Another user had contacted kaggle about it. Hopefully we will get an answer on this soon.
Hi Jimmy, thanks for the info. Hopefully Kaggle will resolve the issue soon.
The MNIST notebook uses test_batches as validation data for model fitting. Shouldn’t the validation set be partitioned from the training set, thereby reserving the test data only for final model evaluation?
A second question: in the data augmentation section of the MNIST notebook, why are test_batches augmented?
Hi
I wanted to use VGG16 for statefarm. I could easily achieve %85 accuracy by finetuning last layer. Then I tried to change last dense layers dimensions but I get validation accuracy sticked at %10, meaning it doesn’t work at all.
Rather than getting predictions of convolution layers and feeding them to new linear model, I tried to change Vgg model directly by changing Dense layers. Why It doesn’t work?
This is what I did:
vgg = Vgg16()
O = Vgg16()
# removing layers after first dense layer
denses = [i for i, l in enumerate(vgg.model.layers) if isinstance(l, Dense)]
denses.pop()
for i in range(denses[0], len(vgg.model.layers)):
vgg.model.pop()
for l in vgg.model.layers: l.trainable = False
# adding dense layers same as VGG16
vgg.model.add(Dense(4096, activation='relu'))
vgg.model.add(Dropout(.5))
vgg.model.add(Dense(4096, activation='relu'))
vgg.model.add(Dropout(.5))
vgg.model.add(Dense(10, activation='softmax'))
# even load trained weights of VGG16
for d in denses:
vgg.model.layers[d].set_weights(O.model.layers[d].get_weights())
# resetting classes to statefarm's
classes = list(iter(batches.class_indices))
for c in batches.class_indices:
classes[batches.class_indices[c]] = c
vgg.classes = classes
vgg.compile()
vgg.fit(batches, val_batches)
I expect vgg work exactly like finetuned O with 10 but val_accuracy never changes on subsequent epochs while O could achieve %85 accuracy.
Actually I can pop Vgg16’s last four layers and It will work by adding another dense, but If I pop last five layers (that means removing all layers after flatten) this problem will happen again.
1 Like
Does data augmentation help when fine tuning the final dense layers of a pre-trained neural network?
justin,
Did you run cell 79 again after running cell 80? Otherwise, I’m confused just like you were months prior. Why would we initialize the weights to bn_layers to be the prior bn_model weights after we’ve already attached bn_layers to the conv_layers and thus created the final_model object? It seems like we should run cell 80 before cell 79 since the scope of cell 80 shouldn’t extend to the bn_layers that have been appended to the final_model object.
Thanks,
Patrick
Hi Partick,
I didn’t run the cell 80 after running cell 79, because maybe cell 80 is used to create another model, and applying the weights to the new model(I can’t remember very much), but one thing is for sure, you can ignore the cell 80 like we’ve discussed above, it won’t effect the following codes.
I am facing the following errors. Has someone seen this already and knows the answer
def get_lin_model():
model = Sequential([
Lambda(norm_input, input_shape=(1,28,28)),
Flatten(),
Dense(10, activation=‘softmax’)
])
model.compile(Adam(), loss=‘categorical_crossentropy’, metrics=[‘accuracy’])
return model
lm = get_lin_model()
Error as following
178 outbound_layer.name +
179 '" should return a tensor. Found: ’ +
–> 180 str(output_tensors[0]))
181 if len(output_tensors) != len(output_shapes):
182 raise ValueError(‘The get_output_shape_for method of layer "’ +
TypeError: The call method of layer “lambda_3” should return a tensor. Found: None
1 Like
this problem is for the mnist dataset in lesson-3
This is my first post, so I hope I am in the correct section.
I have a question on Lesson3 workbook. We split the VGG model into convolution and FC networks, then calculate the output of the convolution part. How does this work?? When we do:
trn_features = conv_model.predict_generator(batches, batches.nb_sample)
My understanding is that predict will create predictions of class membership (labels or probabilities). And so, I would expect any output from a predict method to be either labels or class probabilities. The output of predict_generator seems to be representation features from the convolution layer. I looked at the source for predict_generator w/o any insight.
Any suggestions would be welcomed. Thanks
The predict generator is going to just output the values of the last layer of the model on which it is called. If the last layer is something like a softmax than you can calculate labels. In your case the last layer is a conv layer / max pool and hence the output will be the features extracted by the convolution layer. It is a hacky way to speed up the process of training. It will be more clear when you learn about the functional api in the next classes.
Hi,
How’s the preprocessing different with TensorFlow backend? Is it only the channels that differ, i.e. the input_shape from (3, 224, 224) to (224, 224, 3) ?
Thanks!
Hi,
I was wondering why you use training features to train w/o dropout instead of directly using the batched pre-computed in previous steps. It adds extra calculations that can be avoided according to my low-level criterion :D. I suppose that I’m wrong but I would like to know the explanation for this thing.
