hi @jeremy ,
I’m working on the neural-sr.ipynb, I noticed that this code is using the trn_resized_72_r.bc and trn_resized_288_r.bc dataset, but in the files.fast.ai/data, I can only find the trn_resized_72.bc and trn_resized_288.bc, I think they are different from those with “_r” tails right?
The reason I think they are different is that when I tried to replace the trn_resized_72_r.bc and trn_resized_288_r.bc with trn_resized_72.bc and trn_resized_288.bc in the neural-sr.ipynb, the code raised an error:
ValueError: batch_size needs to be a multiple of X.chunklen
Then I check the X.chunklen:
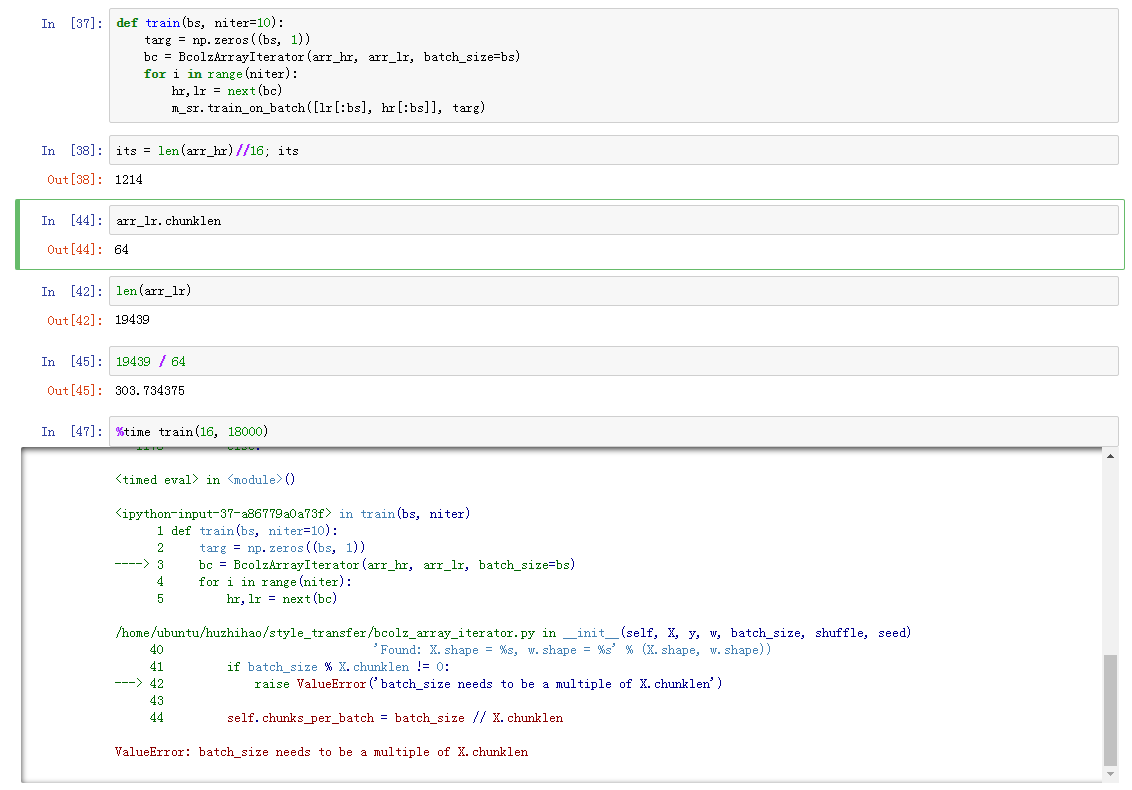
The arr_lr.chunklen is 64, in other words, it seems I have to change the batch_size in train(), so that solving this error. So I change the batch_size as 64, train(64, 18000), but I got “Resource Exhausted”, my GTX 1080Ti ran out of memory!
Therefore I’m wondering your original arr_lr.chunklen is just 16, not 64, right?
Which data set are you actually using? Where I can download it ?
Thanks jeremy.
EDIT:
Jeremy had released the “imagenet-sample-train” dataset, I think I can use these sample dataset to do the resize job, so I re-implement the imagenet_process.ipynb with “imagenet-sample-train” dataset, there are 19439 images in it, resizing them as 288 x 288 for high-resoluton and 72 x 72 for low-resolution, got pretty good effect.
My cpu is i7-6850K, the processing time is:
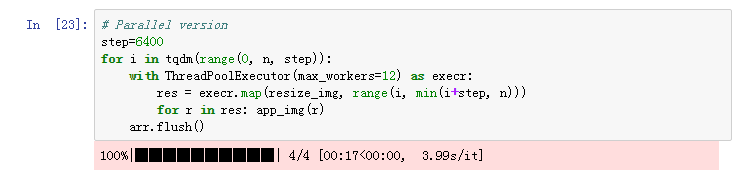
pretty fast ! And the size of “trn_resized_72_r.bc” is 342 MB, the size of “trn_resized_288_r.bc” is 5.0 GB.
I think maybe I can use these dataset for super-resolution training!
But i still don’t figure out are you using the whole imagenet dataset to create the high-res and low-res dataset? The whole imagenet data is about 134GB! That’s huge file, maybe the resized .bc file will get to 500GB or more! @jeremy






{kind=link}