@zaoyang It is not so much loss than the data is compressed. Deep Learning is about reducing the noice inside the data and getting its essential characteristics.
Their is a lot of loss happening in the max pooling layer. This is something people do not like especially Hinton (one of the godfather). New research is coming in to solve that.
But we keep using them because it just works in practice.
4 Likes
Can we please pick our own seats next time? I can’t see with where my group is placed.
It’s actually weighted. It’s the 3x3 subset coming from your layer weighted by your filter. It’s the weighted sum. (was that your question?)
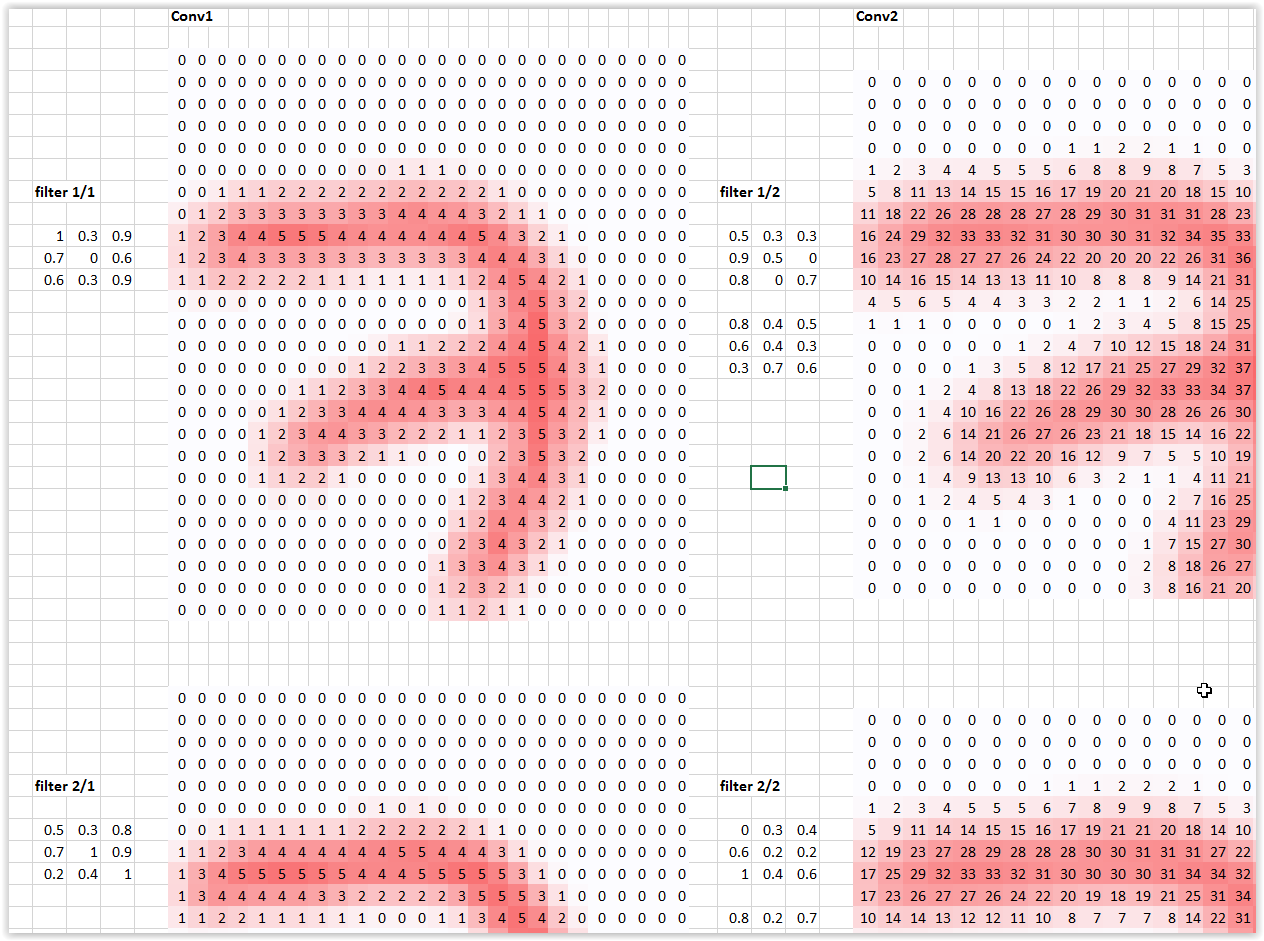
Regarding the spreadsheet - I have a different set of values (see below) in filters 1/1 and 2/1, and then in the conv2 layer, I guess the spreadsheet might be out of sync?
Any good resources for the fully convolutional layers?
@jeremy you’ve briefly mentioned that you used network pre-trained on 3-channel input on a 4-channel input (RGB+NIR), by adding additional dimension to all pertained filters (initialized to 0 or perhaps random). Did you then ‘unfreeze’ these additional new filter weights along with the ones for RGB channels and train them?
7 Likes
We’re getting sound
Hm ok thanks guys.
Got it. I feel like my video breaks every time we go on break, lol
okay but there are a lot of layers and they all “learn” different things. If you are pruning out non relevant data for one layer, it could be essential for another layer. So I guess the question is how can each layer learn “essential data” independently whereas the data flows through the layers in a dependent way.
3 Likes
That’s what SGD is for, the model is learning what is important to produce a good result.
where is planet data ?
2 Likes
If you’re like me and can’t remember what SGD means, it’s stochastic gradient descent.
2 Likes
Is there a way to specify that the cloudy, clear labels are a softmax type, while the cover labels should be done with a different activation?
4 Likes
Does anyone remember (or can we get a reminder) of the commands within ipython to see the function’s input parameters and to see it’s source. I was looking for that part of the previous lectures and couldn’t find it.
shift + tab will give the input parameters, ??command_name will give you the source, Shift + tab 3 times will give you the documentation
2 Likes
what is the activation function used for multi label classification?
4 Likes
My image_models notebook is a little different from what jeremy is explaining now. i did a git pull but it shows the same as i had before.