opt, self.crit,
--> 139 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
140
141 def get_layer_groups(self): return self.models.get_layer_groups()
~/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
80 stepper.reset(True)
81 t = tqdm(iter(data.trn_dl), leave=False, total=len(data.trn_dl))
---> 82 for (*x,y) in t:
83 batch_num += 1
84 for cb in callbacks: cb.on_batch_begin()
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/tqdm/_tqdm.py in __iter__(self)
951 """, fp_write=getattr(self.fp, 'write', sys.stderr.write))
952
--> 953 for obj in iterable:
954 yield obj
955 # Update and possibly print the progressbar.
~/fastai/courses/dl1/fastai/dataloader.py in __iter__(self)
64 def __iter__(self):
65 with ThreadPoolExecutor(max_workers=self.num_workers) as e:
---> 66 for batch in e.map(self.get_batch, iter(self.batch_sampler)):
67 yield get_tensor(batch, self.pin_memory)
68
~/src/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result_iterator()
584 # Careful not to keep a reference to the popped future
585 if timeout is None:
--> 586 yield fs.pop().result()
587 else:
588 yield fs.pop().result(end_time - time.time())
~/src/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
423 raise CancelledError()
424 elif self._state == FINISHED:
--> 425 return self.__get_result()
426
427 self._condition.wait(timeout)
~/src/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
~/src/anaconda3/envs/fastai/lib/python3.6/concurrent/futures/thread.py in run(self)
54
55 try:
---> 56 result = self.fn(*self.args, **self.kwargs)
57 except BaseException as exc:
58 self.future.set_exception(exc)
~/fastai/courses/dl1/fastai/dataloader.py in get_batch(self, indices)
60 def __len__(self): return len(self.batch_sampler)
61
---> 62 def get_batch(self, indices): return self.collate_fn([self.dataset[i] for i in indices])
63
64 def __iter__(self):
~/fastai/courses/dl1/fastai/dataloader.py in <listcomp>(.0)
60 def __len__(self): return len(self.batch_sampler)
61
---> 62 def get_batch(self, indices): return self.collate_fn([self.dataset[i] for i in indices])
63
64 def __iter__(self):
~/fastai/courses/dl1/fastai/column_data.py in __getitem__(self, idx)
11
12 def __len__(self): return len(self.y)
---> 13 def __getitem__(self, idx): return [o[idx] for o in self.xs] + [self.y[idx]]
14
15 @classmethod
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/series.py in __getitem__(self, key)
621 key = com._apply_if_callable(key, self)
622 try:
--> 623 result = self.index.get_value(self, key)
624
625 if not is_scalar(result):
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexes/base.py in get_value(self, series, key)
2555 try:
2556 return self._engine.get_value(s, k,
-> 2557 tz=getattr(series.dtype, 'tz', None))
2558 except KeyError as e1:
2559 if len(self) > 0 and self.inferred_type in ['integer', 'boolean']:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
KeyError: 1230


