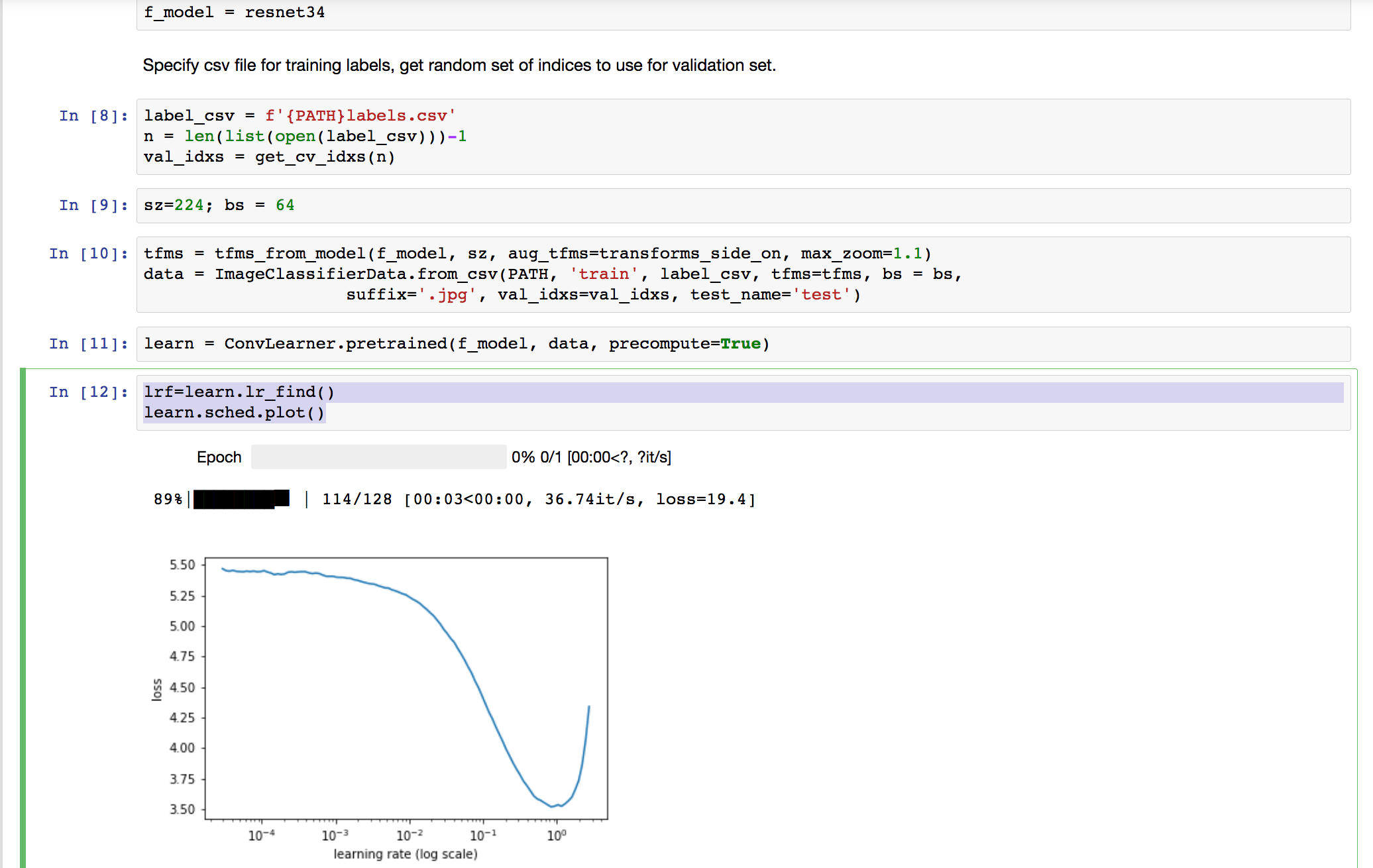
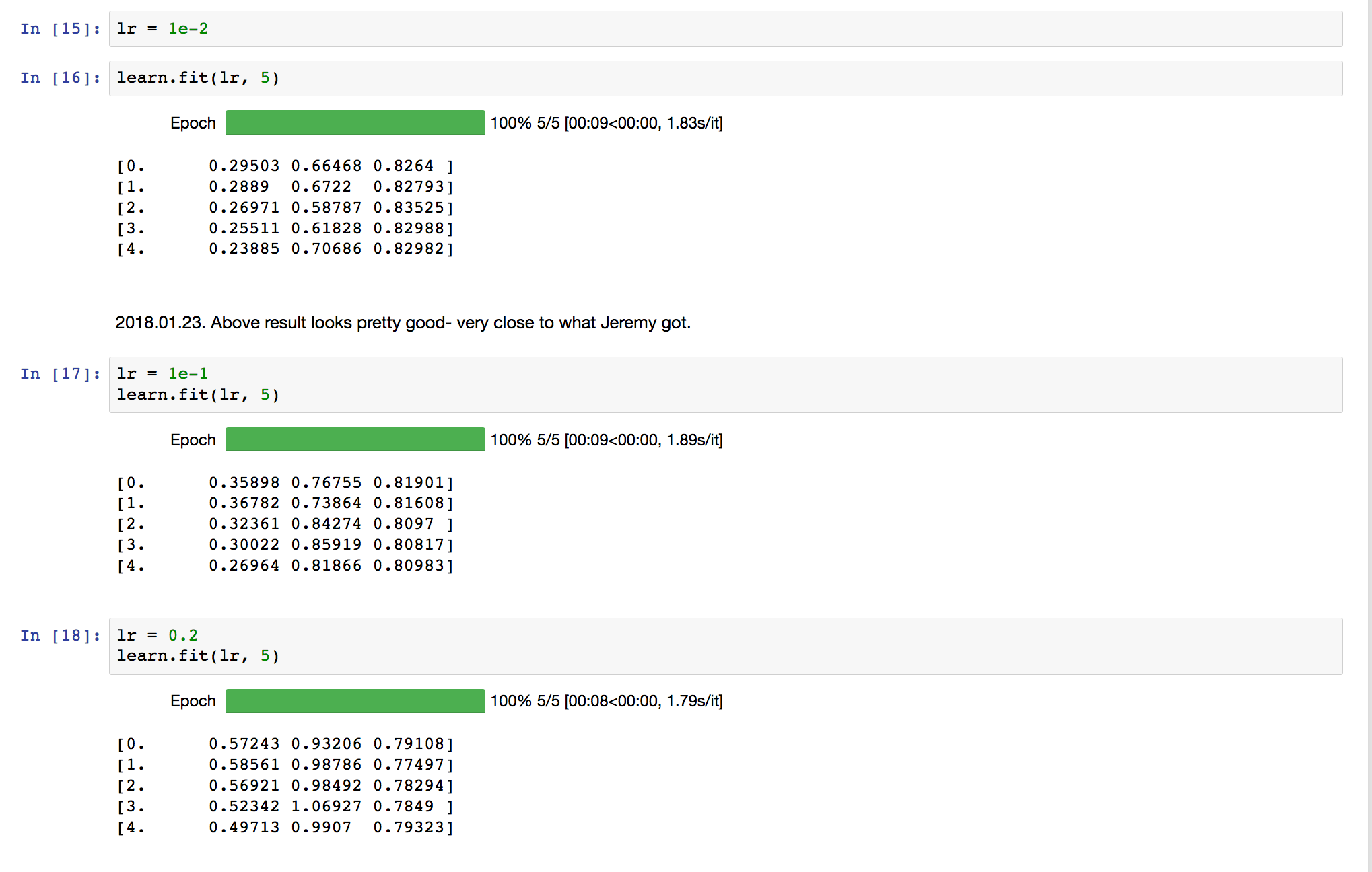
Hi. I was curious about learning rates for the dog breeds problem. I ran the learning rate finder and it looks like the steepest point in the curve is around 1e-1. My understanding is that we should pick a learning rate somewhere between the steepest point and the minimum. However, when I use 1e-2 (what Jeremy used) I get a result close to Jeremy’s. When I use 1e-1 it is slightly worse. Anyone have an explanation for this?
There’s generally not much point training more than a couple of epochs with precompute=True. Try unfreezing and setting precompute=False and see how that impacts your learning rate experiments.
Hello  Can you provide an explanation for the choice of the learning rate of 0.01 in the dog breed notebook? When I run the learning rate finder as suggested, it seems like a choice of 0.1 or 0.2 would be a good choice - so why the learning rate of 0.01?
Can you provide an explanation for the choice of the learning rate of 0.01 in the dog breed notebook? When I run the learning rate finder as suggested, it seems like a choice of 0.1 or 0.2 would be a good choice - so why the learning rate of 0.01?
