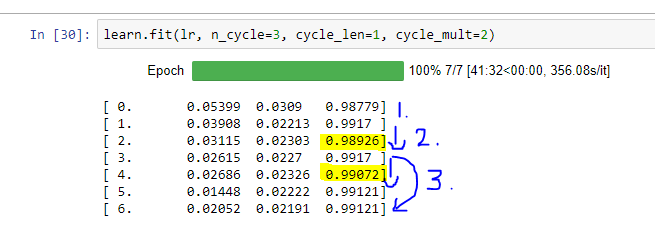
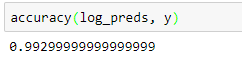
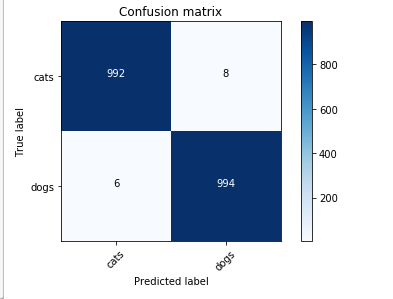
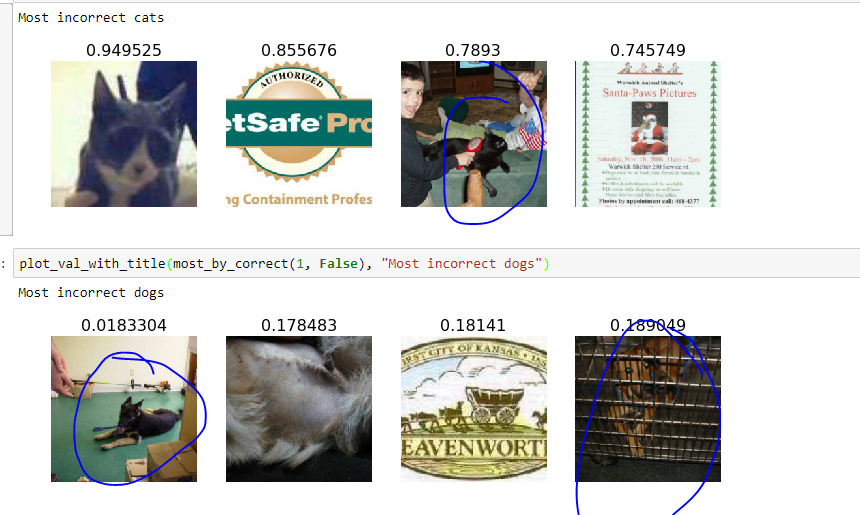
Hey Jeremy, In the lecture you mentioned that we can save the weight after each cycle in SGD with restarts by passing cycle_save=True. How would we get those weight and average result over them ? Would we have create several models and assign saved weight to them and then manually average result over predictions ? Or is it something fastai library can do for us ?
1 Like
You can use learn.load_cycle - but if you look at the code for that you’ll see it’s a little one-liner. Other than that, it’s up to you to load them each and average over them. I think planet_cv.ipynb may have an example.
1 Like
I got a Windows machine with GPU. I have configured Tensorflow with GPU on the Windows machine. I am not sure if we can test FastAI and PyTorch code on Windows with GPU.
Hi …
Just wanted to know that how can I improve an images quality.??
I tried scaling the image twice but it’s kind of getting blurred…
Can you explain more about what images you want to improve their quality, and why?
It might be wrong thread to discuss, Sorry for that…
Hi Jeremy,
Haven’t updated the post yet with code…(it’s lacking comments and all…)
The images are in single channel…
The input to the network is a low resolution image
The output from the network is a scaled image
For example,
Input dims are 160*240,
Output dims will be 320*480 …( assuming that the Scaling Factor is 2)
Actually I was able to implement this…
That’s why I was asking…
The loss is decreasing but the final image generated is a bit blurred…
Thanks for help.
Hi Jeremy,
I have an use case where I am trying to predict the bounding box of the target along with the classification. Would we be doing any bounding box classification? Any good reading materials on how to go about object localization with bounding boxes?
2 Likes
We did exactly that in lesson 7 last year - have a look at that.
2 Likes
@jeremy it really hits me now what you are saying about this. If the images in the dataset are of varying sized rectangles then it is better to center crop because with a stretched resize the resulting resized images will not have a consistent stretch (some might be stretched more horizontally vs vertically etc.) which makes it probably a lot harder for the neural net to learn/classify… Never really thought about this before, so thanks for the insight!
4 Likes
I pushed some code that should have fixed this.
What is the purpose of dividing us in teams ?
yep now it works, thanks!