Thanks
Hi all,
I think I am missing a piece of the puzzle when it comes to SGD, I wonder if anyone can point me in the right direction? My naive assumption is that using a linear model comprising the last fully connected layer of a network should behave in exactly the same way as a linear model comprising of all the fully connected layers of a network where only the last layer is trainable.
In lesson 2 under the section Train linear model on predictions, subsection Training the model, Jeremy gets the features from the penultimate layer of the CNN and then uses these as input to a linear model which he defines and compiles as
lm = Sequential([ Dense(2, activation='softmax', input_shape=(1000,)) ]) lm.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
This is great and speeds up the fine tuning process enormously.
In this lesson we split the model into conv_model and fc_model, to experiment with removing dropout. Instead of removing dropout I wanted to perform the same experiment as in Lesson 2 with the final fully connected layers. That is only set the last layer in fc_model to trainable=True. To achieve this I use the below approach where I copy the initial weights from lm to the last layer of fc_model, with the assumption that both models will now behave in the same way.
def get_fc_model():
tmpModel = Sequential([
MaxPooling2D(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
Dense(4096, activation=‘relu’),
Dropout(0.5),
Dense(4096, activation=‘relu’),
Dropout(0.5),
Dense(2, activation=‘softmax’)
])
for l1,l2 in zip(tmpModel.layers, fc_layers): l1.set_weights(l2.get_weights())
tmpModel.compile(optimizer=opt, loss=‘categorical_crossentropy’, metrics=[‘accuracy’])
return tmpModel
fc_model = get_fc_model()
for layer in fc_model.layers: layer.trainable=False
fc_model.layers[-1].trainable = True
fc_model.layers[-1].set_weights(lm.layers[-1].get_weights())
If I set opt=RMSprop(lr=0.01) I can train lm using lm.fit, however unless I reduce the learning rate to 0.001 I cannot train fc_model. By that I mean the accuracy stays around 0.5, from which I imply that I have overshot the minimum by choosing a learning rate which is too great.
If I set opt=SGD(lr=0.1) again I can train lm, however I have to reduce this to lr=0.001 to get fc_model to train.
What am I missing?
Hi all,
It appears my assumption above was correct. I was getting the described behaviour because the first two layers of fc_model were still trainable even though fc_model.summary() output
Total params: 119,554,050
Trainable params: 8,194
Non-trainable params: 119,545,856
According to the documentation (which I should have read more closely) How can I “freeze” Keras layers? after setting the trainable property the model needs to be compiled.
Thank you.
Hi and thanks to @jeremy and @rachel for this wonderful class!
I’m starting the Lesson 3 lecture video, and the review of the key concepts, and I’m walking through the convolution-intro.ipynb notebook. I don’t have Tensorflow installed currently, so I followed @jeremy’s advice (which now I cannot find) and used the Keras MNIST dataset instead. Now, I’m getting strange results:
- The number of images in the Keras dataset is different. TF has 55000, and Keras has 60000.
- The ordering of images is different. The 0-th image in TF is number ‘7’, but the 0-th in Keras is ‘5’.
- Most concerning is that the images demonstrating the
corrtopdetails are very different.
Details:
Getting the dataset from Keras:
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data() # saves to /root/.keras/datasets/mnist.pkl.gz
Then I assigned the images and labels variables as follows:
images=x_train
labels=y_train
n=len(images)
images.shape
Output: (60000, 28, 28) (NOTE: TF was (55000, 28, 28)).
I computed the corrtop value using the existing code:
corrtop = correlate(images[inspect_idx], top)
Here are the plots of the resulting corrtop data. The original TF versions on the left, mine on the right. Note that the numeral ‘7’ is a different index and a different sample, so the shape is different. That’s not my concern. My concern is the overall appearance. It looks like something is wrong with the filters or something.
plot(corrtop[dims])
TF: Keras:
Keras: 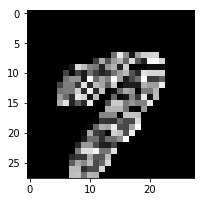
plot(corrtop)
TF: 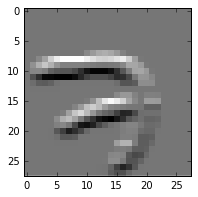 Keras:
Keras:
Can anyone shed light on why such a difference here? The only change I’ve made really is to use the Keras dataset instead of the Tensorflow dataset.
Thanks much!
Dimension ordering is different inTensorFlow compared to Theano. In TensorFlow channels come last.
I think I found a clue to this in the Lesson 3 video at: https://youtu.be/6kwQEBMandw?t=6574. Here it says that Keras expects color images, and has a channels dimension that carries that information. But the MNIST data is B/W and omits that dimension. Not accounting for this can lead to weird errors with MNIST in Keras. I think this is what my problem is.
I’ll be trying this out soon to confirm.