Good learning rate is not a deterministic number. If you have a smaller learning rate, it will converge slowly…w = w - learning_rate * gradient. So smaller learning rate just means update in smaller increments. Jeremy has provided a good intuition for Learning rate via the finder and a rule of thumb (IMO) to help decide on learning rate. Choose the rate just before the steep fall in the Cost Function.
In most cases, I just choose a rate of 0.01 and it’s usually OK. This is not a big dataset, so it doesn’t take too long to run a Epoch. So experiment with a few different ranges like 0.001, 0.01, 0.1 and see what works for you and compare that with the results of the learning rate finder.
You will find that cyclical learning rate is much more powerful in jumping out of local minimas.
1 Like
Hello everyone!
After running through the Dog Breeds example, I have two questions:
- I tried a batch size of 64. It seems the model trained with a slower , compared to the chosen 58. Could I know if there is a way to estimate the right batch size by looking at the train/val error?
- I used get_data once, assigned ‘learn’ model and trained a few epochs. If I keep training by feeding more epochs subsequently, will it take more memory from my GPU?
- After increasing the image size to 299, I attempted to unfreeze my network and continue to fit, but immediately Out-of-memory occur?
Thanks for clarifying!
Thanks for the lesson! I went through the dog breeds competition exercise and was able to successfully submit a score on kaggle!
A gotcha that I had as a Windows user is that my csv submission was saved with line endings CRLF instead of LF which resulted in an error when uploading to kaggle:
ERROR: Unable to find 10357 require key values in the 'id' column
ERROR: Unable to find the required key value '000621fb3cbb32d8935728e48679680e' in the 'id' column
...
I followed Jeremy’s steps with some minor deviations (used a learning rate of 1e-1, didn’t use as many iterations) and got a score of 0.23567.
I noticed that used an additional method parameter ps=0.5 when creating the initial learner. What was the reason for this? (perhaps I missed it during the lecture video).
I also noticed that my training loss was a lot lower than my validation loss:
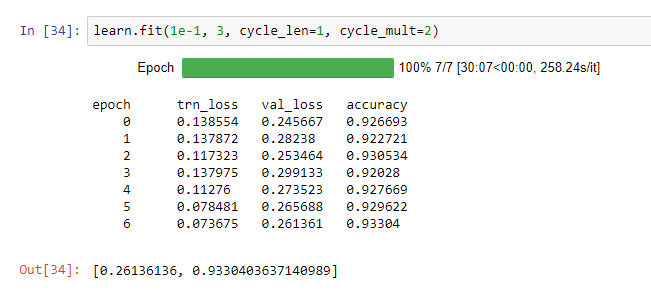
What would be the suggested approach to dealing with this?
Thanks!
For those interested in learning about learning the code underneath the hood of fastai.
I recommend starting with the pytorch 60 minute blitz then head over to Lesson_1 on pytorch.
Hey guys and @jeremy , I still struggle with the rationale behind starting to train and apply the model with precompute = True, then after that turn off precompute and train the net again with augs. After that process unfreeze the shallow layers and train it for another round.
My question is, why are we having a detour through precompute = True? Why not starting from scratch with creating augs, feeding it in a unfrozen net with precompute = False right away, when we have to do that either way? Is it only for saving time? Thanks for helping!
1 Like
Thanks for the explanation. Is it necessary to have precompute=True while saving weights ?
Precompute = True is a way to Fastrack computation. Once model is trained, either with or without it, you can save weights. Hope that helps!
1 Like
Thanks for your reply. I seem to be having a problem. Can you help me with it ? I’ve posted in on the forums.
What does the f' actually do in label_csv = f'{PATH}train_v2.csv'? I realize that it has to do with files and the {PATH} expansion, but what does it do exactly? Are there differences in python versions / platforms?
Hi, i have exactly the same problem\question.
did you figure out why LR=1e-2 is better in this case, despite the graph, which points to LR=1e-1 ?
It’s python3 shorthand… (f string’s)
Hi all! I hope this topic is the right place for my question: when we set precompute to ‘False’, should learning slow dramatically?
In my notebook, with precompute set to ‘True’, learn.fit takes 9 seconds. But when I set it to ‘False’, it slows to 3 minutes. Is this normal? I tried my original lesson1.ipynb and it’s the same. Lecture 2 video doesn’t display learning time so I can’t compare to Jeremy :).
