Thanks !
I try to create them during my 2nd pass on watching the video, because fast-forwarding through several x2 hours videos for those 5 mins dedicated to ‘data.resize()’ or ‘knowledge distillation’ drove me nuts in Part 1 v1 
2 Likes
Yes, about the overfitting. I have tried this and my model went from being nicely balanced to horribly overfitted. I don’t know what to make of the information though, as its only ever validating agianst one image in this scenario. See this post: Dog Breed Identification challenge
Whereas I had achieved around 0.200 loss prior to this, after it I had 0.230 loss - but again I am not sure how to understand it 
When I submitted this “enhanced” model to kaggle it had a 0.2275 loss, so it looks like it did something like the predicted accuracy, which was not very good to say the least! Perhpas @jeremy could let us know if there is a best approach to doing this, as I struggled to piece together an approach from reading numerous posts, and likely stuffed something up!
@Chris_Palmer training on all of the data is a bit tricky because you have to follow all the same steps you did when you had set aside the validation set, any variance could cause overfitting. To be honest with you, before this course I never even considered training on all of the data for those reasons and instead my approach was always to use K-Fold cross-validation.
In case you aren’t aware of how it works, the idea behind CV is that your model does get to see all the data but it sees it in folds (each time the validation set is a different split of the data), at the very end you take the average of all the folds so your predictions are a reflection of all of the data. With CV you get the luxury of verifying that each fold is not overfitting and then feel comfortable taking the average of all folds for the final prediction.
@sermakarevich has provided a lot of good examples on how to use cross validation with fastai so you should check some of his posts on that if you wanted to try it out. Otherwise I think Jeremy is also planning on covering this in more detail since he created a notebook for it but its not quite completed yet so probably best to wait before exploring it if you are new to this concept.
3 Likes
Hi @jamesrequa
Yes, I have used k-fold cross validation in standard ML. But I am confused about its use with deep learning. I have observed that with each training cycle I go through my model improves, but then goes towards overfitting. So it seems like a very fine line between a good model and one that is no longer so good, more is not neccessarily better. Although you are varying the data the model is learning on with CV, are you not also training the model many times more - and is there not a risk of overtraining it?
Actually no because the model starts over fresh for each fold. It doesn’t continue training other folds with the saved weights, those weights are reset each time.
I also recommend reading this post from fastai blog courtesy of @rachel, it should help you build up more of an intuition about this stuff
http://www.fast.ai/2017/11/13/validation-sets/
2 Likes
Thanks @jamesrequa
How are we making use of these models, if we reset the data and weights for each fold? The only model we have “in hand” is the current one, yet we want to combine these various CV models to a good effect for doing a prediction.
Likewise if we try to create an ensemble of different architectures…
For each fold (and for different models from other architectures), are you processing the model all the way through to predicting on the test data, and preserving those predictions, before cycling through to another fold?
