The key difference is that we’re not just learning an embedding matrix, but a complete pre-trained recurrent neural network!
7 Likes
Sorry what trick?
Will need to re-watch the lecture quadruple times to digest.
2 Likes
Questions
- The average number of activations doesn’t change since Pytorch double the remaining activations when we say p=0.5. Maintaining average activations is to ensure we do not change the meaning i.e. losing learnt info.
Question - Which 20% activations are added when we say p=0.2? - Lecture - dropout and average without changing the meaning. , Lecture - after dropout we don’t have that much learning since we add random noise. To me, both questions seem to be similar. but I’m confused that there are 2 answers. Can anyone clarify the difference?
- p=0.1 would mean remove 10% of activations at random. Does this also imply the probability of selecting any cell is 0.1 and any cell is equally likely to be selected?
Does that mean 50-600 range is good only English? If so, complex languages like Chinese will have larger far larger implicit dimensionality?
2 Likes
There are some sequence handling techniques necessary for self driving cars. For instance if you see a “road work in 1000 ft” sign, you need to maintain an internal state and update it when you see another one down the road. There is some connection between these 2 inputs that’s perhaps too important to throw away.
I think it’s clipping any gradient above 0.3. So, basically, any gradient values greater than 0.3 will be replaced by 0.3
1 Like
would emdedding binary elements help increase their meaning as well ?
We don’t add any activations. It’s impossible to “add” an activation in this way, since an activation is simply the result of applying one linear function to the previous layers activations.
We simply scale up the existing activations.
4 Likes
It’s possible, although it doesn’t often seem to help in practice.
1 Like
Just to clarify, and someone correct me if I’m wrong, but assuming that ps is the probability that we discard/ zero out an activation we have to multiply all other activations by 1 / (1 - ps). We do this because we want the activations to have the same mean (or expected value if you want to be more mathy) before and after the dropout.
But you might ask, " Why do we care to scale the activations? If we always use the same dropout the mean of the activations will always be the same!!" That’s a good point! But remember we don’t use dropout at test time, so all neurons are firing and the mean of the activations will be higher (and that’s why use the scaling at training time). This is not the only way to implement dropout, but it is by far the most common, and it is called inverted dropout.
8 Likes
Thinking about the rescaling done behind the scene by pythorch…
The activations are positive (because RELU), the weights can be positive and negative, and since we have no information about their distribution I could imagine there is no preference to be more positive or negative.
With this assumption the average activation after drop out is the same as without dropout.
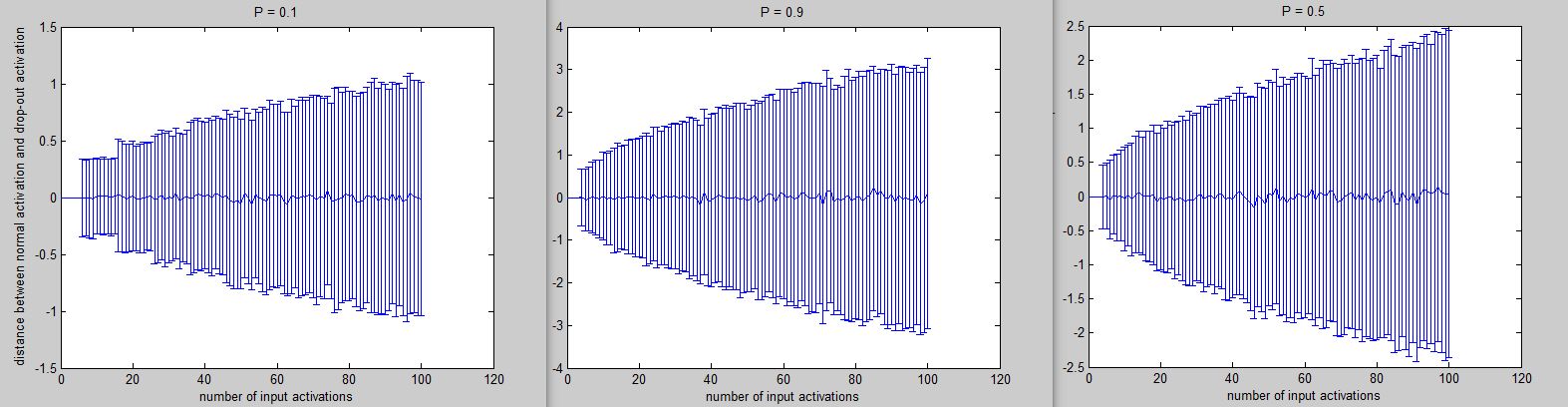
Simulation with a single neuron receiving from N neurons of the layer before.
N is in the x axis of these plots.
On Y axes the difference between activations with and without dropout. The vertical bars are the standard deviations.
For each point I did 1000 simulations, the mean as expected is very close to zero and the standard deviation is growing in different ways depending on P (drop out probability)
The point is, the output activation ( sum(weights * previous_activations)) seems not to change, on average, because we have the same probability do randomly delete a positive contribution and a negative contribution.
