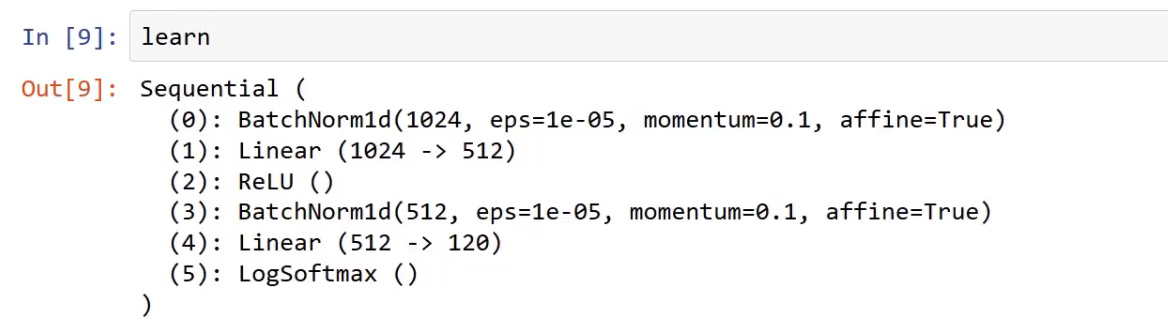
lesson4 IMDB
Hello, in the leaner.fit
learner.fit(3e-3, 1, wds=1e-6, cycle_len=20, cycle_save_name=‘adam3_20’)
I am getting the followin error:
A Jupyter Widget
0%| | 0/4603 [00:00<?, ?it/s]
AttributeError Traceback (most recent call last)
in ()
----> 1 learner.fit(3e-3, 1, wds=1e-6, cycle_len=20, cycle_save_name=‘adam3_20’)
~/workspace/fastai/courses/dl1/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
190 self.sched = None
191 layer_opt = self.get_layer_opt(lrs, wds)
–> 192 self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
193
194 def lr_find(self, start_lr=1e-5, end_lr=10, wds=None):
~/workspace/fastai/courses/dl1/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, metrics, callbacks, use_wd_sched, **kwargs)
137 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
138 fit(model, data, n_epoch, layer_opt.opt, self.crit,
–> 139 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
140
141 def get_layer_groups(self): return self.models.get_layer_groups()
~/workspace/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
82 for (*x,y) in t:
83 batch_num += 1
—> 84 for cb in callbacks: cb.on_batch_begin()
85 loss = stepper.step(V(x),V(y))
86 avg_loss = avg_loss * avg_mom + loss * (1-avg_mom)
AttributeError: ‘CosAnneal’ object has no attribute ‘on_batch_begin’