Thank you Lucas,
Yes I applied the RELU activation function.
The activation is A(layer_i) = sum( RELU( A(layer_i-1) ) * w ) . I hope this is correct.
But w is positive or negative with equal probability ( maybe this assumption is wrong).
So on average the result of the sum does not change. We never do sum(activations), we do sum(activations*w).
For calculating the mean of the activations of layer L we do sum(activations[L]) / #Neurons, and in my mind (and of course I could be wrong) that’s what changes when we apply dropout
Yes true.
I was referring to the activation of the single neuron of a layer with respect to the previous afferent activations.
I think that this activation does not change (if my assumptions are correct  ).
).
But the average layer activation changes as you said.
I have a question about filling in NA in the Rossmann notebook.
In the notebook, it states that
many models have problems when missing values are present, so it’s always important to think about how to deal with them. In these cases, we are picking an arbitrary signal value that doesn’t otherwise appear in the data.
And the code following that looks like:
joined.CompetitionOpenSinceYear = joined.CompetitionOpenSinceYear.fillna(1900).astype(np.int32)
joined.CompetitionOpenSinceMonth = joined.CompetitionOpenSinceMonth.fillna(1).astype(np.int32)
joined.Promo2SinceYear = joined.Promo2SinceYear.fillna(1900).astype(np.int32)
joined.Promo2SinceWeek = joined.Promo2SinceWeek.fillna(1).astype(np.int32)
By looking at the initial data exploration, these values do appear in the data (i.e. minimum of CompetitionOpenSinceYear is 1900 etc).
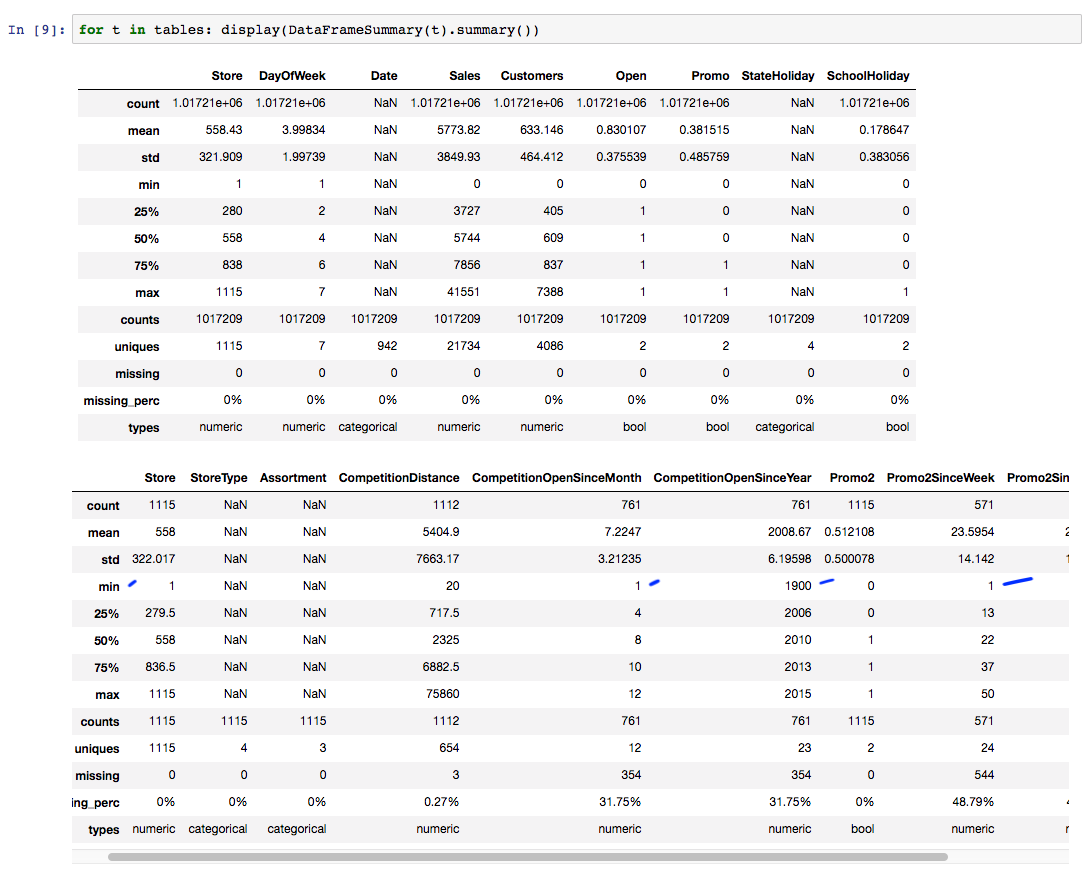
How do they work as signal values when there are some rows with these values in the original data?