I tried to apply learning rate finder for iceberg vs. ship image data. The loss vs. learning rate plot is little odd. Why is below plot not converging to a minimum? I think it is related to learn.lr_find() which found apt learning rate in relatively small number of iterations. Any comments about it?
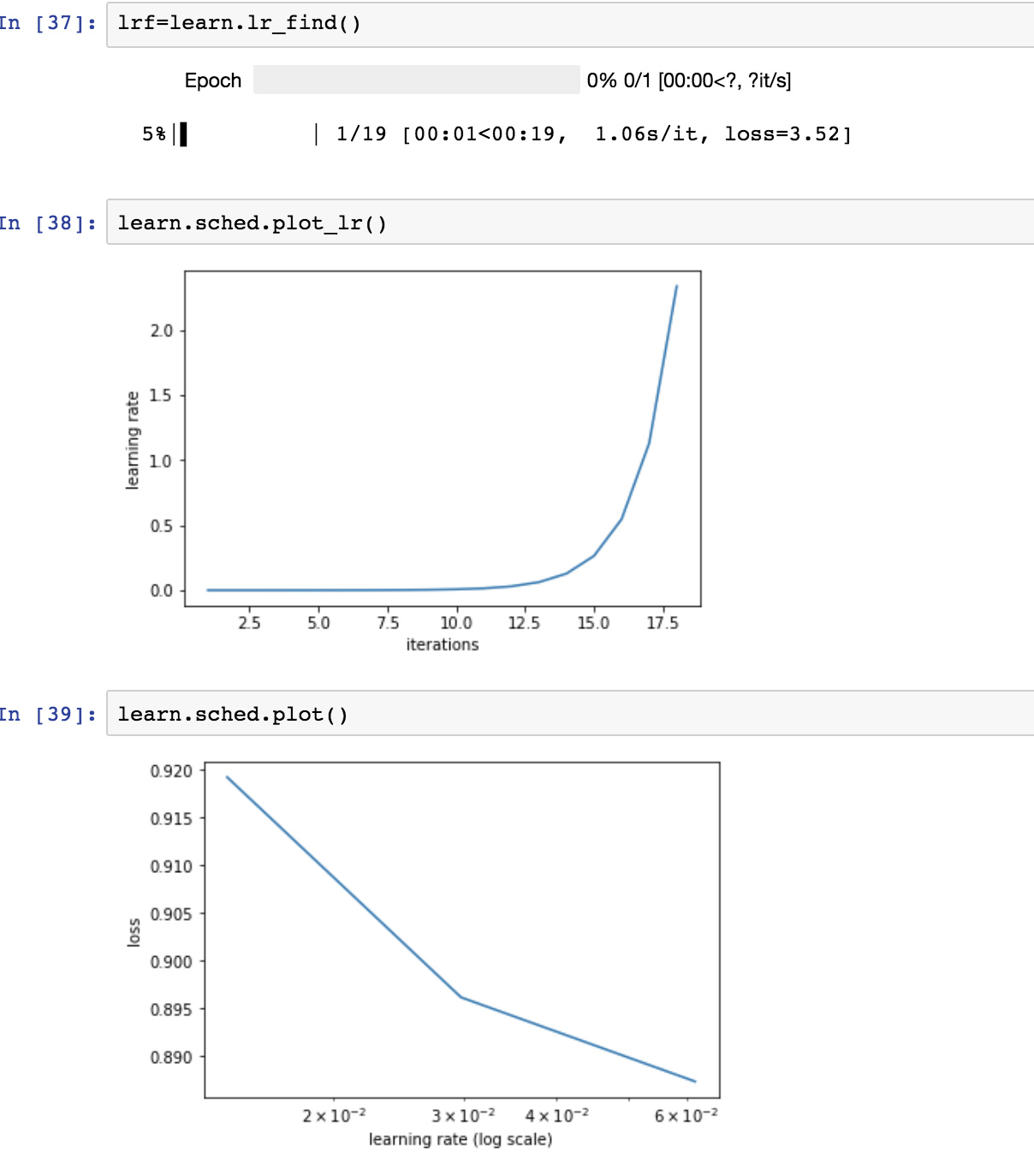
2 Likes
It may be due to resolution of images in the dataset. I also encountered similar type of learning rate for images of shape(48*48). Can you share the image shape for both datasets.
It could be a possibility. Image sizes are 75*75 in this case
Thanks. I checked it.
I understand either resnet34 might not be a good model for this or imagenet might not be good image data for this. Anyways, I tried to change batch size parameter in ImageClassifierData.from_paths and it gave relatively logical loss vs. learning rate curve. So default batch size of 64 was not good for my data, probably because my train data was not large enough and learning rate finder stopped in less iterations.
