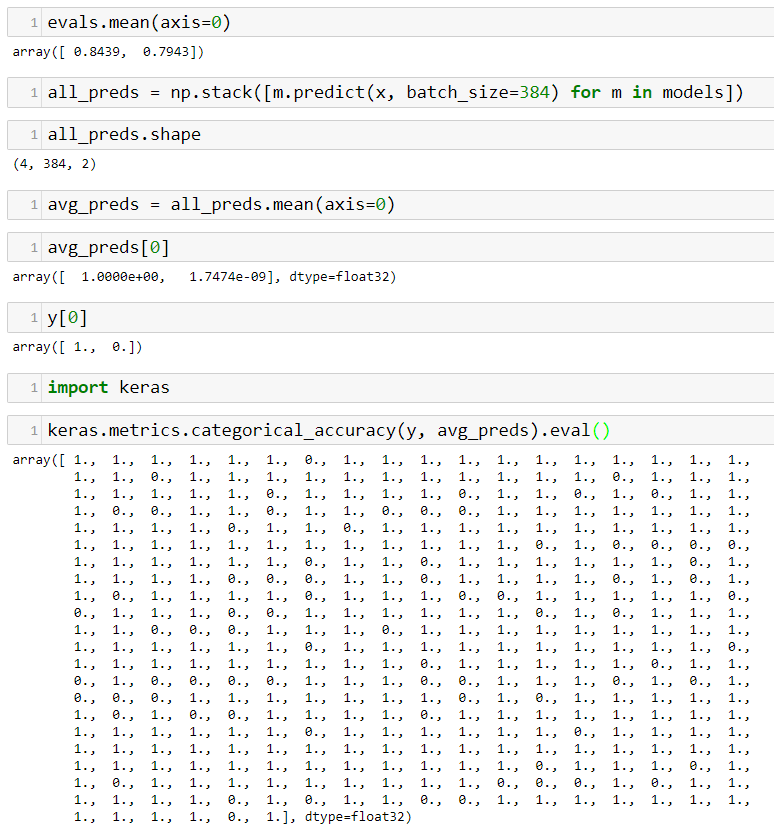
EDIT: I tried to make this post a reply to Lesson 3 discussion, but it didn’t seem to work. Please see that link for more context.
Well arg… I followed the advice from @jeremy in the video, and the re-dimensioned arrays look like those in the video:
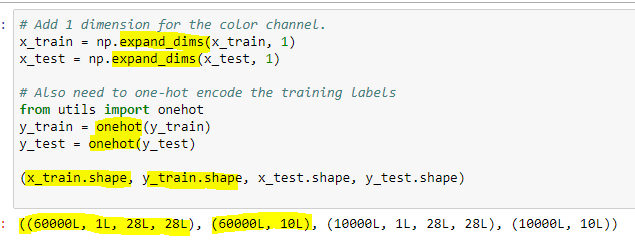
However, now I’m getting an error when trying to plot the array:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-f1e62e015ecf> in <module>()
----> 1 plot(images[inspect_idx])
<ipython-input-15-def34cadf765> in plot(im, interp)
10 def plot(im, interp=False):
11 f = plt.figure(figsize=(3,6), frameon=True)
---> 12 plt.imshow(im, interpolation=None if interp else 'none')
13
14 plt.gray()
C:\Users\matsaleh\AppData\Local\conda\conda\envs\fastai2\lib\site-packages\matplotlib\pyplot.pyc in imshow(X, cmap, norm, aspect, interpolation, alpha, vmin, vmax, origin, extent, shape, filternorm, filterrad, imlim, resample, url, hold, data, **kwargs)
3155 filternorm=filternorm, filterrad=filterrad,
3156 imlim=imlim, resample=resample, url=url, data=data,
-> 3157 **kwargs)
3158 finally:
3159 ax._hold = washold
C:\Users\matsaleh\AppData\Local\conda\conda\envs\fastai2\lib\site-packages\matplotlib\__init__.pyc in inner(ax, *args, **kwargs)
1895 warnings.warn(msg % (label_namer, func.__name__),
1896 RuntimeWarning, stacklevel=2)
-> 1897 return func(ax, *args, **kwargs)
1898 pre_doc = inner.__doc__
1899 if pre_doc is None:
C:\Users\matsaleh\AppData\Local\conda\conda\envs\fastai2\lib\site-packages\matplotlib\axes\_axes.pyc in imshow(self, X, cmap, norm, aspect, interpolation, alpha, vmin, vmax, origin, extent, shape, filternorm, filterrad, imlim, resample, url, **kwargs)
5122 resample=resample, **kwargs)
5123
-> 5124 im.set_data(X)
5125 im.set_alpha(alpha)
5126 if im.get_clip_path() is None:
C:\Users\matsaleh\AppData\Local\conda\conda\envs\fastai2\lib\site-packages\matplotlib\image.pyc in set_data(self, A)
598 if (self._A.ndim not in (2, 3) or
599 (self._A.ndim == 3 and self._A.shape[-1] not in (3, 4))):
--> 600 raise TypeError("Invalid dimensions for image data")
601
602 self._imcache = None
TypeError: Invalid dimensions for image data
Seems pretty clear that matplotlib wants a 3-dim array, not 4-dim.
I thought I was on the right track, but … I still do, but there’s a missing piece to this puzzle. I’d welcome any insights from @jeremy, @rachel or anyone else at this point.