I used the new trick we learned in this lesson 4 to check the model layers simply by calling learn and was surprised to see that even with binary classification the fastai models are creating 2 class output and using a Softmax activation function instead of Sigmoid with 1 binary class output.
(16): Linear (512 -> 2)
(17): LogSoftmax ()
My labels are all 0 or 1 so I’m not sure how else to tell the model that it should be using Sigmoid. Or am I just not understanding this correctly and its OK to use Softmax for binary classification problems as long as you treat it as 2 classes?
I would say it’s okay to use softmax, and just a nice observation, if you do the math you will see that the cross entropy loss used by the softmax function will simplify to the same thing as the logistic loss ^^
2 Likes
Thanks! That’s an interesting observation…Also, because of the 2 classes I’ve just been taking the logs that correspond to the “1” label since in my case the binary classification is the probability of whether or not some “thing” exists not the probability that it doesn’t exist.
1 Like
Could one pre-train zip code weights like you did the language model? A naive version could simply ensure that zip codes physically close together by distance or transit time have embeddings near each other.
Though it seems ideally one could train embeddings from travel patterns like what you’d get from credit card transactions, no?
I think it is the plural of p, not an acronym. If I remember correctly, the ps layer provides the probability for dropout layers, either as a constant (e.g. p=.5), or a list with one p for each drop out layer (e.g. p=[.2, .5, .7]) for 3 dropout layers.
I believe the loss function also tells you what direction to adjust the weights of each parameter (gradient descent), so they can be adjusted appropriately, whereas the accuracy is just a score (ok, the model is not so great, but then what?).
should be OK, as I think we used it for Cats vs Dogs. (assuming here, since we get multiclass predictions as outputs prob_dog and prob_cat, but used prob_dog for Kaggle submissions; and because of softmax it’s likely that prob_cat = 1 - prob_dog; or maybe the log of that actually )
The nice thing about softmax seems like we might not have to think/tune the ‘threshold’ as we’d have to do with sigmoidal outputs. But, once again, I’m just assuming here. Maybe @yinterian can clarify this better.
Woah ! This was definitely one of the densest lectures so far. Embeddings are so neat. All that space wasted by one-hot encoded matrices finally getting reclaimed. 
So much new stuff, will have to go back and watch the whole lecture again. Also,  @jeremy
@jeremy  for beating the state of the art like “no big deal” ?
for beating the state of the art like “no big deal” ? 
I guess we are halfway in the course now, right ? I’m already experiencing denial, not wanting this to end. 
8 Likes
Yes! You should pre-train them by making them embeddings in some different model - e.g. learning some different task. Just like pre-training on a language model and using for classification.
We know in this case that the stores weren’t actually open at that time, so we assume that it was already being used as a signal value. IIRC this is an assumption the original developers of this solution made.
Got it! Thank you 
We are doing a fastai study group in Omaha, NE this evening. @KevinB says hi!
2 Likes
That’s so cool! Learn lots!
1 Like
What do you guys think the best way to reduce high class imbalance. I am solving classification problem of diabetic retinopathy from https://www.kaggle.com/c/diabetic-retinopathy-detection. The class distribution is approximately ( class1 - 73% , class2 -3%, class3 -14%, class4 - 2%, class5 - 2%) . Should I follow the template provided for dog breed classification - or should I shed some examples out of the dominant class , so that all the classes have similar representation. Thanks
2 Likes
You can replicate the rare classes to make them more balanced. Never throw away data!
Note that it you double the number of class5 rows (for instance), your probabilities will end up too high, so you’ll need to reduce them at the end.
3 Likes
Generally you’ll want categorical, as long as there aren’t too many levels. Categorical give the model more flexibility.
3 Likes