Cygwin alias
How can I create alias in Cywgin?
ssh ubuntu@34.229.220.175 -L8888:localhost:8888
You can do:
alias <your alias name>='ssh -i <path-to-aws-key> ubuntu@34.229.220.175 -L8888:localhost:8888'
Thanks! 
@jeremy, @yinterian does it make sense to create alias? Public IP on AWS changes every time I restarts my p2
I am getting this error when running lesson2 :
out of memory at /opt/conda/conda-bld/pytorch_1503965122592/work/torch/lib/THC/generic/THCStorage.cu:66
I checked on some blogs and found that it might be because batch size is too big, changed the bs to 24 but still get the same error.
How should i be resolving this?
Our default batch size is 64 and runs normally on AWS and crestle. are you running in locally or on cloud?
AWS p2.xlarge instance
Have you tried restarting kernel and rerunning code?
If you have saved weights, please skip learn.fit and load to avoid training time.
I restarted the instance and it is back to normal.
@vikbehal - If you want to have the same IP Address, you should look at “Elastic IP” inside “Network and Security” and associate that Elastic IP to your instance.
When creating Elastic IP, make sure you choose VPC when you select “Allocate New Address”. Once it’s created, do Actions -> Associate Address. That way you have the same IP Address. If your P2 instance is in a VPC (most likely if you use P2), the elastic IP would be associated even when instance is stopped.
Elastic IP has a cost of 1cent/hour for each hour the instance you have associated with the IP is NOT running.
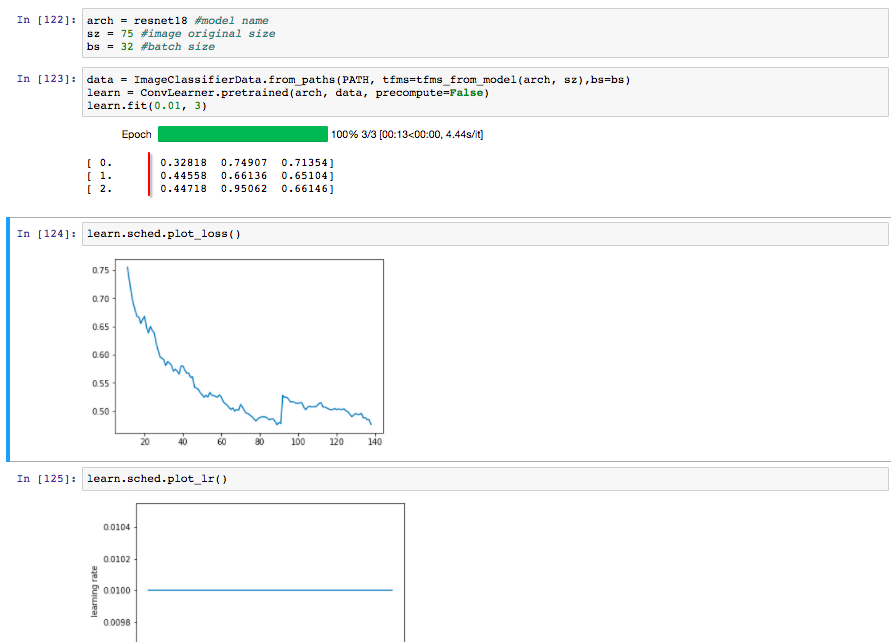
@jeremy With respect to the below image when I’m training with a single learning rate, where does the training loss after each epoch maps to the loss plot across iterations. Because I can see the loss after each epoch is lower that the lowest point in the loss graph
I’m not at all sure what’s happening in those graphs you show! I’ve never really plotted that with a constant learning rate - I suspect that somehow without cyclical learning rates it’s not being updated correctly. I’ll try to look into it…
Okay…but a more basic doubt is the training loss calculated after each epoch, is it the loss on the whole training data using the modified weights at the end of the epoch?
It’s the loss at the end of the epoch that are printed. (To be more technical: an exponentially weighted moving average of the last few iterations.)
Ah!!! Your question inspired me to study the code more closely, and I see that what’s being printed for the training loss is not quite correct. I’ve just pushed a fix - git pull and you should see that your chart makes more sense (hopefully!)
Thanks for the clarification and I’ll check the plot again and let you know
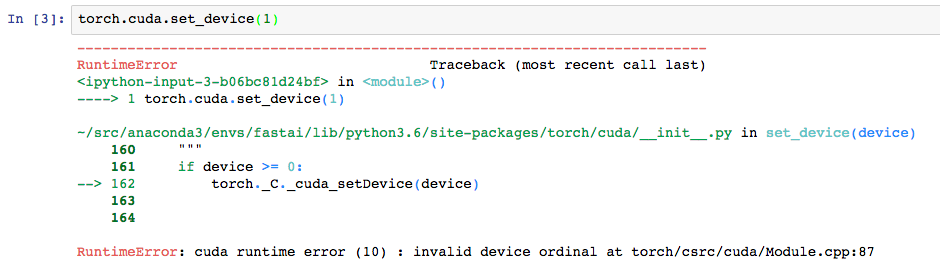
Try changing that from a 1 to a 0. I’m on my phone currently so I can’t tell you the command to check which gpu you want to use, but if you only have 1 gpu it will be 0 instead of 1.
Basically that is just telling Cuda which gpu to use.
Can you provide more context? Which Notebook is this? Are you running it in GPU? What machine G2 / P2?
Sorry I shouldn’t have left that in the notebook - it’s used to select a different GPU if you have multiple GPUs. Since you have just one GPU, you should remove that line.
Ok. Thank you.