Thanks @nzhang, it didn’t occur to me to lookup the function definition. Great idea.
It looks like the function doesn’t do what i expect, but I found out via lesson 2 the shortcomings.
Thanks @nzhang, it didn’t occur to me to lookup the function definition. Great idea.
It looks like the function doesn’t do what i expect, but I found out via lesson 2 the shortcomings.
Hi!
I’m new here and after reading Jeremy’s solution a question popped up in my mind.
I can see that, in the solutions notebook, he randomly selects 2k examples from the training sets, moves them into the validation folder and then splits them between valid/cats and valid/dogs.
This means that the number of validation dogs will probably be different than the number of validation cats. Is there any reason to prefer this rather than choosing the same number of validation cats and dogs (1k cats and 1k dogs)?
What is the most correct way to split the dataset? Is there any practical difference? Thanks.
I believe in the validation data provided from hist download url, there are equal number of cats and dogs.
Which I think it’s better than polarized over 1 category.
Why does this code say it has found 16 images belonging to 3 classes and 8 images belonging to 3 class instead of 2 classes? I used images from the train folder provided by kaggle.
vgg = Vgg16()
# Grab a few images at a time for training and validation.
# NB: They must be in subdirectories named based on their category
batches = vgg.get_batches(path+‘train’, batch_size=batch_size)
val_batches = vgg.get_batches(path+‘valid’, batch_size=batch_size*2)
vgg.finetune(batches)
vgg.fit(batches, val_batches, nb_epoch=1)
Check the directories under your path, you may have 3 sub-directories under train/valid.
No I have 2 sub-directories under train/valid. I made a copy of lesson1.ipyn and but it in CvD_re and the path is “data/sample/”
Could you check your current directory? Use
%pwd
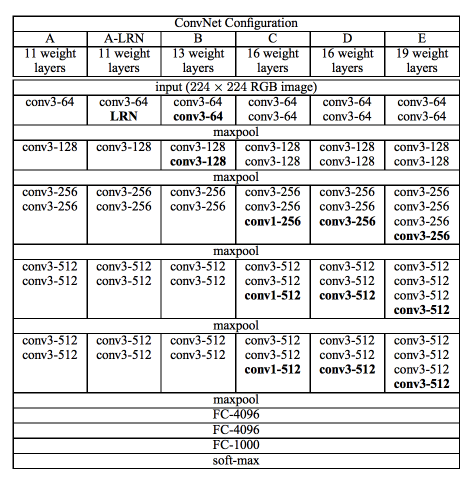
16 is just the number of layers with weights (those that can be trained) in the model. I found this diagram as below - seems there were couple of models trained, with slightly different convolutional parts.
I navigated to CvD_re/data/sample/valid and used pwd, since %pwd didn’t work, and got /home/ubuntu/nbs/CvD_re/data/sample/valid
Try this in your notebook, it’ll show the path the code is using:
import os
os.path.abspath(path+‘train’)
os.path.abspath(path+‘valid’)
Also, I noted that in the code you pasted (re-pasted below), the single quote seems in unicode, you may want to replace them with normal quotes. Not sure it’s the problem, but I can’t run the above code with your quotes.
batches = vgg.get_batches(path+‘train’, batch_size=batch_size)
val_batches = vgg.get_batches(path+‘valid’, batch_size=batch_size*2)
I wasn’t able to run
import os
os.path.abspath(path+‘train’)
os.path.abspath(path+‘valid’)
I had to change ’ (single quote) to " (double quotes) but the rest of the code provided from lesson1.ipynb works fine with ’ (single quotes). Anyway the output was just
‘/home/ubuntu/nbs/CvD_re/data/sample/valid’
Then I am not sure what’s wrong there, maybe start from fresh?
I deleted all the files in CvD_re and downloaded lesson1.ipynb, vgg16.py, vgg16bn, and utils.py. I also made new folders for the data and now it shows 2 classes instead of 3!
Great!