Am I mistaking something?
Anyway the effect of applying the dropout depends also on the number of afferent neurons. Maybe this can be useful to tune P.
1 Like
Hello @santhanam, yes I think that’s what @jeremy said at https://www.youtube.com/watch?v=IkPK1rBBcW0&feature=youtu.be&t=27m5s :
@jeremy : “You can pass ps (in ConvLearner.pretrained). This is the p value for all of the added layers (…). It will not change the dropout of the pre-trained network.”
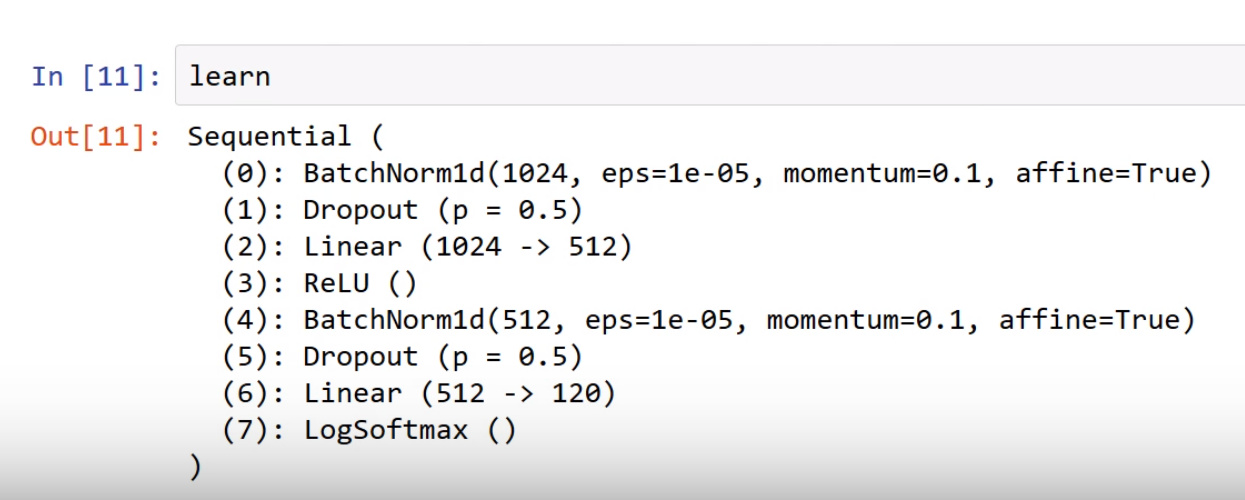
Then, it means we apply the dropout to 2 BatchNorm1d layers (cf screenshot below).
Like the 2nd one (512) follows the linear layer + ReLu (1024 --> 512), I believe that half of the 512 nodes are randomly dropped during the training (at each new batch).
The activations, as you say, are positive (because relu), so we’re applying dropout to something that is on average positive.
Also, we want the stdev to not change - i.e. the scale of the activations needs to be consistent.
3 Likes
Amazing analysis!!
Have you applied the activation function when doing this analysis? Because if you think about the relu case max(0, w * previous_activations) it really makes sense for the mean of the activations to go down, because when taking the mean we do sum(activations) / #neurons, and when applying dropout sum(activations) will be a lower number (since all activations are positive, and a bunch of them just got zeroed), and consequently the mean.
EDIT: @jeremy just answered this some minutes before I did 
1 Like
When we apply dropout to the positive activation we are in fact making it equal zero. Do we?
Then this zero activation multiplies the corresponding weight (going toward the next layer), so this contribution become zero.
Since we are making these contributions zeros (and they would be positive or negative without dropout) on average we keep the same mean.
I mean (sorry for abuse of ‘mean’) , of course we apply the dropout to a positive activation but I am looking at the effect on the neuron to the next layer.
Are we able to download arxiv.csv and all_arxiv.pickle somewhere?
I’m trying to follow lang_model-arxiv.ipynb to use my own dataset to build a language model and perform a classification task.
I also found this Torchtext guide, which uses a .tsv file format (and seems simpler for my task), but I’m not able to get it to work.
I had an error when running TextData.from_splits while specifying all three train, val, and test in the torch Dataset, seemingly because TextData.from_splits has a line that only anticipates receiving trn_iter,val_iter as a return value.
I worked past that by not specifying test data, but then ran into another issue when torchtext was sorting batches, so I suspect I’m not setting up something properly.
FWIW here’s a gist. The dataset is a very small one I made and not an interesting problem =). I just wanted to see if these new techniques we learned can work on a small dataset.
3 Likes
Yes true. But the stdev is halved - it’s really the mean of the scale (or abs values) that we need to keep the same.
I somewhat less complete version of the arxiv data is here https://hackernoon.com/building-brundage-bot-10252facf3d1
1 Like