See below –
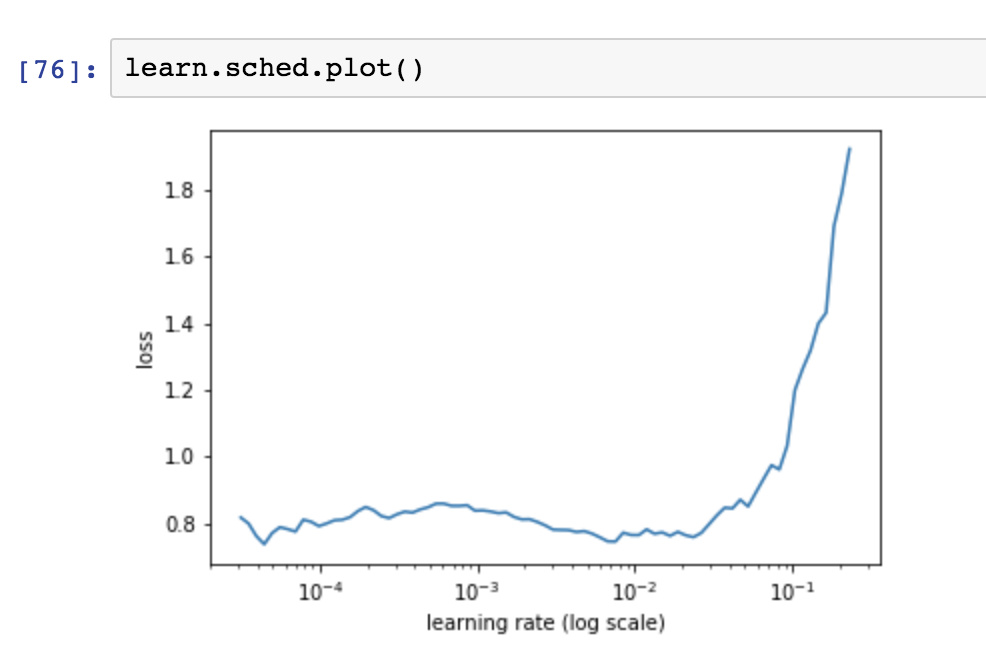
Few questions about our process:
Highlighted in bold against each point
- Enable data augmentation, and precompute=True Why are we saying enable data augmentation here? Doesn’t data augmentation starts at step 4?
- Use lr_find() to find highest learning rate where loss is still clearly improving
- Train last layer from precomputed activations for 1-2 epochs Does it always have to 1-2 epochs or we shall try more?
- Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
- Unfreeze all layers
- Set earlier layers to 3x-10x lower learning rate than next higher layer
- Use lr_find() again Do we create new learn object or find lr for learn which has already learnt a lot in step3, 4?
- Train full network with cycle_mult=2 until over-fitting
For point 7.
When I try with new learn object, lr curve is
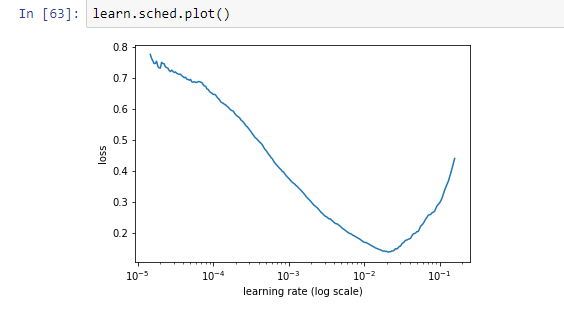
But when I try with learn object which has learnt in step3, 4.
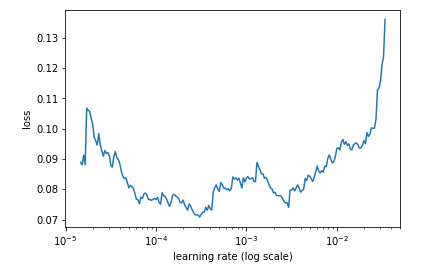
How do I depict and see I should change my lr?
3 Likes
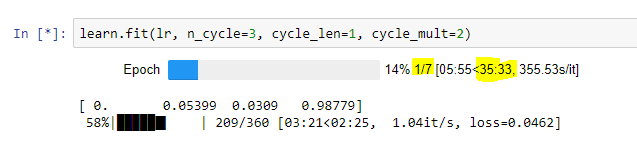
Fine tunning with differential learning rate:
Is it normal for p2.xlrge to take 40 minutes for 7 epochs?
1 Like