Hi,
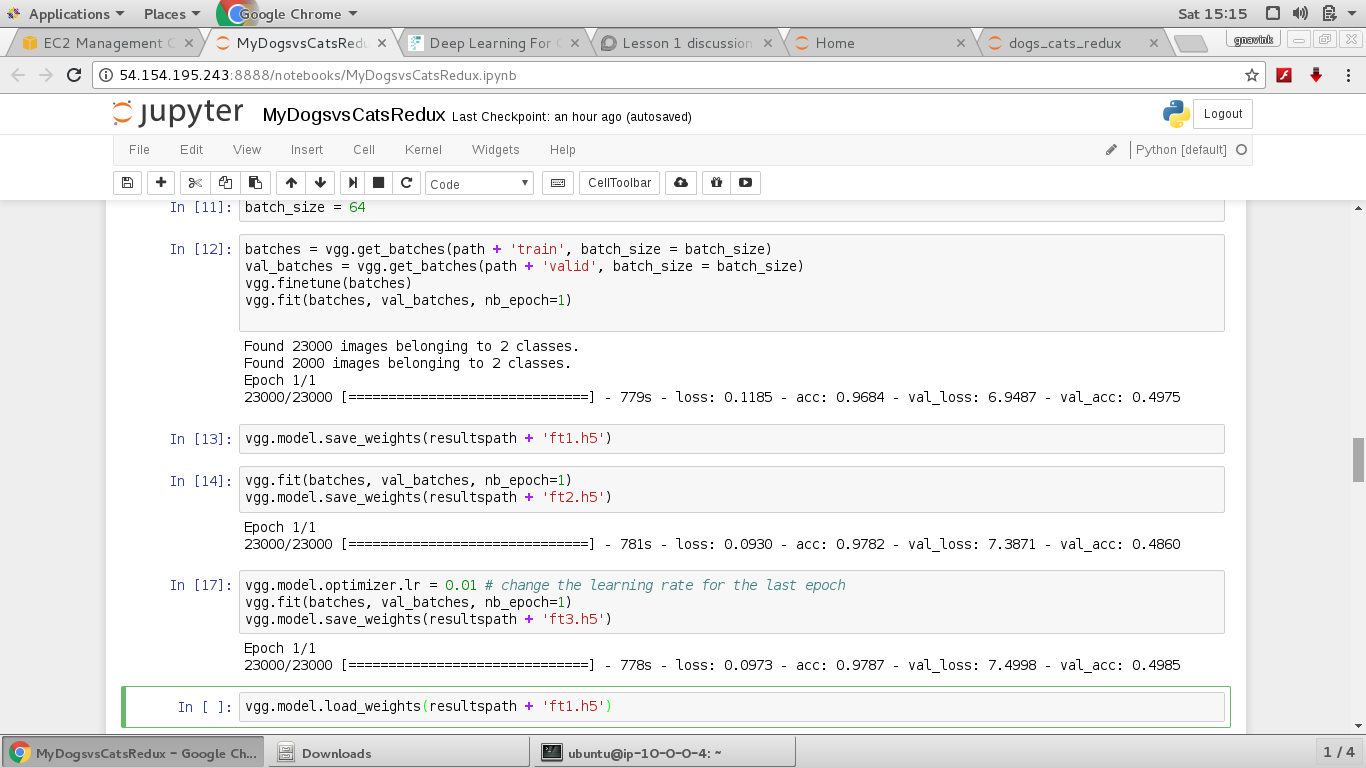
Trying the Dogs vs Cats Redux on p2 instance.
I am getting poor validation accuracy after 1 epoch of training… Trained for 2 more epochs.
On the 3rd epoch training set the learning rate to be 0.01. The validation accuracy goes down but the training accuracy gets better…
Uploading the snapshot of accuracy.
No. of training samples : 23000
No. of validation samples :2000
batch_size = 64
I also found the below samples mislabelled. Is it a mistake from Kaggle data…
1)dogs/dog.1694.jpg
2)dogs/dog.11890.jpg
3)cats/cat.6443.jpg
4) cats/cat.11758.jpg
5)dogs/dog.1832.jpg
Does it have any effect on the validation accuracy?
thanks
-navin
I have used AWS P2 spot instance. Followed the fast.ai Wiki for setting up spot instances…
Used the EU-Ireland Region AMI given by FastAI.
Not sure why the validation accuracy is pegged around 50%
The val_acc usually gets to 0.98 at first epoch, looks like your data is messed up.
I had the same problem. I ran sudo apt-get update and then reran sudo apt-get install git, git installed successfully.
Hi, I met the same issue.
Would you please explain your method in more details? Thanks
thanks nzhang. Yes, the validation data & validation labels were messed up.
I had made a mistake in re-arranging the data for the validation folder
The culprit was in :
g = glob(’*.jpg’)
shuf = np.random.permutation(g)
for i in range(2000):
os.rename(g[i], ‘…/valid/’ + shuf[i])
The highlighted line should be as:
g = glob(’*.jpg’)
shuf = np.random.permutation(g)
for i in range(2000):
os.rename(shuf[i], ‘…/valid/’ + shuf[i])
The error which I had made happens to generate wrong labels…
For eg: if g[i] = cat1.jpg and shuf[i] = dog10.jpg
the wrongly coded line would rename cat1.jpg as valid/dog10.jpg
This would make the dog10.jpg ( which is actually cat) to be wrongly placed in the dog folder while creating cats & dogs folder in the validation directory, thus making get_batches() generate wrong labels…
This results in poor validation accuracy …
After code correction, my validation accuracy jumped to 98.5%
Now, I understand why jeremy & rachel emphasize to write your version of notebooks…
thanks
-navin