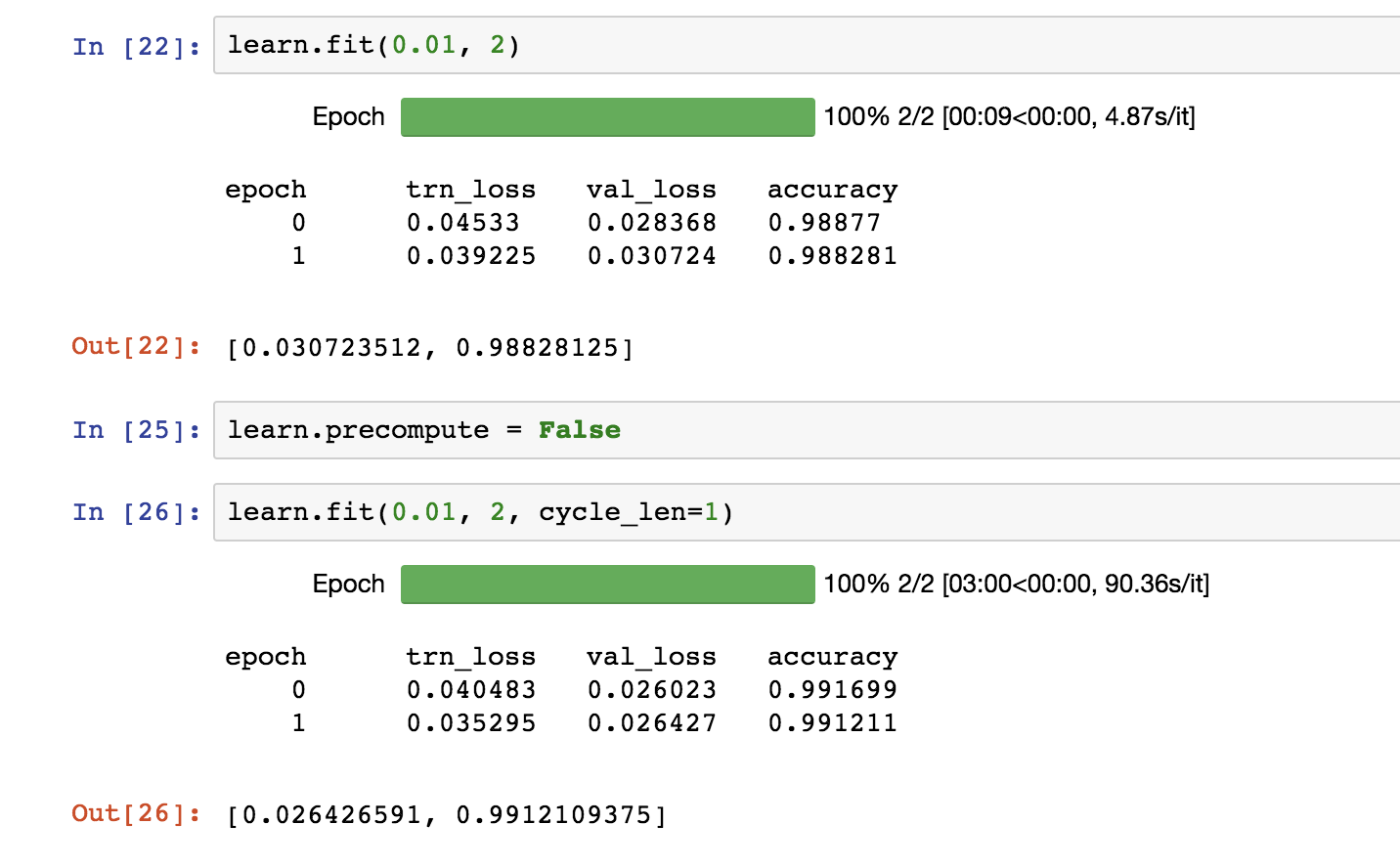
I figure that disabling precomputed activations would slow learning a bit, but I’m not sure if something is wrong since it is sooo much slower. Is anyone else’s acting the same way?
Thanks very much!
Britton
Yup that’s normal.
Hi Everyone,
I am doing the dog breeds competition. My accuracy is kinda stuck at 84% and whatever I do max I got is 86%. how are Jeremy and others getting 92%? did anyone else face the same issue? Am i missing something?
This is solved. For someone who might get stuck in the future here’s what i did:
- I was using resnet34. So I changed the arch model to resnext101_64. That was throwing an error.
