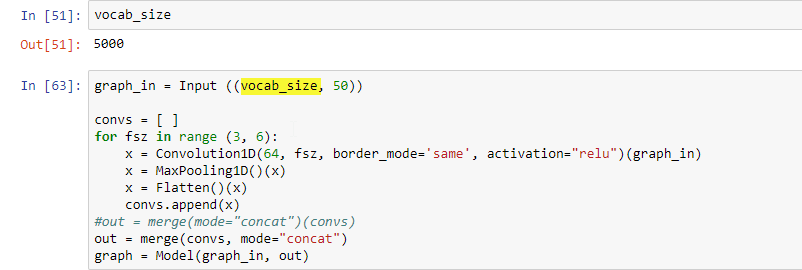
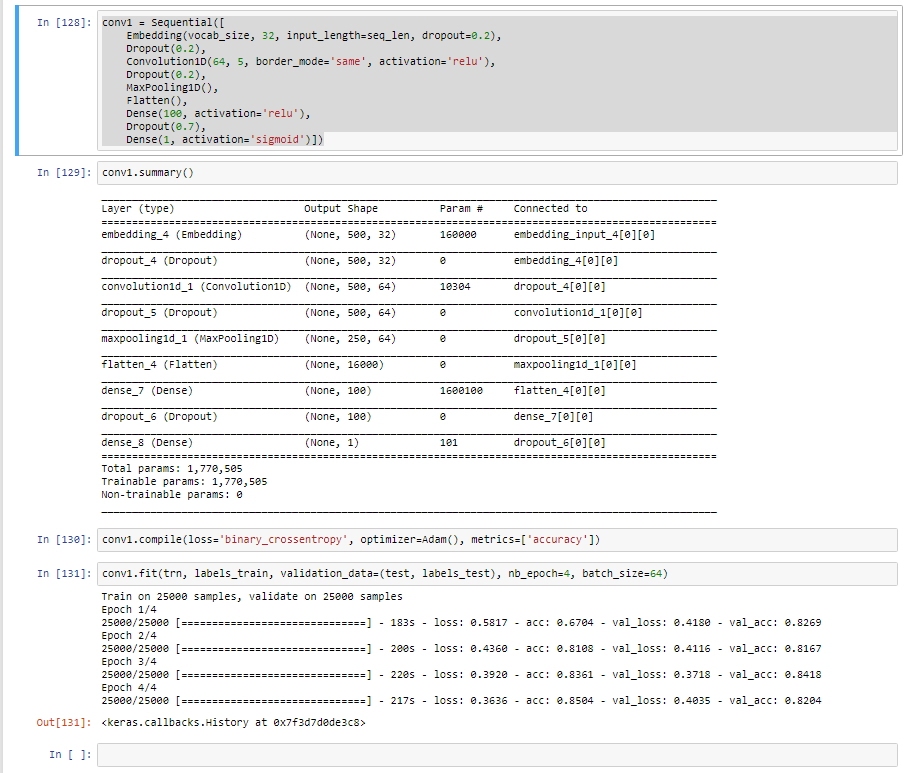
I believe I found a mistake/typo on lesson 5 notebook , in the Multi-size CNN.
When constructing the ‘graph’ model (multi CNN) - its Input layer shape is written as
graph_in = Input ((vocab_size, 50)) where vocab_size is 5000 (when its need to be 500):
I’m having some trouble instantiating the Vgg16BN() class and getting the error:
Unable to open file (File signature not found)
From what I’ve read the vgg16_bn.h5 file might be corrupt or not in the correct format and I’m currently downloading that file from http://files.fast.ai/models/.
Does anyone know of a resolution for this? I’d really like to use batch normalization with vgg16 model.
I had the same error when trying to run this line from the lesson3 notebook: load_fc_weights_from_vgg16bn(bn_model)
After some searching, I (re)discovered that the vgg16_bn.h5 was stored in my ~/.keras/models directory. An ls -lh command revealed that it was only 63K in size whereas the oft-used vgg16.h5 (ie sans bn) is 528M.
ubuntu@ip-10-0-0-9:~/.keras/models$ ls -lh
total 528M
-rw-rw-r-- 1 ubuntu ubuntu 35K Jun 18 18:26 imagenet_class_index.json
-rw-rw-r-- 1 ubuntu ubuntu 63K Jun 18 18:04 vgg16_bn.h5
-rw-rw-r-- 1 ubuntu ubuntu 528M Jun 18 18:26 vgg16.h5
I thus wgot the file again using the link you provided and that above line from lesson 3 now runs without error for me.
Exception: Error when checking model input: expected input_4 to have shape (None, 3, 244, 244) but got array with shape (64, 3, 224, 224)
(As if the generator isn’t recognising the batch dimension?)