Is there a lesson 4 wiki yet? I can’t find it.
We typically would generate predictions on the test set after each fold with those trained weights. So the predictions are then what we would average for the 5 folds at the end. Similarly, you can repeat this same process with multiple different models and then take an average of those different model’s predictions.
You can also save the weights of your model at any point by using the function learn.save('model'). So alternatively you could save the weights and then after you are done training, you can load the weights back in with learn.load('model') and just run predictions directly from those weights.
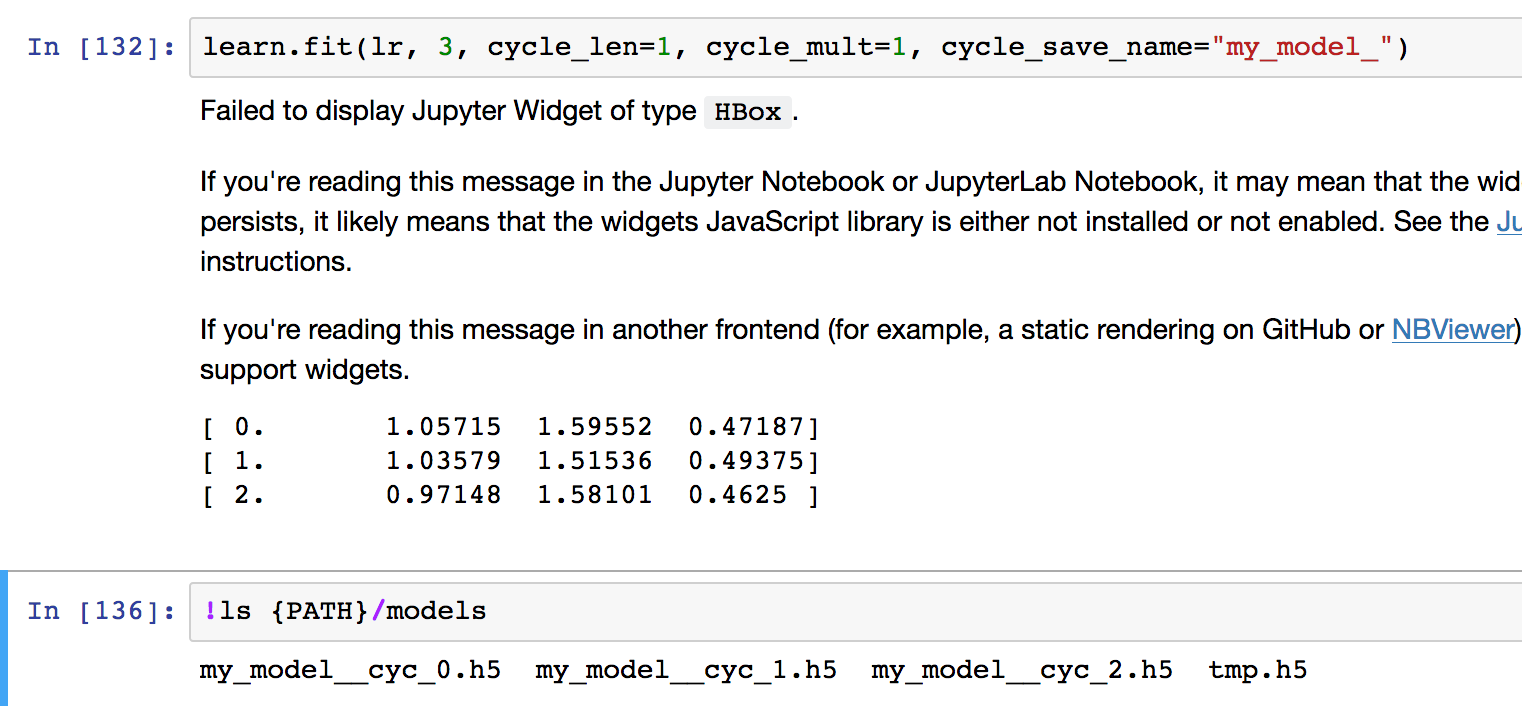
If you pass in the cycle_save_name parameter into the learn.fit like learn.fit(lr, 3, cycle_len=1, cycle_mult=1, cycle_save_name="my_model_"), it will save the weights from each Cycle. Then you can load them and run prediction on them and ensemble these Cycle predictions.
Currently you have to load them independently into separate models and then predict on them multiple times. Could be useful to have a method called load_cycles to load all these models and return ensemble like Scikit-learn’s VotingClassifier. 
8 Likes
Ah…didn’t realize you guys were talking about cross-validation and not cycle prediction. So, ignore my comment above. Hope it’s still useful for someone.
1 Like
Yep I think its still very useful information. What you are describing is Snapshot Ensembles which is also a really great feature! I think Jeremy actually did create some functions in the planet-cv notebook for something similar to what you were suggesting, so maybe check that out!
1 Like
Actually would this is useful for picking a better cut-off for model? I have seen my model deteriorate (to overfit) and I wished I had been able to stop training on it earlier, so maybe I could use this approach to retrieve that better point in time?
1 Like
Thanks for this advice @jamesrequa. What functions are you using for saving your predictions - are they the bcolz ones referred to earlier in this wiki? Lesson 3 In-Class Discussion
def save_array(fname, arr): c=bcolz.carray(arr, rootdir=fname, mode='w'); c.flush()
# Example
save_array('preds.bc', preds)
What about reloading, do you have a function for that?
I have not had much success with reliably getting a model I can reload using learn.save. That is, I have performed a learn.save, then come back later (after closing then restarting my AWS), and have not been able to learn.load…
1 Like
Yes that’s usually what I use to save my prediction arrays.
def load_array(fname): return bcolz.open(fname)[:]
1 Like
Thanks James. Are you attending lesson 4 right now, I can’t find a working link…
2 Likes
Yes, me too, is there a lesson 4 this week? or Time changed?
yeah what’s the link for the video lesson? Is there a wiki: lesson 4?
Here you can find a nice visualization of how the convolution filter works (around the middle of the page):
@jeremy I am revisiting the lecture and have a couple of questions:
- Why starting with smaller image sizes helps avoid overfitting?
- Why training and validating transforms are different?
- For the sat images you used resize to 1.3*sz, where sz=64. But then went on to double the size. The resized images are smaller than the requested size (2*64>1.3*64). How does that work?
1 Like
Maybe mine response might be helpful as well:
- Because you do not want to apply transformations on a validation set. Transformations are used to add variability to your train set when you don`t have enough data. To improve predictions quality by randomising image we have TTA.
1 Like