this means lr started increasing and there is no reason to continue testing (increase lr anymore).
Not sure if you already resolved it but just try this in paperspace:
import cv2
from fastai.transforms import *
from fastai.conv_learner import *
So, after running some notebooks on AWS instances, I thought of trying out Paperspace to see if I’d get speedups. Ran into this issue as well. I have a feeling that it has to do with load order and dependencies, kinda tricky to figure out when import * going on.
Curious if anyone else has run into this issue and might have fixed it ? ping @sermakarevich @abdulhannanali @jeremy
Edit: There’s existing threads around this discussion. Just ran into them and adding links here, for future ref:
1 Like
I am no longer using Paperspace, but try the suggested solution by @Deb above, but since @jeremy removed the dependency on cv2, have you tried git pull and ran the notebook again. Another option can be to do a scratch installation on their Ubuntu 16.04 image, it doesn’t have the bloat of a loaded desktop environment too, and you can use 16.04 version this way. You’ll only be able to SSH in the ubuntu image though 
Yup as of yesterday (with latest git pull) I still see the issue if I don’t import torch, cv2 ahead of everything else in paperspace. I’m able to proceed with the import. So, not a major issue for me.
I was revisiting Lecture 1 wherein I realized Jeremy’s approach to writing code. I missed it at that time (probably was on the forum at the moment). But his take is interesting.
His coding style is compact and uses names that are shortish. Reasoning being:
- When code is compact, you can see everything that is happening, in 1 line or within a small region
- Shorter variable names are a middle ground between what mathematicians use (single letters) and software engineers use (longer variable names)
He makes a distinction between interactive data science and software engineering. Those who are into the fastai codebase may find these 3 minutes and this insightful.
2 Likes
Thanks for noticing
I’ve re-recorded the lesson 1 video to make it shorter, and to show how to use both Crestle and Paperspace. The new version is in the top post, or use this link: https://youtu.be/IPBSB1HLNLo
2 Likes
I’m using Ubuntu 16 GPU+ (NVIDIA QUADRO M4000) from paperspace. It takes me 26sec/it just to run these code. So it end up 2hrs 45 minutes to run everything. Am I setting up the environment correctly?
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 3)
14%|█▍ | 51/360 [21:35<2:10:49, 25.40s/it]
I’m having the same problem on paperspace. I set the machine up using curl http://files.fast.ai/setup/paperspace | bash.
Hi all,
I followed the instructions in the video for Paperspace, but was unable to access the Jupyter Notebook externally (I used Ubuntu 16, West Coast, GPU). I tried assigning a static public IP address and configuring Jupyter to serve requests coming from any IP address, but that didn’t work either. I’ve also contacted Paperspace support.
Any ideas?
Thanks,
Rick
Hi Rick
Did you use http://files.fast.ai/setup/paperspace to set it up? Perhaps the firewall isn’t configured to allow 8888?
sudo ufw allow 8888:8898/tcp
2 Likes
No, that sounds like it’s not using the GPU. Someone else mentioned they had to conda remove and reinstall pytorch after rebooting.
Feeling pretty good about lesson 1. Here is recap about what I did.
- Finished watching the lesson
- Set up my environment (script crashed when installing anaconda but I was able to hack at it till it worked)
- Made my own breakfast dataset (frenchtoast, pancakes, and waffles)
- Tried to re-create notebook from memory to make an image classifier for my breakfast dataset. I ended up copying a lot of the lesson’s code but I typed it myself. Copying by typing out the code was where I learned most during the lesson.
- Found a useful forum post about multi class probabilities and a new class for visualize image model results.
Here are links:
breakfast ipynb. Pictures at the end are pretty interesting. I really surprised that some of the pancakes were not classified correctly. I was also unable to get the Cyclical Learning Rates to work. I think this might be because of a lack of images (50 train, 50 validation of each category) - but any advice here is appreciated.
4 Likes
20 images will be sufficient for validation?
(20% of the data)
Also if you have downloaded the images manually, then there’s a helper script in GitHub to automate the job…
google image downloader was the repository name if I am correct…
In case anyone else hit this error:
- Error:
libSM.so.6: cannot open shared object file: No such file or directory- Solution:
sudo apt-get install -y python-qt4
- Solution:
2 Likes
So you having the same problem as me? Not able to use GPU?
Aye I did but I stepped through the http://files.fast.ai/setup/paperspace script and re-installed a bunch of stuff… something fixed it but not sure exactly what sorry
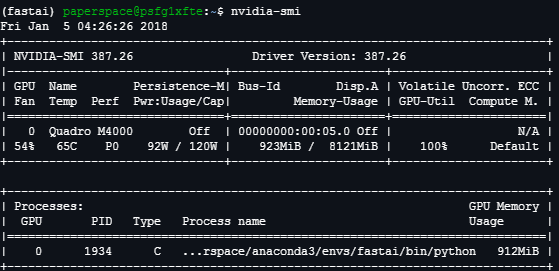
Ok. manage to solve the GPU not used in pytorch. I install back the cuda driver since I can’t initiate nvidia-smi command in the terminal. not sure why the first bash command doesn’t install it.
100%|██████████| 360/360 [01:29<00:00, 4.02it/s]
100%|██████████| 32/32 [00:07<00:00, 4.03it/s]
Epoch
100% 3/3 [00:14<00:00, 4.80s/it]
[ 0. 0.05418 0.02841 0.98779]
[ 1. 0.05212 0.02917 0.9873 ]
[ 2. 0.03798 0.02918 0.98926]
However 4it/s it’s a bit slow i guess. When query my NVIDA M4000 stats it show that 923MB/8121MB GPU memory usage. Am I not optimize the GPU?