Any help on this would be massively appreciated. (The capacity to identify cats from dogs has become rather central to my sense of self worth over the past month…)
Lesson 5 is an amazing introduction to sentiment analysis. I tried to game the system by predicting the sentiment of a sarcastic review. Of course it failed (in fact it got better score than a truly honest positive review). Has anyone tried to train against sarcasm? Is it even possible or that’s A.I. 2.0?
phrase = np.array([], dtype="int64")
np.append(phrase, [1.])
textphrase = 'yeah sure, you should trust the reviews, by all means, this is an amazing movie, come and enjoy :/ NOOOOT'
for o in textphrase.split(' '):
if o in ids:
phrase = np.append(phrase, ids[o])
padded_phrase = sequence.pad_sequences([phrase], maxlen=seq_len, value=0)
conv1.predict(padded_phrase, True)
output ---> array([[ 0.942]], dtype=float32)
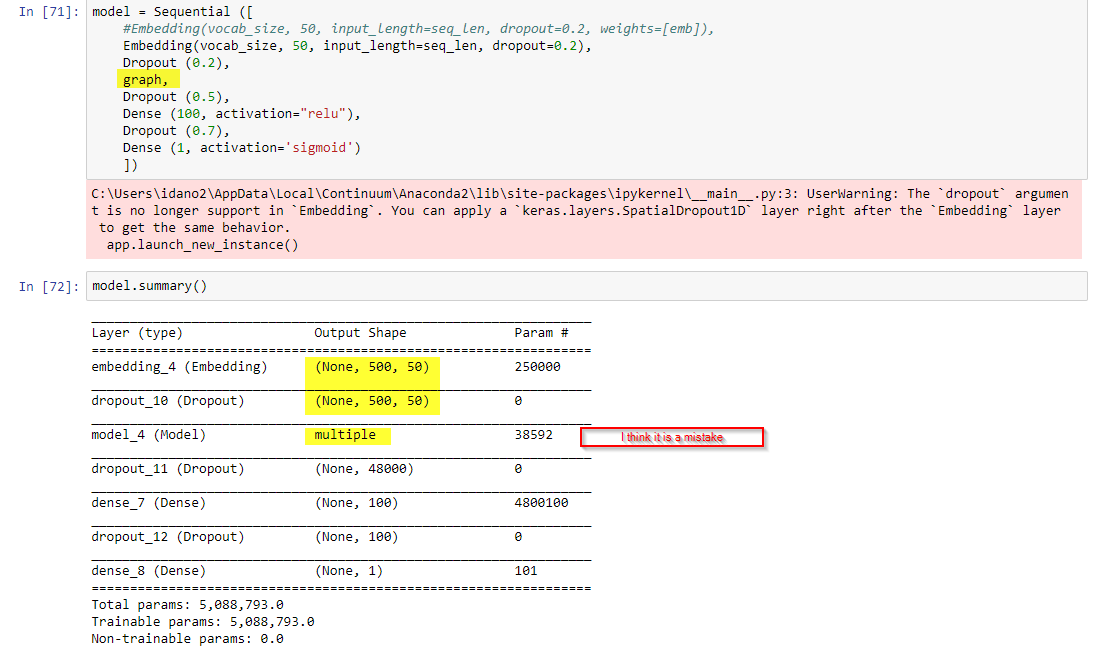
The Embedding layer is based on an output tensor of size
(None, 500, 50)
as you pointed out. This fits properly with the normalized sequence length (500) and the dimension of embedding (50) attached to each sentence.
The size of the vocabulary is only relevant to the Embedding layer to understand the range of integers used to represent the inputs fed to that layer (i.e. the result of the word2idx).
The input size of the convolutional layers however should match the length of each sentence. The filters (3,4,5) are applied to the tensor of latent factors (500x50).
While the size of the resulting matrices are ten fold in the class’ notebook vs. what they are supposed to be, the number of resulting parameters, however, does not change : it’s primarily dependent on the size of filters.
Bottom line is that it still works but it’s probably not as efficient (takes longer to train per epoch) and the results are probably slightly more “noise” prone (therefore taking more epoch to reach the same accuracy).
@Jeremy / @Rachel : if you agree with @idano 's assessment, what’s the best way to correct this ? Pull request ?
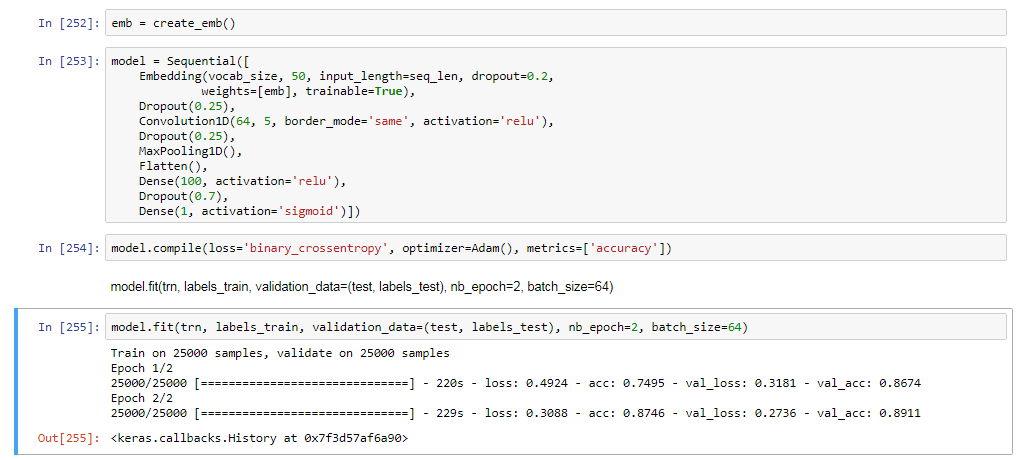
Does anyone get the different result from the lecture’s note when running the model by yourself ? I often get lower accuracy comparing with the lecture’s note result. For example below I trained the model “Single conv layer with max pooling” as in the note, but the result is very low although I did the same steps.