Hi all, I’m witnessing some funny behavior in my training val_loss and val_acc. It will wobble around all over the place instead of being consistent. I’ve tried a few architectures on sample redux data and it seems to be happening architecturally agnostic. My hypothesis is that it has something to do with the data_aug being too different from the val set, has anyone run into this before? Especially, where a val_loss of 7 is sandwiched between .13 and .47?
I’ve taken the vggbn model and kept the last 3 conv layers and 1st dense layer trainable. Then I’ve popped everything after that and added my own tail.
A followup - I’ve tried modifying data augmentation which didn’t do anything but modifying the validation shuffle=False and lowering the learning rate seems to have at least made it more consistent and better performing.
“We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.”
Also does this half the weights of the corresponding fc layers only or all the model’s layers… i believe model will have a lot more layers than fc_layers
Embarrassingly enough, I was stuck on this for a bit too until I looked about 10 lines up from there, where another var called model is declared within the scope of the get_fc_model function:
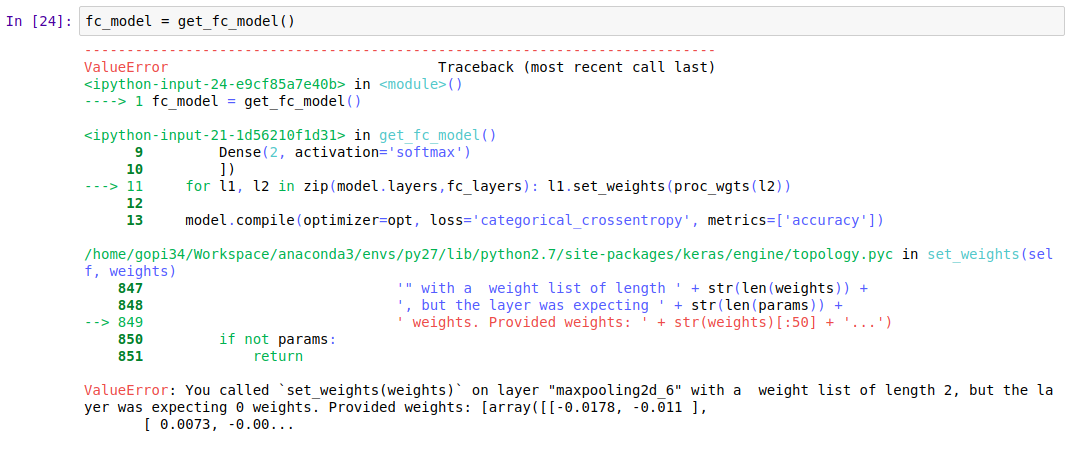
def get_fc_model():
model = Sequential([
MaxPooling2D(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
Dense(4096, activation='relu'),
Dropout(0.),
Dense(4096, activation='relu'),
Dropout(0.),
Dense(2, activation='softmax')
])
for l1,l2 in zip(model.layers, fc_layers): l1.set_weights(proc_wgts(l2))
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
It is confusing because a different variable called model is previously defined at the notebook level and holds the whole finetuned VGG model. Anyway, wanted to respond for completeness’ sake, but hopefully this will save someone a bit of time too.
Hi,
In lesson 3 notebook vgg16bn is used while adding batchnorm instead of vgg16.
Why vgg16 can not be used? What is the basic difference between both of them.
I am having difficulty following the examples. The code in the video and lesson 3 notebook do not match and I am not sure to either follow the lesson 3 notebook or the imagenet_batchnorm notebook. And also if i have to follow the imagenet_batchnorm notebook, do i need to download the imagenet data as suggest under the solution section.
Do i have to download the imagenet data for the cats and dogs batch normalization as suggested under the solution section in imagenet_batchnorm1 notebook.
Hi! I am having difficulties fine tuning the other, deeper, Dense Layers in VGG when trying to finish the State Farm Kaggle competition. I have fine tuned the last Dense Layer and would like to train the two other fully connected layers. Did this by using directly “vgg.finetune”.
Not much of a coder as I started learning Python like a bit over a month ago, so this might be a “silly” question, but I can’t figure out what I should do.
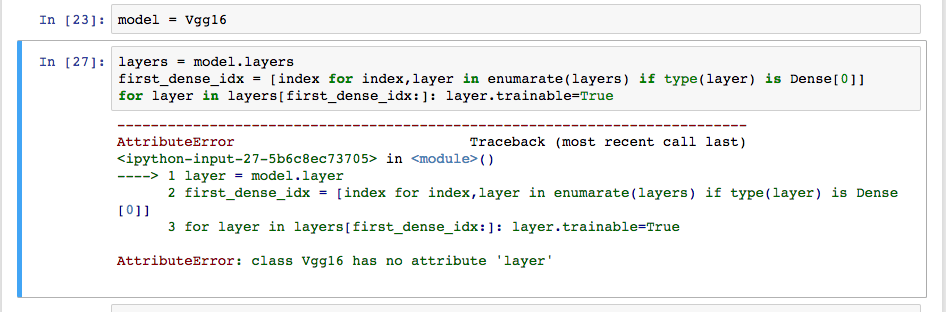
Do I need to import something from keras.models or keras.layers to make this work?
Or do I need to replace “first_dense_idx” with the index of the first dense layer? If so, how can I find out what the index is?
was referring the mnist notebook which provides an end to end model for doing regularization.
In creating a model with single hidden layer, jeremy uses an activation layer = ‘softmax’. The snapshot is shown below:
Hi, I am experiencing this same problem. I don’t understand what is meant here. How do I copy the config? Do I need to create the model from scratch, i.e. add all the layers in Keras, in that case how to handle vgg_preprocess?
Alternately I have tried simply using the existing model and deleting all layers after the first conv layer i.e.
num_del = len(layers) - last_conv_idx - 1
for i in range (0, num_del): model.pop()
conv_model = model
(Note I create the FC model first so I don’t lose the fc weights). I would have thought that this would produce the correct conv model as the weights are intact. But when I run conv_model.predict_generator(batches, batches.nb_sample) the output shape is (23000,2). which will obviously not work as input for the fc model.
the last layers of the conv_model do have have the correct dimensions so i would expect output shape of (23000,512,14,14)
convolution2d_12 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_12[0][0]
Hello,
In the last part of Lesson 3, Ensembling was explained. However, If I remember correctly ensembling of different models is done when each individual model is different and performs well on different parts of data. However, the same architecture and parameters were used to make the 6 models. What is the difference between each model?
Hello, I’m having some issues finetuning the model. When I load my weights and set the dense layers to be trainable, I’m stuck at around .5 accuracy. I’m puzzled and not sure how to solve the problem. Does anybody know how to fix this?
I am trying to build the satellite model in Keras. I have used pretrained VGG19 and the model on 64x64 images. Now I want to train the same model with 128X128 images just like it is done in this lesson. How should I go about this?
The problem is that while building the model in keras we have to specify a parameter with the size of the inputs
I’m getting the same error:
System ERROR:
Unknown error -2147024872
tar: This does not look like a tar archive
tar: Exiting with failure status due to previous errors"
Did anyone else run into this issue and find a solution?
downloading the files to my machine and then uploading to Jupyter Notebook (takes a little while)
changed path to path = ‘/home/jupyter/tutorials/fastai/course-v3/nbs/dl1/data/planet/’
made sure that the file “train-jpg.tar.7z” was the one being unpacked by 7zip vs. “train_v2.csv.zip” (note that the csv file is being unziped by “! unzip -q -n {path}/train_v2.csv.zip -d {path}”)