- To solve this I went into fastai/fastai folder
- I downloaded the weights file from http://files.fast.ai/models/weights.tgz using
wget http://files.fast.ai/models/weights.tgz - I unzipped the file using
tar -xzvf weights.tgz
Then I used resnext101_64 in arch and it works great!
1 Like
Hi everybody,
Please see below:
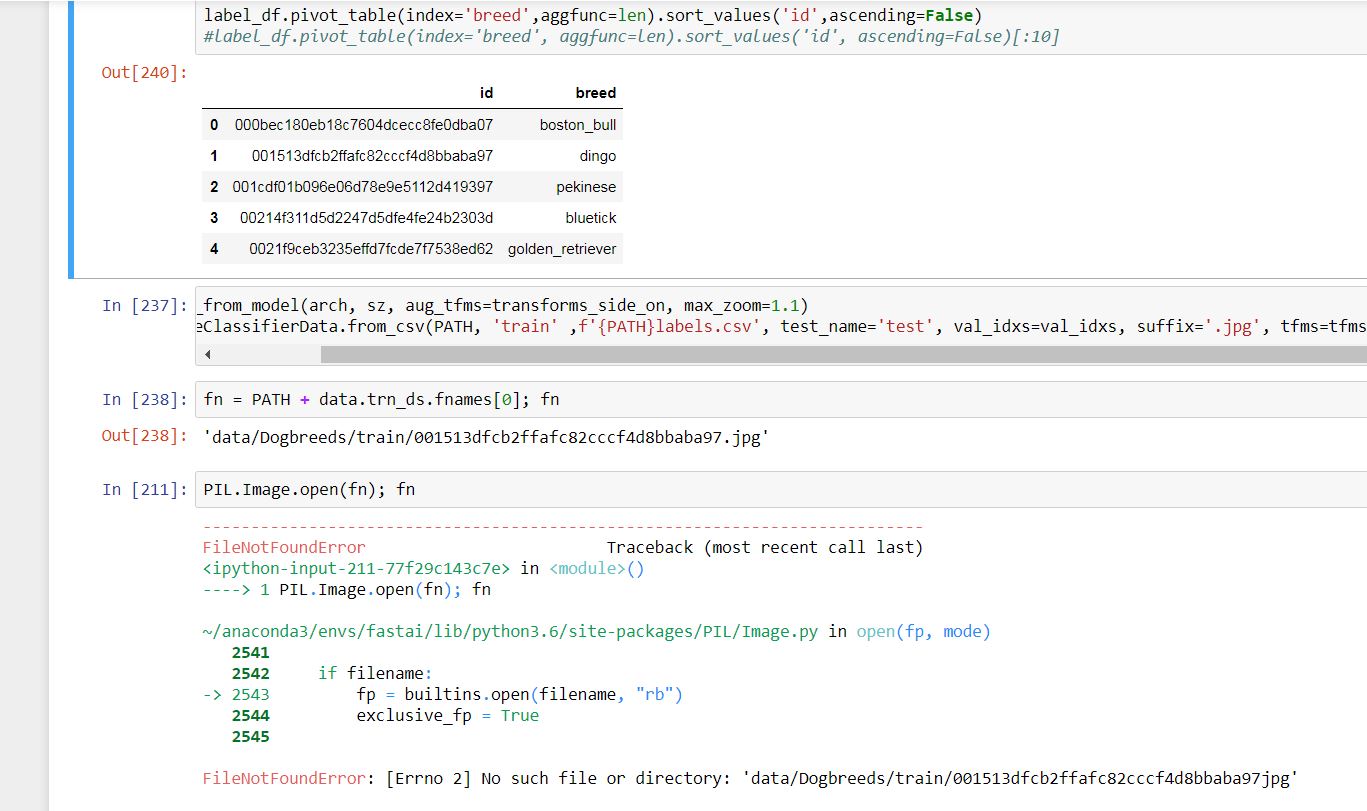
Instead of getting picture 000bec180eb18c7604dcecc8fe0dba07 .jpg as I correctly got in out[240] , I`m getting 001513dfcb2ffafc82cccf4d8bbaba97.jpg , which the next one .
Could you please tell me why is that?
Thank you
but then in that case, why not just run the different learning rates on separate models to avoid this ambiguity and to be able to know for sure that no learning rate is benefiting from preceding ones and to be able to properly judge which learning rate is for sure the best?
in other words, rerun all the batches at the same learning rate but multiple times for different learning rates and compare?